Livepeer: How to introduce AI video computing on the Livepeer network
Now is the time to bring AI video computing capabilities to Livepeer
 JinseFinance
JinseFinance

Author: Cynic, Shigeru
Introduction:Using the power of algorithms, computing power and data, the advancement of AI technology is redefining data processing and intelligent decision-making border. At the same time, DePIN represents a paradigm shift from centralized infrastructure to decentralized, blockchain-based networks.
As the world continues to accelerate towards digital transformation, AI and DePIN (decentralized physical infrastructure) have become the driving force for change in all walks of life. Basic technology. The integration of AI and DePIN will not only promote the rapid iteration and widespread application of technology, but will also open up a more secure, transparent and efficient service model, bringing far-reaching changes to the global economy.
DePIN: Decentralization turns from virtual to real, the mainstay of the digital economy
DePIN is the abbreviation of Decentralized Physical Infrastructure. In a narrow sense, DePIN mainly refers to the distributed network of traditional physical infrastructure supported by distributed ledger technology, such as power network, communication network, positioning network, etc. Broadly speaking, all distributed networks supported by physical devices can be called DePIN, such as storage networks and computing networks.
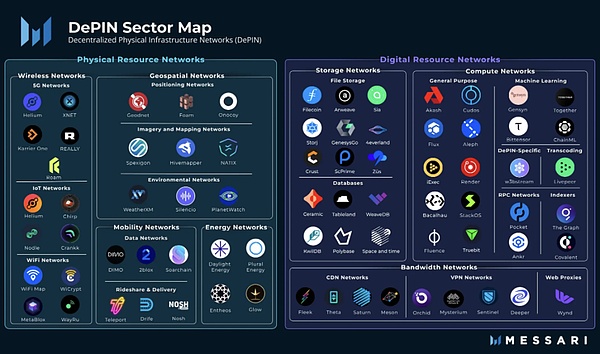
from: Messari
If Crypto has brought about Centralization changes, then DePIN is a decentralized solution in the real economy. It can be said that the PoW mining machine is a kind of DePIN. DePIN has been a core pillar of Web3 from day one.
Of the three elements of AI—algorithm, computing power, and data, DePIN exclusively possesses two of them
The development of artificial intelligence is generally considered to depend on three key elements: algorithms, computing power and data. Algorithms refer to the mathematical models and program logic that drive AI systems, computing power refers to the computing resources required to execute these algorithms, and data is the basis for training and optimizing AI models.

Which of the three elements is the most important? Before the emergence of chatGPT, people usually thought of it as an algorithm, otherwise academic conferences and journal papers would not be filled with algorithm fine-tuning one after another. But when chatGPT and the large language model LLM that supports its intelligence were unveiled, people began to realize the importance of the latter two. Massive computing power is the prerequisite for the birth of models. Data quality and diversity are crucial to building a robust and efficient AI system. In contrast, the requirements for algorithms are no longer as refined as usual.
In the era of large models, AI has changed from meticulous craftsmanship to vigorous flying bricks. The demand for computing power and data is increasing day by day, and DePIN can provide it. Token incentives leverage the long-tail market, and massive consumer-grade computing power and storage will become the best nourishment for large models.
AI decentralization is not an option, but a necessity
Of course some people will ask, since computing power and data are available in the AWS computer room, and they are better than DePIN in terms of stability and user experience, why should we choose DePIN instead of a centralized service?
This statement naturally makes sense. After all, looking at the current situation, almost all large models are developed directly or indirectly by large Internet companies. Behind chatGPT It's Microsoft, and behind Gemini is Google. Almost everyone in China's major Internet companies has a large model. Why? Because only large Internet companies have enough high-quality data and computing power supported by strong financial resources. But this is wrong. People no longer want to be controlled by Internet giants.
On the one hand, centralized AI has data privacy and security risks and may be subject to censorship and control; on the other hand, the AI produced by Internet giants will make people further Strengthen dependence and lead to market concentration and increase barriers to innovation.

from: https://www.gensyn.ai/
Human There should be no need for a Martin Luther in the AI era. People should have the right to talk directly to God.
DePIN from a business perspective: cost reduction and efficiency increase are the key
Even putting aside the value debate between decentralization and centralization, from a business perspective, using DePIN for AI still has its merits.
First of all, we need to clearly understand that although Internet giants have a large number of high-end graphics card resources, the combination of consumer-grade graphics cards scattered among the private sector can also constitute A very impressive network of computing power, which is the long tail effect of computing power. The idle rate of this type of consumer-grade graphics card is actually very high. As long as the incentives provided by DePIN can exceed the electricity bill, users will have the incentive to contribute computing power to the network. At the same time, all physical facilities are managed by the users themselves. The DePIN network does not need to bear the unavoidable operating costs of centralized suppliers, and only needs to focus on the protocol design itself.
For data, the DePIN network can release the availability of potential data and reduce transmission costs through edge computing and other methods. At the same time, most distributed storage networks have automatic deduplication functions, which reduces the work of AI training data cleaning.
Finally, the Crypto economics brought by DePIN enhance the system's fault tolerance and is expected to achieve a win-win situation for providers, consumers, and platforms.
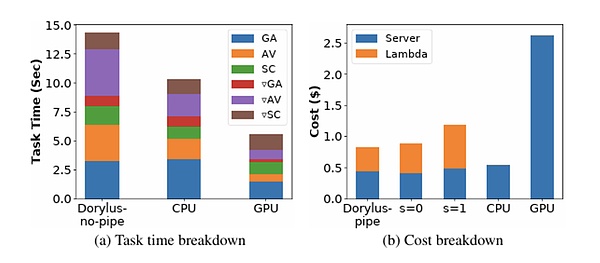
from: UCLA
In case you don’t believe it, UCLA’s latest research It shows that the use of decentralized computing achieves 2.75 times performance compared to traditional GPU clusters at the same cost. Specifically, it is 1.22 times faster and 4.83 times cheaper.
Difficult road ahead: What challenges will AIxDePIN encounter?
We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard.< /p>
——John Fitzgerald Kennedy
Distributed storage and distributed computing using DePIN without trust There are still many challenges in building artificial intelligence models.
Work verification
Essentially, computational deep learning Both the model and PoW mining are general-purpose calculations, and the lowest layer is the signal changes between gate circuits. From a macro perspective, PoW mining is a "useless calculation", trying to obtain a hash value with n zeros prefixed by countless random number generation and hash function calculations; while deep learning calculations are "useful calculations", through countless random number generation and hash function calculations. Forward derivation and backward derivation calculate the parameter values of each layer in deep learning to build an efficient AI model.
The fact is that "useless calculations" such as PoW mining use hash functions. It is easy to calculate the image from the preimage, and it is very easy to calculate the preimage from the image. is difficult, so anyone can easily and quickly verify the validity of the calculation; for the calculation of the deep learning model, due to the hierarchical structure, the output of each layer is used as the input of the next layer, so verifying the validity of the calculation requires All previous work cannot be verified simply and efficiently.
from: AWS
Work verification is very critical, otherwise, the calculation The provider of can completely skip the calculation and submit a randomly generated result.
One idea is to let different servers perform the same computing tasks and verify the effectiveness of the work by repeating the execution and checking whether it is the same. However, the vast majority of model calculations are non-deterministic, and the same results cannot be reproduced even under the exact same computing environment, and can only be similar in a statistical sense. In addition, double counting will lead to a rapid increase in costs, which is inconsistent with DePIN's key goal of reducing costs and increasing efficiency.
Another type of idea is the Optimistic mechanism, which first optimistically believes that the results have been calculated effectively, and at the same time allows anyone to check the calculation results if errors are found. , you can submit a Fraud Proof, and the agreement will fine the fraudster and reward the reporter.
Parallelization
As mentioned before, DePIN leveraging It is mainly a long-tail consumer computing power market, which means that the computing power that a single device can provide is relatively limited. For large AI models, training on a single device will take a very long time, and parallelization must be used to shorten the training time.
The main difficulty in parallelizing deep learning training lies in the dependency between previous and subsequent tasks. This dependency will make parallelization difficult to achieve.
Currently, the parallelization of deep learning training is mainly divided into data parallelism and model parallelism.
Data parallelism refers to distributing data on multiple machines. Each machine saves all parameters of a model, uses local data for training, and finally trains The parameters of each machine are aggregated. Data parallelism works well when the amount of data is large, but requires synchronous communication to aggregate parameters.
Model parallelism means that when the size of the model is too large to fit into a single machine, the model can be divided into multiple machines, and each machine saves a part of the parameters of the model. . Forward and backward propagation require communication between different machines. Model parallelism has advantages when the model is large, but the communication overhead during forward and backward propagation is large.
For gradient information between different layers, it can be divided into synchronous update and asynchronous update. Synchronous update is simple and direct, but it will increase the waiting time; the asynchronous update algorithm has a short waiting time, but will introduce stability problems.
from: Stanford University, Parallel and Distributed Deep Learning
Privacy
The global trend of protecting personal privacy is rising, and governments around the world are strengthening the protection of personal data privacy security. Although AI makes extensive use of public data sets, what truly differentiates different AI models is the proprietary user data of each enterprise.
How to get the benefits of proprietary data during training without exposing privacy? How to ensure that the parameters of the built AI model are not leaked?
These are two aspects of privacy, data privacy and model privacy. Data privacy protects users, while model privacy protects the organization that builds the model. In the current scenario, data privacy is much more important than model privacy.
A variety of solutions are trying to solve the privacy problem. Federated learning ensures data privacy by training at the source of the data, keeping the data locally, and transmitting model parameters; and zero-knowledge proof may become a rising star.
Case analysis: What high-quality projects are there on the market?
Gensyn
Gensyn is a distribution Formula computing network for training AI models. The network uses a layer of blockchain based on Polkadot to verify that deep learning tasks have been executed correctly and trigger payments via commands. Founded in 2020, it disclosed a US$43 million Series A financing in June 2023, led by a16z.
Gensyn uses metadata of gradient-based optimization processes to build certificates of the work performed, consistent with multi-granular, graph-based precision protocols and cross-evaluators execution to allow the verification work to be re-run and compared for consistency, and ultimately confirmed by the chain itself to ensure the validity of the calculations. To further strengthen the reliability of work verification, Gensyn introduces staking to create incentives.
There are four types of participants in the system: submitters, solvers, verifiers and reporters.
• Submitters are end users of the system who provide tasks to be computed and pay for units of work completed.
• The solver is the main worker of the system, performing model training and generating proofs for inspection by the verifier.
• Validators are key to linking the non-deterministic training process with deterministic linear calculations, replicating partial solver proofs and comparing distances to expected thresholds.
• Informers are the last line of defense, checking the work of verifiers and raising challenges, and are rewarded after passing the challenges.
The solver needs to pledge, and the reporter will test the solver's work. If he finds evildoing, he will challenge it. After the challenge is passed, the tokens pledged by the solver will be confiscated. Whistleblowers receive rewards.
According to Gensyn’s predictions, this solution is expected to reduce training costs to 1/5 of those of centralized providers.
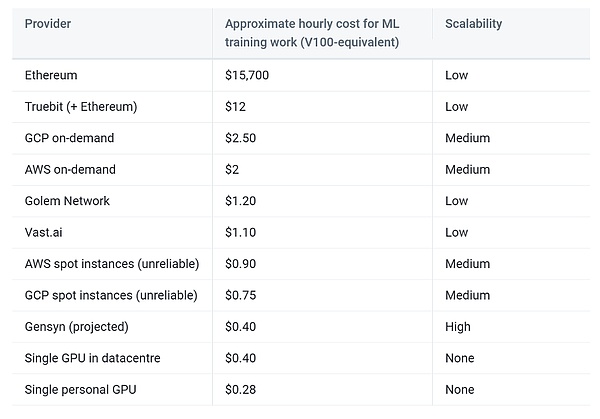
from: Gensyn
FedML
FedML is a decentralized collaborative machine learning platform for decentralized and collaborative AI, anywhere and at any scale. More specifically, FedML provides an MLOps ecosystem that trains, deploys, monitors, and continuously improves machine learning models while collaborating on combined data, models, and computing resources in a privacy-preserving manner. Founded in 2022, FedML disclosed a $6 million seed round in March 2023.
FedML consists of two key components, FedML-API and FedML-core, which represent high-level API and low-level API respectively.
FedML-core includes two independent modules: distributed communication and model training. The communication module is responsible for the underlying communication between different workers/clients and is based on MPI; the model training module is based on PyTorch.
FedML-API is built on FedML-core. With FedML-core, new distributed algorithms can be easily implemented by adopting client-oriented programming interfaces.
The latest work of the FedML team has proven that using FedML Nexus AI to perform AI model inference on the consumer GPU RTX 4090 is 20 times cheaper and 1.88 times faster than A100 .
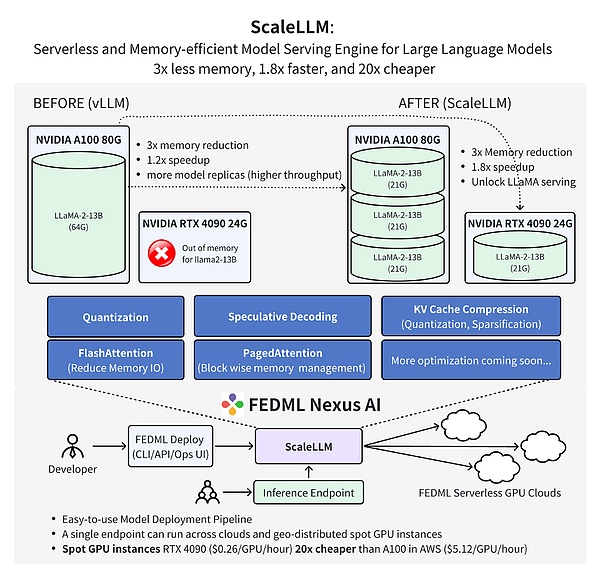
from: FedML
Future Outlook: DePIN brings AI Democracy
One day, AI will further develop into AGI, and computing power will become the de facto universal currency. DePIN will advance this process occur.
The integration of AI and DePIN has opened up a new technological growth point and provided huge opportunities for the development of artificial intelligence. DePIN provides AI with massive distributed computing power and data, helping to train larger-scale models and achieve stronger intelligence. At the same time, DePIN also enables AI to develop in a more open, secure, and reliable direction, reducing reliance on a single centralized infrastructure.
Looking to the future, AI and DePIN will continue to develop collaboratively. The distributed network will provide a strong foundation for training very large models, and these models will play an important role in the application of DePIN. While protecting privacy and security, AI will also help optimize DePIN network protocols and algorithms. We look forward to AI and DePIN bringing a more efficient, fairer, and more trustworthy digital world.
Now is the time to bring AI video computing capabilities to Livepeer
JinseFinanceMost noted for its association with the Web3 game Axie Infinity, Ronin has proven its reliability by servicing millions of daily active users and managing substantial transaction volumes - exceeding $4 billion in NFT volumes thus far.
 BrianJinseFinance
BrianJinseFinanceUS introduces bills to limit China's role in blockchain and cryptocurrency, aiming to protect national security and data privacy.
 Hui Xin
Hui XinOP Labs introduces fault-proof system in optimism's Goerli testnet, paving the way for decentralised superchain ecosystem.
 Bitcoinworld
BitcoinworldYesterday Mastercard announced plans to launch a beta version of the Mastercard Multi-Token Network (MTN).
 Ledgerinsights
LedgerinsightsThe SOL price has dumped to its lowest point since March 2021.
 Beincrypto
BeincryptoEthereum proves to be both a breakthrough and a factor of constraint for new blockchain protocols.
 Cointelegraph
CointelegraphThe Bitcoin network recorded the year 2022’s lowest power demand of 10.65 gigawatts (GW). At its peak, the BTC network demanded 16.09 GW of power.
CointelegraphPayments on Bitcoin’s second-layer scaling solution, Lightning Network, grew by more than 400% as adoption actually grew.
Cointelegraph