Cơ hội mới nổi về tiền điện tử: Tập trung vào tiền thay thế và airdrop
Thị trường tăng giá tiền điện tử hiện tại mang đến những cơ hội đáng chú ý về tiền thay thế và airdrop, với nhiều nền tảng khác nhau mang lại tiềm năng lợi nhuận đáng kể.
 Kikyo
Kikyo

Nguồn: AI Faner
xAI hôm nay đã phát hành thế hệ mới của mô hình ngôn ngữ lớn Grok-3 và phiên bản đơn giản hóa Grok-3 mini. Các bài kiểm tra chuẩn mới nhất cho thấy Grok-3 thể hiện những lợi thế đáng kể khi so sánh trực tiếp với DeepSeek.
Trong bài kiểm tra năng lực toán học (AIME'24), Grok-3 đạt 52 điểm, cao hơn đáng kể so với 39 điểm của DeepSeek-V3. Về đánh giá kiến thức khoa học (GPQA), Grok-3 dẫn đầu với số điểm là 75, trong khi DeepSeek-V3 đạt 65 điểm. Trong bài kiểm tra khả năng lập trình (LCB tháng 10-tháng 2), Grok-3 cũng vượt qua DeepSeek-V3 với 57 điểm so với 36 điểm.

Trong bài kiểm tra hiệu năng AIME 2025 mới nhất, phiên bản Grok-3 Reasoning Beta đã đạt được số điểm tuyệt vời là 93 điểm ở điểm tổng hợp của thời gian suy luận và tính toán, phiên bản tinh gọn Grok-3 mini cũng đạt 90 điểm. Trong khi đó, DeepSeek-R1 đạt 75 điểm, trong khi Gemini-2 Flash Thinking chỉ đạt 54 điểm. Kết quả này càng làm nổi bật những ưu điểm vượt trội của Grok-3 trong suy luận toán học phức tạp và hiệu quả tính toán.
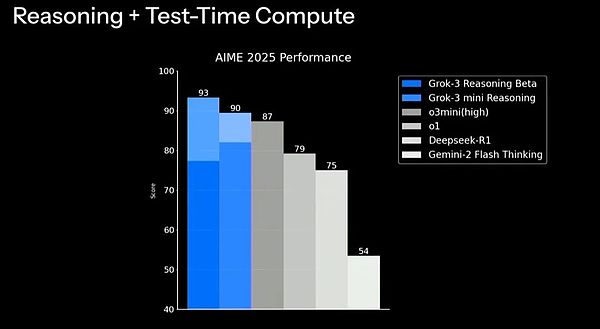
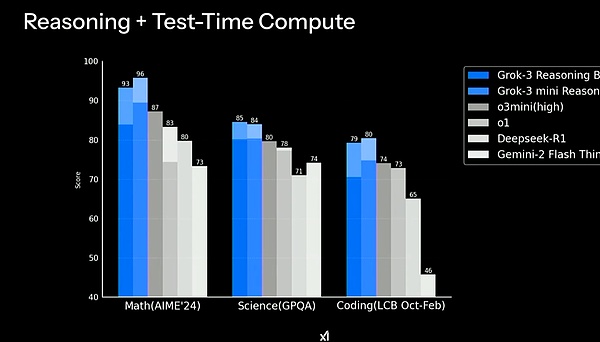
Điều đáng chú ý là DeepSeek-R1, mới được DeepSeek phát hành gần đây, cũng không vượt qua được Grok-3 trong các bài kiểm tra khả năng suy luận khác. Trong suy luận toán học, Grok-3 đạt 93 điểm và DeepSeek-R1 đạt 73 điểm; trong suy luận khoa học, Grok-3 đạt 85 điểm và DeepSeek-R1 đạt 74 điểm; trong suy luận lập trình, Grok-3 đạt 79 điểm, trong khi DeepSeek-R1 đạt 65 điểm.
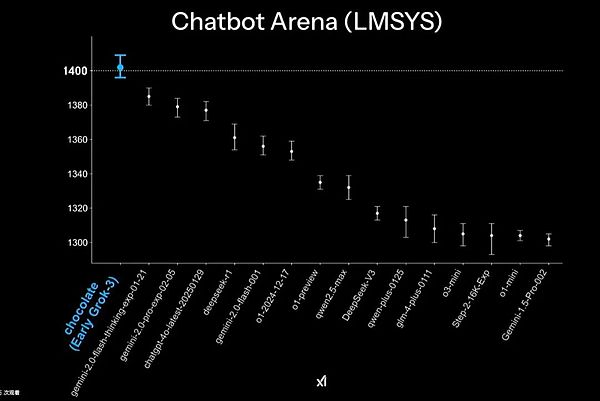
Ngoài ra, trong đánh giá về đấu trường chatbot LMSYS, Grok-3 đạt khoảng 1.400 điểm, không chỉ vượt qua dòng DeepSeek mà còn vượt trội hơn các mô hình lớn phổ biến khác, bao gồm GPT-4, Claude, v.v.
Những dữ liệu này cho thấy mặc dù DeepSeek đã cho thấy đà phát triển mạnh mẽ trong vài tháng qua, nhưng hiệu suất tổng thể của Grok-3 vẫn duy trì vị trí dẫn đầu. Đặc biệt, những ưu điểm về mặt suy luận toán học và hiệu quả tính toán rõ ràng hơn, không chỉ phản ánh thế mạnh về mặt kỹ thuật của xAI trong nghiên cứu và phát triển mô hình mà còn cho thấy sự cạnh tranh khốc liệt trong lĩnh vực AI.
Thị trường tăng giá tiền điện tử hiện tại mang đến những cơ hội đáng chú ý về tiền thay thế và airdrop, với nhiều nền tảng khác nhau mang lại tiềm năng lợi nhuận đáng kể.
Kikyo24karat có kế hoạch bán NFT thông qua 1000 máy bán hàng tự động AIICO trên toàn quốc, nhằm thu hút hơn 100 triệu người dùng hàng tháng bằng nội dung cao cấp. Sáng kiến này tìm cách dân chủ hóa quyền truy cập NFT, sử dụng chuỗi khối Flow và các vị trí chiến lược để thúc đẩy việc áp dụng rộng rãi hơn và tăng trưởng thị trường.
 Joy
JoyArgentina chính thức cho phép Bitcoin tham gia các hợp đồng pháp lý trong bối cảnh lạm phát cao, có khả năng mở đường cho việc áp dụng tiền điện tử rộng rãi hơn.
 Alex
AlexTrung Quốc đưa ra các quy định nghiêm ngặt đối với trò chơi trực tuyến, tập trung vào ví CBDC và chi tiêu trong trò chơi, khiến cổ phiếu công nghệ giảm mạnh.
KikyoSolana Saga phải đối mặt với việc hủy đơn hàng và các vấn đề về nguồn cung trong bối cảnh nhu cầu tăng cao do việc đưa vào token BONK.
AlexHồng Kông giới thiệu các quy định về quỹ ETF tiền điện tử, khẳng định mình là quốc gia dẫn đầu trong bối cảnh đầu tư tiền điện tử được quản lý ở châu Á.
KikyoNgười sáng lập Dogecoin chỉ trích Chủ tịch SEC Gensler vì các hành động quản lý không hiệu quả và nêu ra các vấn đề rộng hơn về việc không tuân thủ trong không gian tài sản kỹ thuật số.
AlexPaxos nhận được sự chấp thuận theo quy định để triển khai USDP trên Solana, mở rộng ra ngoài Ethereum.
KikyoKhám phá những người chơi và giao dịch chính đằng sau sự tăng giá bất ngờ của ARB.
AlexRipple chiến thắng trước SEC, khẳng định vị thế của XRP là một quy định không bảo mật và định hình lại quy định về tiền điện tử.
Kikyo