Cảnh báo sai: Sai lầm của Cointelegraph về iShares Bitcoin Spot ETF đã bơm giá Bitcoin lên 30K
Cointelegraph đã tweet rằng SEC đã phê duyệt quỹ ETF giao ngay Bitcoin (BTC) của iShares, nhưng đã được BlackRock xác nhận là sai.
 Aaron
Aaron

Tác giả: Tô Dương, Hào Bá Dương; Nguồn: Công nghệ Tencent
Là "người bán xẻng" trong thời đại AI, Hoàng Nhân Huân và NVIDIA của ông luôn tin rằng sức mạnh điện toán không bao giờ ngủ.
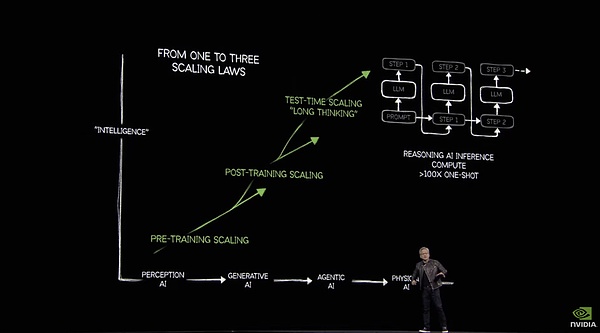
Trong bài phát biểu tại GTC, Huang Renxun cho biết suy luận đã làm tăng nhu cầu về sức mạnh tính toán lên 100 lần
Tại hội nghị GTC hôm nay, Huang Renxun đã giới thiệu GPU Blackwell Ultra mới, cũng như các SKU máy chủ bắt nguồn từ GPU này để suy luận và Agent, bao gồm cả nhóm RTX dựa trên kiến trúc Blackwell. Tất cả những điều này đều liên quan đến sức mạnh tính toán, nhưng điều quan trọng hơn tiếp theo là làm thế nào để sử dụng sức mạnh tính toán vô tận một cách hợp lý và hiệu quả.
Trong mắt Huang Renxun, con đường đến AGI đòi hỏi sức mạnh tính toán, robot thông minh có thân xác đòi hỏi sức mạnh tính toán, và việc xây dựng Omniverse và các mô hình thế giới đòi hỏi sức mạnh tính toán thậm chí còn lớn hơn nữa. Về việc con người cuối cùng cần bao nhiêu sức mạnh tính toán để xây dựng một "vũ trụ song song" ảo, Nvidia đã đưa ra câu trả lời - gấp 100 lần so với trước đây.
Để chứng minh cho quan điểm của mình, Huang Renxun đã trình bày một bộ dữ liệu tại trang web GTC - vào năm 2024, bốn nhà máy điện toán đám mây hàng đầu tại Hoa Kỳ sẽ mua tổng cộng 1,3 triệu chip kiến trúc Hopper. Đến năm 2025, con số này sẽ tăng vọt lên 3,6 triệu GPU Blackwell.
Sau đây là một số điểm chính của hội nghị GTC 2025 của NVIDIA do Tencent Technology biên soạn:
NVIDIA đã phát hành kiến trúc Blackwell và ra mắt chip GB200 tại GTC vào năm ngoái. Tên chính thức của năm nay đã được điều chỉnh một chút. Nó không còn được gọi là GB300 như tin đồn trước đó nữa mà được gọi trực tiếp là Blakwell Ultra.
Nhưng xét về mặt phần cứng, bộ nhớ HBM mới đã được thay thế dựa trên bộ nhớ của năm ngoái. Nói một cách ngắn gọn, Blackwell Ultra = phiên bản Blackwell có bộ nhớ lớn.
Blackwell Ultra được cấu thành từ hai quy trình TSMC N4P (5nm), chip kiến trúc Blackwell + gói CPU Grace và được trang bị bộ nhớ HBM3e xếp chồng 12 lớp tiên tiến hơn. Bộ nhớ video được tăng lên 288GB. Giống như thế hệ trước, nó hỗ trợ NVLink thế hệ thứ năm và có thể đạt được băng thông kết nối liên chip 1,8TB/giây.

Các thông số hiệu suất NVLink của các thế hệ trước
Dựa trên nâng cấp lưu trữ, sức mạnh tính toán chính xác FP4 của GPU Blackwell có thể đạt tới 15PetaFLOPS và tốc độ suy luận dựa trên cơ chế Attention Acceleration nhanh hơn 2,5 lần so với chip kiến trúc Hopper.

Hình ảnh chính thức của Blackwell Ultra NVL72
Giống như GB200 NVL72, NVIDIA cũng đã ra mắt một sản phẩm tương tự trong năm nay, tủ Blackwell Ultra NVL72, bao gồm tổng cộng 18 khay máy tính, mỗi khay chứa 4 GPU Blackwell Ultra + 2 CPU Grace, tổng cộng 72 GPU Blackwell Ultra + 36 CPU Grace, bộ nhớ video 20TB, tổng băng thông 576TB/giây, cộng với 9 khay chuyển mạch NVLink (18 NVLink chip chuyển mạch), băng thông NVLink giữa các nút là 130TB/giây.
Tủ có 72 card mạng CX-8 tích hợp, cung cấp băng thông 14,4TB/giây. Card Ethernet Quantum-X800 InfiniBand và Spectrum-X 800G có thể giảm độ trễ và độ nhiễu, đồng thời hỗ trợ các cụm AI quy mô lớn. Ngoài ra, giá đỡ còn tích hợp 18 BlueField-3 DPU để tăng cường mạng lưới đa thuê bao, bảo mật và tăng tốc dữ liệu.
NVIDIA cho biết sản phẩm này được tùy chỉnh đặc biệt "cho kỷ nguyên lý luận AI". Các kịch bản ứng dụng bao gồm lý luận AI, Agent và AI vật lý (mô phỏng và tổng hợp dữ liệu cho robot và đào tạo lái xe thông minh). So với sản phẩm thế hệ trước GB200 NVL72, hiệu suất AI đã được cải thiện 1,5 lần. So với sản phẩm tủ DGX có cùng định vị kiến trúc Hopper, nó có thể cung cấp cho các trung tâm dữ liệu cơ hội tăng doanh thu gấp 50 lần.
Theo thông tin chính thức, lý luận của 671 tỷ tham số DeepSeek-R1 có thể đạt 100 token mỗi giây dựa trên sản phẩm H100, trong khi sử dụng giải pháp Blackwell Ultra NVL72, nó có thể đạt 1000 token mỗi giây.
Chuyển đổi theo thời gian, đối với cùng một nhiệm vụ lý luận, H100 cần chạy trong 1,5 phút, trong khi Blackwell Ultra NVL72 có thể hoàn thành trong 15 giây.
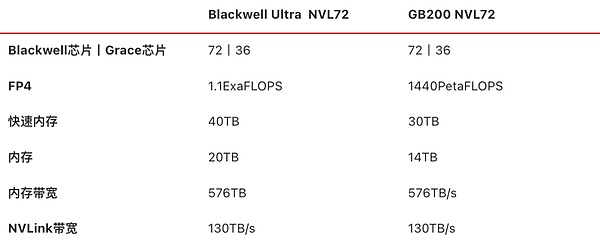
Thông số phần cứng Blackwell Ultra NVL72 và GB200 NVL72
Theo thông tin do NVIDIA cung cấp, các sản phẩm liên quan đến Blackwell NVL72 dự kiến sẽ có mặt vào nửa cuối năm 2025. Khách hàng bao gồm các nhà sản xuất máy chủ, nhà máy điện toán đám mây và nhà cung cấp dịch vụ cho thuê năng lượng điện toán:
Các nhà sản xuất máy chủ
15 nhà sản xuất bao gồm Cisco/Dell/HPE/Lenovo/Supermicro
Nhà máy điện toán đám mây
Các nền tảng chính thống như AWS/Google Cloud/Azure/Oracle Cloud
Các nhà cung cấp dịch vụ cho thuê điện toán
CoreWeave/Lambda/Yotta, v.v.
Theo lộ trình của NVIDIA, sân nhà của GTC2025 sẽ là Blackwell Ultra.
Tuy nhiên, Huang Renxun cũng nhân cơ hội này để xem trước GPU thế hệ tiếp theo dựa trên kiến trúc Rubin sẽ ra mắt vào năm 2026 và tủ Vera Rubin NVL144 mạnh mẽ hơn - 72 CPU Vera + 144 GPU Rubin, sử dụng chip HBM4 với bộ nhớ video 288GB, băng thông bộ nhớ video 13TB/giây và được trang bị card mạng NVLink và CX9 thế hệ thứ sáu.
Sản phẩm này mạnh mẽ như thế nào? Sức mạnh tính toán suy luận với độ chính xác FP4 đạt 3,6ExaFLOPS và sức mạnh tính toán đào tạo với độ chính xác FP8 đạt 1,2ExaFlOPS, gấp 3,3 lần hiệu suất của Blackwell Ultra NVL72.
Nếu bạn nghĩ là chưa đủ, thì không sao cả. Vào năm 2027, sẽ có một tủ Rubin Ultra NVL576 mạnh mẽ hơn, với khả năng suy luận chính xác FP4 và khả năng tính toán đào tạo chính xác FP8 lần lượt là 15ExaFLOPS và 5ExaFLOPS, gấp 14 lần so với Blackwell Ultra NVL72.

Thông số của Rubin Ultra NVL144 và Rubin Ultra NVL576 do NVIDIA cung cấp chính thức
Đối với những khách hàng có nhu cầu không thể được đáp ứng bởi Blackwell Ultra NVL72 ở giai đoạn này và không cần xây dựng các cụm AI quy mô cực lớn, giải pháp của NVIDIA là nhà máy siêu máy tính AI DGX Super POD cắm và chạy dựa trên Blackwell Ultra.
Là một nhà máy siêu máy tính AI cắm và chạy, DGX Super POD chủ yếu được thiết kế cho các tình huống AI như AI tạo sinh, AI Agent và mô phỏng vật lý, bao gồm toàn bộ nhu cầu mở rộng sức mạnh tính toán quy trình từ trước khi đào tạo, sau khi đào tạo đến môi trường sản xuất. Equinix, là nhà cung cấp dịch vụ đầu tiên, cung cấp hỗ trợ cơ sở hạ tầng làm mát bằng chất lỏng/làm mát bằng không khí.
DGX Super Pod được tùy chỉnh dựa trên Blackwell Ultra được chia thành hai phiên bản:
DGX SuperPOD với DGX B300 tích hợp. Phiên bản này không chứa chip CPU Grace, có không gian mở rộng hơn nữa và sử dụng hệ thống làm mát bằng không khí. Kịch bản ứng dụng chính của nó là các trung tâm dữ liệu cấp doanh nghiệp thông thường.
Vào tháng 1 năm nay, NVIDIA đã giới thiệu một sản phẩm PC AI ý tưởng có giá 3.000 đô la Mỹ tại CES - Dự án DIGITS. Bây giờ nó có tên chính thức là DGX Spark.
Về thông số sản phẩm, máy được trang bị chip GB10, sức mạnh tính toán 1 PetaFlops ở độ chính xác FP4, bộ nhớ LPDDR5X 128GB tích hợp, card mạng CX-7, bộ lưu trữ NVMe 4TB, chạy hệ điều hành DGX OS tùy chỉnh dựa trên Linux, hỗ trợ các framework như Pytorch và được cài đặt sẵn một số công cụ phát triển phần mềm AI cơ bản do NVIDIA cung cấp, có thể chạy 200 tỷ mô hình tham số. Kích thước của toàn bộ máy tương tự như máy Mac mini. Hai máy DGX Spark có thể được kết nối với nhau và có thể chạy các mô hình có hơn 400 tỷ tham số.
Mặc dù chúng tôi nói rằng đây là PC AI, nhưng về cơ bản nó vẫn thuộc loại siêu máy tính, do đó, nó được xếp vào dòng sản phẩm DGX thay vì các sản phẩm dành cho người tiêu dùng như RTX.
Tuy nhiên, một số người đã phàn nàn về sản phẩm này. Hiệu suất được quảng cáo của FP4 có khả năng sử dụng thấp. Khi chuyển đổi sang độ chính xác FP16, nó chỉ có thể cạnh tranh với RTX 5070 hoặc thậm chí là Arc B580 giá 250 đô la, vì vậy hiệu suất chi phí cực kỳ thấp.

Máy tính DGX Spark và máy trạm DGX Station
Ngoài máy trạm có tên chính thức là DGX Spark, NVIDIA cũng đã ra mắt một máy trạm AI dựa trên Blackwell Ultra. Máy trạm này có CPU Grace tích hợp và GPU Blackwell Ultra, với bộ nhớ hợp nhất 784GB và card mạng CX-8, cung cấp sức mạnh tính toán AI 20PetaFlops (chính thức không được đánh dấu, về mặt lý thuyết cũng có độ chính xác FP4).
Các SKU sản phẩm được giới thiệu trước đó đều dựa trên CPU Grace và GPU Blackwell Ultra, và tất cả đều là sản phẩm cấp doanh nghiệp. Xem xét rằng nhiều người quan tâm đến việc sử dụng tuyệt vời các sản phẩm như RTX 4090 trong lý luận AI, NVIDIA đã tăng cường hơn nữa việc tích hợp dòng Blackwell và RTX tại GTC này và ra mắt một số lượng lớn GPU liên quan đến PC AI với bộ nhớ GDDR7 tích hợp, bao gồm các tình huống như máy tính xách tay, máy tính để bàn và thậm chí cả trung tâm dữ liệu.
GPU máy tính để bàn: bao gồm RTX PRO 6000 Blackwell Workstation Edition, RTX PRO 6000 Blackwell Max-Q Workstation Edition, RTX PRO 5000 Blackwell, RTX PRO 4500 Blackwell và RTX PRO 4000 Blackwell
GPU máy tính xách tay: RTX PRO 5000 Blackwell, RTX PRO 4000 Blackwell, RTX, PRO 3000 Blackwell, RTX PRO 2000 Blackwell, RTX PRO 1000 Blackwell và RTX PRO 500 Blackwell
GPU trung tâm dữ liệu: NVIDIA RTX PRO 6000 Blackwell Server Edition
Trên đây chỉ là một số SKU được tùy chỉnh cho các tình huống khác nhau dựa trên chip Blackwell Ultra, từ máy trạm đến cụm trung tâm dữ liệu. Bản thân NVIDIA gọi nó là "Gầu gia đình Blackwell" và bản dịch tiếng Trung là "Gầu gia đình Blackwell" sẽ phù hợp hơn.
Khái niệm về mô-đun quang điện tử đóng gói chung (CPO) chỉ đơn giản là đóng gói chip chuyển mạch và mô-đun quang lại với nhau, có thể chuyển đổi tín hiệu quang thành tín hiệu điện và tận dụng tối đa hiệu suất truyền tín hiệu quang.
Trước đó, ngành công nghiệp đã thảo luận về sản phẩm chuyển mạch mạng CPO của Nvidia, nhưng đã bị trì hoãn trong việc đưa lên mạng. Huang Renxun cũng đưa ra lời giải thích tại chỗ - do sử dụng rộng rãi các kết nối cáp quang trong các trung tâm dữ liệu, mức tiêu thụ điện năng của mạng quang tương đương với 10% tài nguyên điện toán. Chi phí kết nối quang ảnh hưởng trực tiếp đến mạng Scale-Out của các nút điện toán và cải thiện mật độ hiệu suất AI.

Thông số của hai chip silicon đồng niêm phong Quantum-X và Spectrum-X được trưng bày tại GTC
Tại GTC năm nay, NVIDIA đã ra mắt chip silicon đồng niêm phong Quantum-X, chip silicon đồng niêm phong Spectrum-X và ba sản phẩm chuyển mạch phái sinh: Quantum 3450-LD, Spectrum SN6810 và Spectrum SN6800.
Quantum 3450-LD: 144 cổng 800GB/giây, băng thông mặt sau 115TB/giây, làm mát bằng chất lỏng
Spectrum SN6810: 128 cổng 800GB/giây, băng thông mặt sau 102,4TB/giây, làm mát bằng chất lỏng
Spectrum SN6800: 512 cổng 800GB/giây, băng thông mặt sau 409,6TB/giây, làm mát bằng chất lỏng
Các sản phẩm trên được phân loại thống nhất là “NVIDIA Photonics", NVIDIA cho biết đây là nền tảng dựa trên sự đồng sáng tạo và phát triển của hệ sinh thái đối tác CPO. Ví dụ, bộ điều biến vòng vi mô (MRM) của họ được tối ưu hóa dựa trên động cơ quang học của TSMC, hỗ trợ điều chế laser công suất cao, hiệu suất cao và sử dụng đầu nối sợi quang có thể tháo rời.
Điều thú vị hơn là theo thông tin trước đây của ngành, bộ điều biến vòng vi mô (MRM) của TSMC được TSMC và Broadcom tạo ra dựa trên quy trình 3nm và công nghệ đóng gói tiên tiến như CoWoS.
Theo dữ liệu do NVIDIA cung cấp, các bộ chuyển mạch Photonics tích hợp mô-đun quang có hiệu suất cải thiện gấp 3,5 lần so với các bộ chuyển mạch truyền thống, hiệu quả triển khai tăng gấp 1,3 lần và tính linh hoạt khi mở rộng cao hơn 10 lần.

Huang Renxun đã vẽ "bức tranh toàn cảnh" về cơ sở hạ tầng AI ngay tại chỗ
Bởi vì trong GTC dài 2 giờ này, Huang Renxun chỉ nói về phần mềm và trí thông minh hiện thân trong khoảng nửa giờ. Do đó, nhiều chi tiết được bổ sung bằng các tài liệu chính thức thay vì hoàn toàn đến từ thực tế.
Nvidia Dynamo chắc chắn là quả bom phần mềm được phát hành trong sự kiện này.
Đây là phần mềm nguồn mở được xây dựng để suy luận, đào tạo và tăng tốc trên toàn bộ trung tâm dữ liệu. Dữ liệu hiệu suất của Dynamo khá gây sốc: trên kiến trúc Hopper hiện tại, Dynamo có thể tăng gấp đôi hiệu suất của mẫu Llama tiêu chuẩn. Đối với các mô hình suy luận chuyên biệt như DeepSeek, khả năng tối ưu hóa suy luận thông minh của NVIDIA Dynamo có thể tăng số lượng mã thông báo do mỗi GPU tạo ra lên hơn 30 lần.
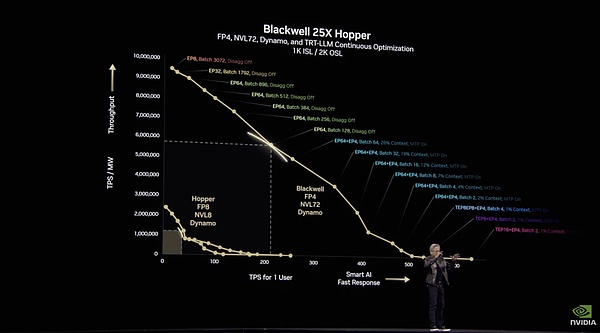
Huang Renxun đã chứng minh rằng Blackwell với Dynamo có thể vượt trội hơn Hopper tới 25 lần.
Những cải tiến này trong Dynamo chủ yếu là do phân phối. Nó phân phối các giai đoạn tính toán khác nhau của LLM (hiểu các truy vấn của người dùng và tạo ra các phản hồi tối ưu) cho các GPU khác nhau, cho phép tối ưu hóa từng giai đoạn một cách độc lập, tăng thông lượng và tăng tốc độ phản hồi.
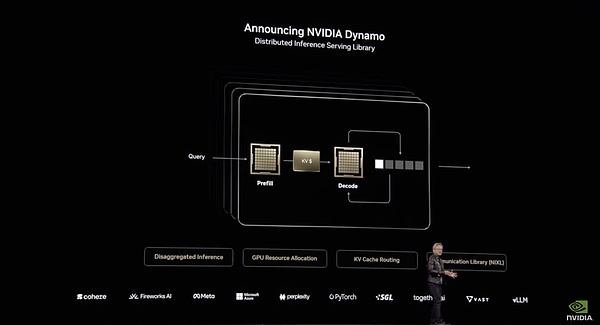
Kiến trúc hệ thống của Dynamo
Ví dụ, trong giai đoạn xử lý đầu vào, tức là giai đoạn điền trước, Dynamo có thể phân bổ hiệu quả tài nguyên GPU để xử lý đầu vào của người dùng. Hệ thống sẽ sử dụng nhiều nhóm GPU để xử lý các truy vấn của người dùng song song, hy vọng rằng quá trình xử lý GPU sẽ phân tán hơn và nhanh hơn. Dynamo sử dụng chế độ FP4 để gọi nhiều GPU để "đọc" và "hiểu" các câu hỏi của người dùng song song. Một nhóm GPU xử lý kiến thức nền tảng về "Thế chiến II", một nhóm khác xử lý dữ liệu lịch sử liên quan đến "nguyên nhân" và nhóm thứ ba xử lý dòng thời gian và các sự kiện của "quy trình". Giai đoạn này giống như nhiều trợ lý nghiên cứu tra cứu một lượng lớn thông tin cùng một lúc.
Khi tạo ra các mã thông báo đầu ra, tức là giai đoạn giải mã, GPU cần phải tập trung và mạch lạc hơn. So với số lượng GPU, giai đoạn này đòi hỏi nhiều băng thông hơn để hấp thụ thông tin suy nghĩ của giai đoạn trước, do đó cần nhiều lệnh đọc bộ nhớ đệm hơn. Dynamo tối ưu hóa giao tiếp giữa các GPU và phân bổ tài nguyên để đảm bảo tạo ra phản hồi nhất quán và hiệu quả. Một mặt, nó tận dụng đầy đủ khả năng truyền thông NVLink băng thông cao của kiến trúc NVL72 để tối đa hóa hiệu quả tạo mã thông báo. Mặt khác, "Smart Router" sẽ chuyển hướng yêu cầu đến GPU đã lưu trữ đệm KV (giá trị khóa) có liên quan, giúp tránh việc tính toán lặp lại và cải thiện đáng kể tốc độ xử lý. Do tránh được việc tính toán lặp đi lặp lại nên một số tài nguyên GPU được giải phóng và Dynamo có thể phân bổ động các tài nguyên nhàn rỗi này cho các yêu cầu mới đến.
Kiến trúc này rất giống với kiến trúc Mooncake của Kimi, nhưng NVIDIA đã cung cấp nhiều hỗ trợ hơn cho cơ sở hạ tầng cơ bản. Mooncake có thể cải thiện hiệu suất khoảng 5 lần, nhưng sự cải thiện về mặt lý luận của Dynamo thì rõ ràng hơn.
Ví dụ, trong số những cải tiến quan trọng của Dynamo, "GPU Planner" có thể điều chỉnh phân bổ GPU một cách linh hoạt theo tải, "Low Latency Communication Library" tối ưu hóa việc truyền dữ liệu giữa các GPU và "Memory Manager" di chuyển dữ liệu suy luận một cách thông minh giữa các thiết bị lưu trữ có mức chi phí khác nhau, giúp giảm thêm chi phí vận hành. Bộ định tuyến thông minh, hệ thống định tuyến nhận biết LLM, sẽ chuyển hướng các yêu cầu đến GPU phù hợp nhất để giảm các tính toán trùng lặp. Chuỗi khả năng này tối ưu hóa tải GPU.
Hệ thống suy luận phần mềm này có thể được mở rộng hiệu quả sang các cụm GPU lớn, cho phép một truy vấn AI duy nhất có thể mở rộng liền mạch lên tới 1.000 GPU để tận dụng tối đa tài nguyên của trung tâm dữ liệu.
Đối với các nhà điều hành GPU, cải tiến này đã giúp giảm đáng kể chi phí cho mỗi triệu token và tăng đáng kể năng lực sản xuất. Đồng thời, mỗi người dùng có thể nhận được nhiều token hơn mỗi giây, phản hồi nhanh hơn và trải nghiệm của người dùng được cải thiện.
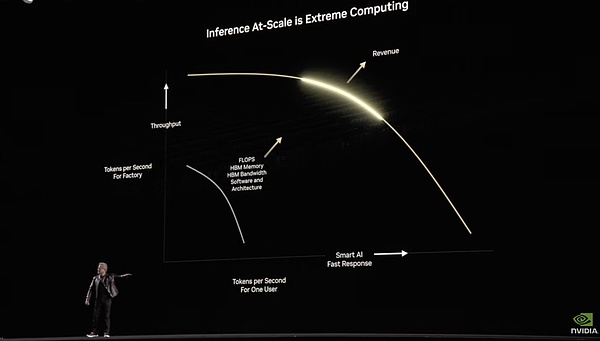
Sử dụng Dynamo để cho phép máy chủ đạt đến ranh giới lợi nhuận vàng giữa thông lượng và tốc độ phản hồi
Không giống như CUDA, nền tảng cơ bản của lập trình GPU, Dynamo là hệ thống cấp cao hơn tập trung vào việc phân bổ và quản lý thông minh các tải suy luận quy mô lớn. Nó chịu trách nhiệm cho lớp lập lịch phân tán được tối ưu hóa suy luận, nằm giữa các ứng dụng và cơ sở hạ tầng điện toán cơ bản. Nhưng cũng giống như cách CUDA đã cách mạng hóa bối cảnh điện toán GPU hơn một thập kỷ trước, Dynamo cũng có thể thành công trong việc tạo ra một mô hình mới cho hiệu quả của phần mềm suy luận và phần cứng.
Dynamo hoàn toàn là mã nguồn mở và hỗ trợ tất cả các nền tảng chính thống từ PyTorch đến Tensor RT. Ngay cả khi là mã nguồn mở thì nó vẫn là một rào cản. Giống như CUDA, nó chỉ hoạt động trên GPU NVIDIA và là một phần của ngăn xếp phần mềm suy luận AI NVIDIA.
Với bản nâng cấp phần mềm này, NVIDIA đã xây dựng được hệ thống phòng thủ riêng chống lại các chip AISC suy luận chuyên dụng như Groq. Cần có sự kết hợp giữa phần mềm và phần cứng để thống trị cơ sở hạ tầng suy luận.
Mặc dù Dynamo thực sự khá tuyệt vời về mặt sử dụng máy chủ, nhưng NVIDIA vẫn còn khoảng cách với các chuyên gia thực sự trong các mô hình đào tạo.
NVIDIA đã sử dụng một mô hình mới, Llama Nemotron, tại GTC này, tập trung vào hiệu quả và độ chính xác. Nó có nguồn gốc từ dòng mô hình Llama. Sau khi được NVIDIA tinh chỉnh đặc biệt, mô hình này đã được tối ưu hóa thông qua việc cắt giảm thuật toán và nhẹ hơn mô hình Llama ban đầu, chỉ nặng 48 byte. Nó cũng có khả năng suy luận tương tự như o1. Giống như Claude 3.7 và Grok 3, mô hình Llama Nemotron có công tắc khả năng suy luận tích hợp mà người dùng có thể chọn bật hoặc tắt. Dòng sản phẩm này được chia thành ba cấp độ: Nano dành cho người mới bắt đầu, Super tầm trung và Ultra cao cấp, mỗi cấp độ hướng đến nhu cầu của các doanh nghiệp có quy mô khác nhau.
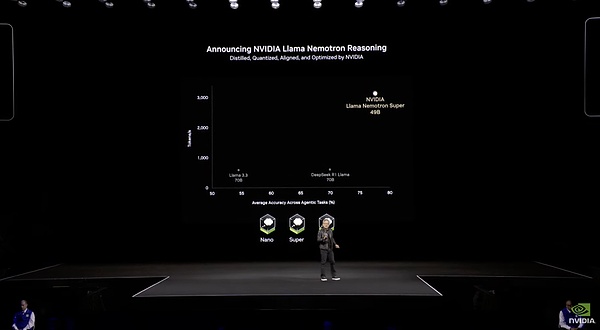
Dữ liệu cụ thể của Llama Nemotron
Nói về hiệu quả, tập dữ liệu tinh chỉnh của mô hình này hoàn toàn bao gồm dữ liệu tổng hợp do chính NVIDIA tạo ra, với tổng cộng khoảng 60 tỷ mã thông báo. So với DeepSeek V3 mất 1,3 triệu giờ H100 để đào tạo đầy đủ, mô hình này chỉ có 1/15 tham số của DeepSeek V3 và chỉ mất 360.000 giờ H100 để tinh chỉnh. Hiệu quả đào tạo thấp hơn một cấp so với DeepSeek.
Về hiệu quả suy luận, mô hình Llama Nemotron Super 49B thực sự hoạt động tốt hơn nhiều so với mô hình thế hệ trước. Thông lượng mã thông báo của nó có thể đạt gấp 5 lần so với Llama 3 70B. Trên một GPU trung tâm dữ liệu duy nhất, nó có thể xử lý hơn 3.000 mã thông báo mỗi giây. Nhưng trong dữ liệu được công bố vào ngày cuối cùng của Ngày nguồn mở DeepSeek, mỗi nút H800 có thông lượng trung bình khoảng 73,7 nghìn token/giây đầu vào (bao gồm cả lượt truy cập bộ đệm) trong quá trình điền trước hoặc khoảng 14,8 nghìn token/giây đầu ra trong quá trình giải mã. Khoảng cách giữa hai điều này vẫn còn rất rõ ràng.
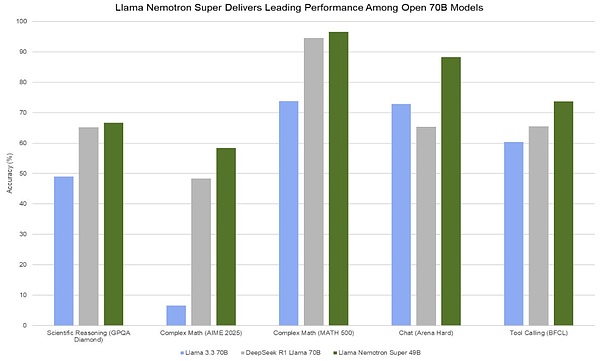
Về hiệu suất, Llama Nemotron Super 49B vượt trội hơn mẫu Llama 70B do DeepSeek R1 tinh chế ở mọi chỉ số. Tuy nhiên, xét đến việc ra mắt thường xuyên các mẫu máy bay có thông số nhỏ, năng lượng cao như mẫu Qwen QwQ 32B, người ta ước tính rằng Llama Nemotron Super sẽ khó có thể nổi bật giữa các mẫu máy bay có thể cạnh tranh với thân máy bay chính R1.
Điều nguy hiểm nhất là mô hình này chứng minh rằng DeepSeek có thể biết cách điều chỉnh GPU trong quá trình đào tạo tốt hơn NVIDIA.
Tại sao NVIDIA lại phát triển mô hình suy luận? Điều này chủ yếu là để chuẩn bị cho điểm bùng nổ tiếp theo của AI mà Huang đang để mắt tới - AI Agent. Vì OpenAI, Claude và các công ty lớn khác đã dần thiết lập nền tảng cho Agent thông qua DeepReasearch và MCP, NVIDIA rõ ràng tin rằng kỷ nguyên của Agent đã đến.
Dự án NVIDA AIQ là nỗ lực của NVIDIA. Nó cung cấp trực tiếp quy trình làm việc có sẵn cho tác nhân AI của người lập kế hoạch với mô hình lý luận Llama Nemotron làm cốt lõi. Dự án này thuộc cấp độ Bản thiết kế của NVIDIA, đề cập đến một tập hợp các quy trình làm việc và mẫu tham chiếu được cấu hình sẵn giúp các nhà phát triển tích hợp công nghệ và thư viện của NVIDIA dễ dàng hơn. AIQ là mẫu Agent do NVIDIA cung cấp.
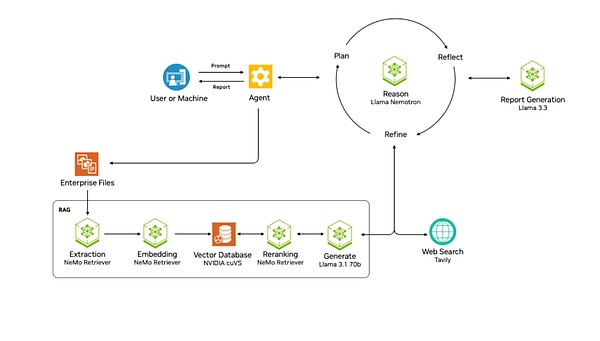
Kiến trúc của NVIDIA AIQ
Giống như Manus, nó tích hợp các công cụ bên ngoài như công cụ tìm kiếm trên web và các tác nhân AI chuyên nghiệp khác, cho phép bản thân Tác nhân vừa tìm kiếm vừa sử dụng nhiều công cụ khác nhau. Mô hình lý luận của Llama Nemotron lập kế hoạch, phản ánh và tối ưu hóa các giải pháp xử lý để hoàn thành nhiệm vụ của người dùng. Ngoài ra, nó còn hỗ trợ xây dựng kiến trúc quy trình làm việc đa tác nhân.
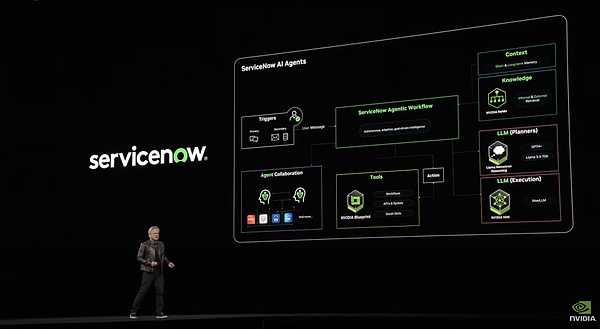
Hệ thống servicenow dựa trên mẫu này
Tiến xa hơn một bước so với Manus, nó có một hệ thống RAG phức tạp dành cho các tệp của công ty. Hệ thống này bao gồm một loạt các bước như trích xuất, nhúng, lưu trữ vectơ, sắp xếp lại và xử lý cuối cùng thông qua LLM, có thể đảm bảo rằng dữ liệu doanh nghiệp có thể được Agent sử dụng.
Ngoài ra, NVIDIA còn ra mắt nền tảng dữ liệu AI để kết nối mô hình suy luận AI với hệ thống dữ liệu doanh nghiệp để hình thành DeepReasearch cho dữ liệu doanh nghiệp. Điều này đã dẫn đến sự phát triển đáng kể trong công nghệ lưu trữ, khiến hệ thống lưu trữ không còn chỉ là kho dữ liệu mà là nền tảng thông minh có khả năng phân tích và suy luận chủ động.
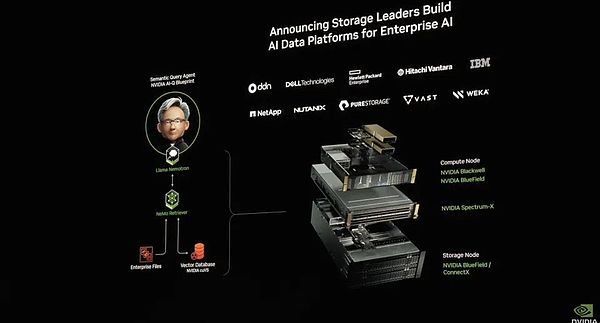
Thành phần của Nền tảng dữ liệu AI
Ngoài ra, AIQ còn rất coi trọng các cơ chế khả năng quan sát và minh bạch. Điều này rất quan trọng cho sự an toàn và những cải tiến sau này. Nhóm phát triển có thể theo dõi hoạt động của Agent theo thời gian thực và liên tục tối ưu hóa hệ thống dựa trên dữ liệu hiệu suất.
Nhìn chung, NVIDA AIQ là một mẫu quy trình làm việc của Agent chuẩn cung cấp nhiều khả năng khác nhau của Agent. Đây là phần mềm xây dựng Agent giống như Dify đã phát triển vào kỷ nguyên lý luận và có khả năng chống lỗi tốt hơn.
Nếu tập trung vào Agent vẫn là đầu tư vào hiện tại, thì cách bố trí trí tuệ hiện thân của NVIDIA có thể được coi là tích hợp tương lai.
NVIDIA đã sắp xếp cả ba yếu tố của mô hình: mô hình, dữ liệu và sức mạnh tính toán.
Chúng ta hãy bắt đầu với mô hình. GTC này đã phát hành phiên bản nâng cấp của mô hình cơ bản về trí thông minh được thể hiện mà Cosmos công bố vào tháng 1 năm nay.
Cosmos là một mô hình có thể dự đoán hình ảnh tương lai thông qua hình ảnh hiện tại. Nó có thể lấy dữ liệu đầu vào từ văn bản/hình ảnh, tạo video chi tiết và dự đoán sự phát triển của một cảnh bằng cách kết hợp trạng thái hiện tại (hình ảnh/video) với các hành động (tín hiệu điều khiển/gợi ý). Vì điều này đòi hỏi phải hiểu biết về các định luật nhân quả vật lý của thế giới nên Nvidia gọi Cosmos là Mô hình cơ bản thế giới (WFM).
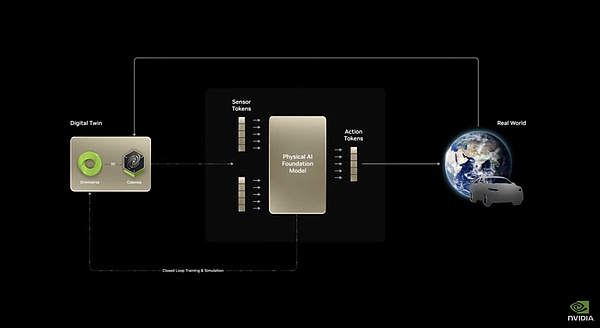
Kiến trúc cơ bản của Cosmos
Đối với trí thông minh hiện thân, khả năng cốt lõi nhất là dự đoán tác động của hành vi máy móc lên thế giới bên ngoài. Chỉ theo cách này, mô hình mới có thể lập kế hoạch hành vi dựa trên các dự đoán, do đó mô hình thế giới trở thành mô hình cơ bản của trí thông minh hiện thân. Với mô hình dự đoán thay đổi thế giới vật lý/hành vi cơ bản này, thông qua việc tinh chỉnh các tập dữ liệu cụ thể như lái xe tự động và nhiệm vụ của rô-bốt, mô hình này có thể đáp ứng nhu cầu triển khai thực tế của nhiều trí thông minh hiện thân với các hình thức vật lý.
Toàn bộ mô hình bao gồm ba khả năng. Phần đầu tiên, Cosmos Transfer, chuyển đổi đầu vào văn bản video có cấu trúc thành đầu ra video thực tế có thể kiểm soát, tạo ra dữ liệu tổng hợp quy mô lớn từ hư không bằng cách sử dụng văn bản. Điều này giải quyết được nút thắt lớn nhất của trí thông minh hiện nay - vấn đề dữ liệu không đủ. Hơn nữa, thế hệ này là thế hệ "có thể kiểm soát", nghĩa là người dùng có thể chỉ định các thông số cụ thể (như điều kiện thời tiết, thuộc tính vật thể, v.v.) và mô hình sẽ điều chỉnh kết quả thế hệ cho phù hợp, giúp quá trình tạo dữ liệu dễ kiểm soát và có mục tiêu hơn. Toàn bộ quá trình này cũng có thể được kết hợp với Ominiverse và Cosmos.

Cosmos là một mô phỏng thực tế được xây dựng trên Ominiverse
Phần thứ hai, Cosmos Predict, có thể tạo ra các trạng thái thế giới ảo từ các đầu vào đa phương thức, hỗ trợ tạo nhiều khung hình và dự đoán quỹ đạo hành động. Điều này có nghĩa là, với trạng thái bắt đầu và kết thúc cho trước, mô hình có thể tạo ra các quá trình trung gian hợp lý. Đây là khả năng cốt lõi để hiểu và xây dựng thế giới vật chất.
Phần thứ ba là Cosmos Reason, một mô hình mở và có thể tùy chỉnh hoàn toàn với khả năng nhận thức không gian thời gian. Nó hiểu dữ liệu video thông qua suy luận chuỗi suy nghĩ và dự đoán kết quả tương tác. Đây là khả năng cải thiện trong việc lập kế hoạch hành động và dự đoán kết quả của hành động.
Với việc bổ sung dần ba khả năng này, Cosmos có thể đạt được chuỗi hành vi hoàn chỉnh từ đầu vào mã thông báo hình ảnh thực + mã thông báo nhắc lệnh văn bản đến đầu ra mã thông báo hành động của máy.
Mô hình cơ bản này sẽ hoạt động thực sự tốt. Chỉ hai tháng sau khi ra mắt, ba công ty hàng đầu là 1X, Agility Robotics và Figure AI đã bắt đầu sử dụng nó. NVIDIA không dẫn đầu trong các mô hình ngôn ngữ lớn, nhưng xét về trí thông minh hiện thân, thì họ thực sự ở hạng nhất.
Với Cosmos, NVIDIA đã sử dụng khuôn khổ này để tinh chỉnh và đào tạo Isaac GR00T N1, một mô hình cơ bản dành riêng cho robot hình người.
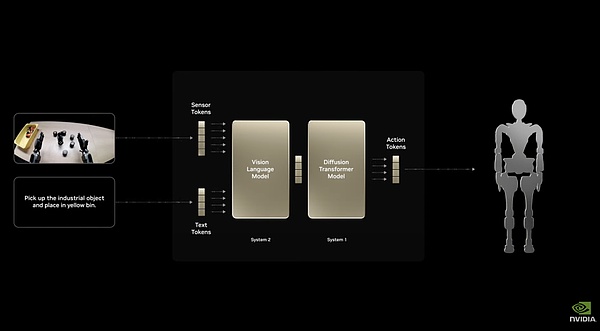
Kiến trúc hệ thống kép của Isaac GR00T N1
Nó sử dụng kiến trúc hệ thống kép, với "Hệ thống 1" phản hồi nhanh và "Hệ thống 2" lý luận sâu sắc. Khả năng tinh chỉnh toàn diện cho phép nó thực hiện các nhiệm vụ thông thường như cầm nắm, di chuyển và điều khiển bằng cả hai tay. Nó cũng có thể được tùy chỉnh hoàn toàn cho từng robot cụ thể và các nhà phát triển robot có thể sử dụng dữ liệu thực hoặc tổng hợp để đào tạo sau. Điều này cho phép mô hình có thể được triển khai trong hầu hết mọi loại robot có hình dạng khác nhau.
Ví dụ, Nvidia, hợp tác với Google DeepMind và Disney để phát triển công cụ vật lý Newton, đã sử dụng Isaac GR00T N1 làm cơ sở để điều khiển một chú rô-bốt Disney BDX nhỏ rất khác thường. Điều này cho thấy nó linh hoạt như thế nào. Newton là một công cụ vật lý rất chi tiết, do đó, chỉ cần xây dựng một hệ thống phần thưởng vật lý để rèn luyện trí thông minh trong môi trường ảo là đủ.

Huang Renxun "say mê" tương tác với robot BDX trên sân khấu
NVIDIA đã kết hợp NVIDIA Omniverse và mô hình cơ sở thế giới NVIDIA Cosmos Transfer được đề cập ở trên để tạo ra Isaac GR00T Blueprint. Nó có thể tạo ra lượng lớn dữ liệu chuyển động tổng hợp từ một lượng nhỏ các cuộc trình diễn của con người để phục vụ cho mục đích đào tạo điều khiển robot. Sử dụng các thành phần đầu tiên của Blueprint, NVIDIA đã tạo ra 780.000 quỹ đạo tổng hợp chỉ trong 11 giờ, tương đương với 6.500 giờ (khoảng chín tháng) dữ liệu trình diễn của con người. Một phần đáng kể dữ liệu của Isaac GR00T N1 đến từ đây, giúp cải thiện hiệu suất của GR00T N1 lên 40% so với việc chỉ sử dụng dữ liệu thực.

Hệ thống mô phỏng song sinh
Đối với mỗi mô hình, NVIDIA có thể cung cấp một lượng lớn dữ liệu chất lượng cao thông qua hệ thống ảo thuần túy Omniverse và hệ thống tạo hình ảnh thế giới thực Cosmos Transfer. Nvidia cũng đề cập đến khía cạnh thứ hai của mô hình này.
Kể từ năm ngoái, Huang đã nhấn mạnh khái niệm "ba máy tính" tại GTC: một là DGX, một máy chủ GPU lớn, được sử dụng để đào tạo AI, bao gồm cả trí thông minh hiện thân. AGX còn lại là nền tảng điện toán nhúng do NVIDIA thiết kế cho điện toán biên và hệ thống tự động. Nó được sử dụng để triển khai AI ở biên, chẳng hạn như chip lõi cho xe tự hành hoặc rô bốt. Thứ ba là máy tính tạo dữ liệu Omniverse+Cosmos.
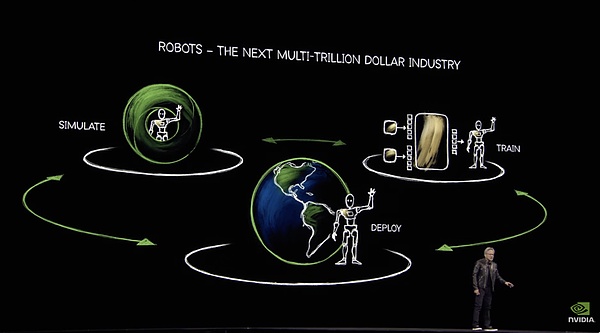
Ba hệ thống máy tính chính của trí thông minh hiện thân
Hệ thống này đã được Huang nhắc lại tại GTC này và ông ấy đặc biệt đề cập rằng với hệ thống máy tính này, hàng tỷ robot có thể được sinh ra. Từ đào tạo đến triển khai, NVIDIA đều được sử dụng để tăng cường sức mạnh tính toán. Phần này cũng đã đóng.
Nếu chỉ so sánh với thế hệ chip Blackwell trước thì phần cứng của Blackwell Ultra không hề sánh bằng những tính từ trước đây như "bom hạt nhân", "bom vua", thậm chí còn có cảm giác hơi giống bóp kem đánh răng.
Tuy nhiên, xét về mặt lập kế hoạch lộ trình, tất cả những điều này đều nằm trong bố cục của Huang Renxun. Năm tới và năm sau nữa, kiến trúc Rubin sẽ chứng kiến những cải tiến đáng kể về công nghệ chip, bóng bán dẫn, tích hợp giá đỡ, kết nối GPU và kết nối tủ. Như người Trung Quốc nói, "điều tốt nhất vẫn chưa đến".
So với những lời hứa suông về mặt phần cứng, Nvidia đã có những tiến bộ nhanh chóng về mặt phần mềm trong hai năm qua.
Khi xem xét toàn bộ hệ sinh thái phần mềm của NVIDIA, ba cấp độ dịch vụ Meno, Nim và Blueprint bao gồm các giải pháp đầy đủ từ tối ưu hóa mô hình, đóng gói mô hình đến xây dựng ứng dụng. Các ngóc ngách sinh thái của các công ty dịch vụ đám mây và NVIDIA AI đều chồng chéo lên nhau. Với việc bổ sung Agent, cơ sở hạ tầng AI, NVIDIA muốn tiếp quản mọi bộ phận ngoại trừ mô hình cơ bản.
Khi nói đến phần mềm, nhu cầu của Huang lớn ngang với giá cổ phiếu của Nvidia.
Trong thị trường robot, Nvidia thậm chí còn có tham vọng lớn hơn. Ba yếu tố mô hình, dữ liệu và sức mạnh tính toán đều nằm trong tay chúng ta. Nó không bắt kịp vị trí hàng đầu trong mô hình ngôn ngữ cơ bản, nhưng được bù đắp bằng trí thông minh cơ bản hiện thân. Trong bóng tối, một gã khổng lồ độc quyền thông minh đã xuất hiện ở đường chân trời.
Ở đây, mọi liên kết và mọi sản phẩm đều tương ứng với một thị trường tiềm năng có giá trị hàng trăm tỷ nhân dân tệ. Hoàng Nhân Huân, ông vua cờ bạc may mắn đã đánh bạc mọi thứ trong những năm đầu đời, đã bắt đầu một canh bạc lớn hơn với số tiền kiếm được từ việc độc quyền GPU.
Nếu Nvidia chiến thắng ở thị trường phần mềm hoặc robot trong canh bạc này, thì họ sẽ trở thành Google của kỷ nguyên AI, là nhà độc quyền hàng đầu trong chuỗi thức ăn.
Tuy nhiên, khi nhìn vào biên lợi nhuận GPU của Nvidia, chúng tôi vẫn hy vọng rằng tương lai như vậy sẽ không đến.
May mắn thay, đây là canh bạc lớn nhất mà Lão Hoàng chưa từng trải qua trong đời, kết quả không thể đoán trước.
Cointelegraph đã tweet rằng SEC đã phê duyệt quỹ ETF giao ngay Bitcoin (BTC) của iShares, nhưng đã được BlackRock xác nhận là sai.
AaronFantom Foundation nhận thấy mình đang phải đối mặt với một vi phạm nghiêm trọng khiến 657 nghìn đô la bị rút cạn khi hơn 35 ví tiền điện tử cạn kiệt.
 Catherine
CatherineNhưng có lẽ vì nó luôn là đối tượng của các cuộc tấn công và với khoản khai thác trị giá 50 triệu đô la vào năm 2019 đang rình rập họ, cách tiếp cận của Upbit đối với vấn đề bảo mật và rủi ro là thận trọng hơn hầu hết.
 Snake
SnakeViệc mua lại diễn ra sau một đợt huy động vốn tương đối gần đây cho BitGo và quan hệ đối tác với Ngân hàng Hana của Hàn Quốc.
 Clement
ClementCác sàn giao dịch này đã tạm dừng gửi và rút tiền đặc biệt đối với token Wrapped EVER (WEVER), với các token EVER gốc vẫn được bảo mật và không bị ảnh hưởng trên Octus Bridge.
 Davin
DavinBinance.US không còn cho phép rút USD; yêu cầu người dùng chuyển đổi USD sang stablecoin hoặc các tài sản kỹ thuật số khác.
 Kikyo
KikyoESMA cảnh báo thêm rằng ngay cả sau khi triển khai, các nhà đầu tư vẫn nên chuẩn bị cho khả năng chịu tổng thiệt hại.
ClementTrải nghiệm cuộc cách mạng trò chơi kỹ thuật số với thanh toán bằng tiền điện tử trong Roblox!
 Hui Xin
Hui XinTỷ lệ đốt của Shiba Inu ($SHIB), loại tiền điện tử lấy cảm hứng từ meme, đã chứng kiến mức tăng đáng kinh ngạc hơn 250% chỉ trong khoảng thời gian 24 giờ. Sự gia tăng này được kích hoạt bởi một loạt 23 giao dịch đáng kể, dẫn đến việc loại bỏ 47,9 triệu mã thông báo SHIB khỏi lưu thông.
 Jasper
JasperSui dưới lăng kính điều tra của FSS với các cáo buộc tập trung vào các báo cáo không chính xác liên quan đến nguồn cung lưu thông của nó và lợi nhuận có mục đích thu được từ hoạt động đặt cược.
Catherine