Author: Wuyue& Faust, geek web3
Advisor: Kevin He, founder of BitVM Chinese community, ex Web3 Tech Head@Huobi
But unfortunately, most of the current written materials about BitVM fail to explain its principles in a popular way.
This article is after we read BitVM’s 8-page white paper and reviewed information related to Taproot, MAST tree, and Bitcoin Script. , a simple summary. In order to facilitate readers' understanding, some of the expressions are different from the content explained in the BitVM white paper. We assume that readers have some understanding of Layer2 and can understand the simple idea of "fraud proof".

The first few sentences summarize BitVM's ideas: data that does not need to be on chain should be released and stored off-chain first, and only Commitment (commitment) is stored on the chain.
When a challenge/fraud proof occurs, we only put the data that needs to be uploaded on chain to prove that it is related to the Commitment on the chain. Afterwards, the BTC main network will verify whether there are any problems with the on-chain data and whether the data producers (nodes that process transactions) have done anything evil. All this follows the principle of Occam's razor - "Don't add entities unless necessary" (if you can reduce on chain, reduce on chain).

Text: The so-called BitVM-based fraud proof verification scheme on the BTC chain, popular summary:
1. First of all, a computer/processor is an input-output system composed of a large number of logic gate circuits. One of the core ideas of BitVM is to use Bitcoin Script to simulate the input-output effect of a logic gate circuit.
As long as a logic gate circuit can be simulated, a Turing machine can theoretically be realized and complete all computable tasks. In other words, as long as you have more people and money, you can recruit a group of engineers to help you use crude Bitcoin Script code to simulate logic gate circuits first, and then use a huge number of logic gate circuits to implement the functions of EVM or WASM. .
(This screenshot comes from a teaching game: "Turing Complete", the core content of which is the use of logic gate circuits, especially NAND gate, build a complete CPU processor)
Someone once compared BitVM's idea to: in "I In "The World", use redstone circuits to make an M1 processor. In other words, it is equivalent to using building blocks to build the Empire State Building in New York.
(It is said that this is a "processor" that someone spent a year building in "Minecraft")
2. So, why do you have to use Bitcoin Script to simulate EVM or WASM? Isn't this very troublesome? This is because most Bitcoin Layer 2 often chooses to support high-level languages such as Solidity or Move, and what can currently be run directly on the Bitcoin chain is Bitcoin Script, a simple, non-Turing language composed of a bunch of unique opcodes. A complete programming language.

(Bitcoin Script code example)
If Bitcoin Layer 2 intends to verify fraud proof on Layer 1 like Arbitrum and other Ethereum Layer 2, and inherit the security of BTC to a great extent, it needs to directly verify "a certain disputed transaction" on the BTC chain or "A certain controversial opcode". In this way, the operation codes corresponding to the Solidity language/EVM used by Layer 2 must be put on the Bitcoin chain and run again. The problem boils down to this:
Use Bitcoin Script, a crude programming language native to Bitcoin, to achieve the effect of EVM or other virtual machines.
So, to understand the BitVM solution from the perspective of compilation principles, it translates EVM / WASM / Javascript operation codes into Bitcoin Script Opcode, logic gate circuit serves as an intermediate form (IR) between the "EVM opcode -> Bitcoin Script opcode".

(BitVM white paper talks about the general idea of executing certain "controversial instructions" on the Bitcoin chain)
< p dir="ltr" style="text-align: left;">Anyway, the final simulation effect is to put the instructions that can only be processed on EVM / WASM into the Bitcoin chain for direct processing. Although this solution is feasible, the difficulty lies in how to use a large number of logic gate circuits as an intermediate form to express all EVM / WASM operation code op codes. Moreover, using a combination of logic gate circuits to directly express some extremely complex transaction processing processes may result in a huge workload.
3. Let’s talk about another core mentioned in the BitVM white paper, which is the “interactive fraud proof” that is highly similar to Arbitrum. .
Interactive fraud proof will involve a word called assert. Generally speaking, the proposer of Layer 2 Proposer (often Acted by the sequencer), an assert assertion will be issued on Layer1 to declare that certain transaction data and state transition results are valid and correct.
If someone thinks that there is a problem with the assert submitted by the Proposer (the associated data is incorrect), a dispute will occur. At this time, the Proposer and Challenger will exchange information in a round-robin manner and perform a binary search on the disputed data to quickly locate a very fine-grained operation instruction and its associated data fragments.
For this controversial operation instruction (OP Code), it needs to be executed directly on Layer1 together with its input parameters, and the output results should be verified (Layer1 node will Compare the output results you calculated with the output results previously published by the Proposer). In Arbitrum, this is called a "one-step fraud proof".

(In Arbitrum's interactive fraud proof protocol, the data released by Proposer will be retrieved through dichotomy, the disputed instruction and execution results will be located as soon as possible, and the single-step fraud proof will be sent to Layer1 for final verification)
Reference material: Former Arbitrum technical ambassador explains Arbitrum’s component structure (Part 1)

(Arbitrum’s interactive fraud proof flow chart, the explanation is relatively rough)
Here we are, The idea of single-step fraud proof is easy to understand: the vast majority of transaction instructions that occur in Layer 2 do not need to be re-verified on the BTC chain. However, one of the controversial data fragments/operation codes must be replayed in Layer 1 when challenged.
If the detection conclusion is that there is a problem with the data previously released by the Proposer, then the assets pledged by the Proposer will be slashed; if there is a problem with the Challenger, then Slash the assets pledged by Challenger. If Prover does not respond to the challenge for a long time, he can also be Slashed.
Arbitrum achieves the above effects through contracts on Ethereum, while BitVM relies on Bitcoin Script to achieve functions such as time locks and multi-signatures.

4.After briefly talking about "interactive fraud proof" and "single-step fraud proof", we will talk about MAST trees and Merkle Proof.
As mentioned earlier, in the BitVM solution, the large amount of transaction data/huge amounts of logic gate circuits involved in Layer 2 processing off-chain will not be Directly on chain, only a few data/logic gates are on chain when necessary.
However, we need some way to prove that these "originally off-chain, now on-chain" data are not just fabricated. , this is the Commitment often mentioned in cryptography. Merkle Proof is a type of Commitment.
First, let’s talk about the MAST tree. The full name of MAST tree is Merkelized Abstract Syntax Trees, which is the form after converting the AST tree involved in the compilation principle into a Merkle Tree.
So, what is an AST tree? Its Chinese name is "Abstract Syntax Tree". Simply put, it subdivides a complex instruction into a bunch of basic operating units through lexical analysis, and then organizes it into a tree-like data structure.
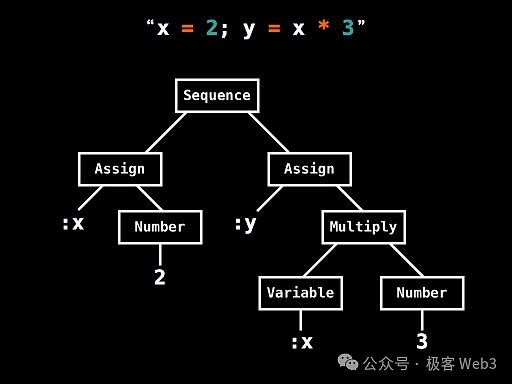
(A simple case of an AST tree. This AST tree subdivides simple operations such as x=2, y=x*3 into underlying operation codes+ Data)
The MAST tree is to Merkle the AST tree to support Merkle Proof. One advantage of the Merkle tree is that it can achieve efficient "data compression". For example, you want to publish a certain piece of data in the Merkle tree to the BTC chain when necessary, but you also want to convince the outside world that this data piece does exist in the Merkle tree and is not something you "picked up casually". How? manage?
You only need to record the Root of the Merkle tree on the chain in advance, and present Merkle Proof in the future to prove that a certain piece of data exists in the Root corresponding On the Merkle tree, just fine.
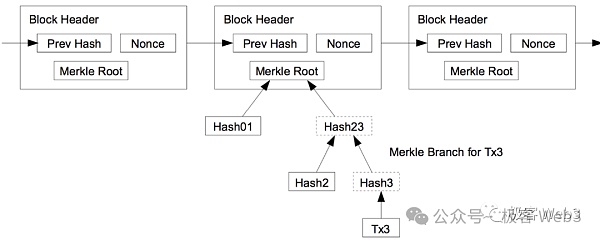
(The relationship between Merkle Proof/Branch and Root)
So, there is no need to store the complete MAST tree on the BTC chain. You only need to disclose its Root in advance to act as Commitment, and provide data fragments + Merkle Proof /Branch when necessary. This can greatly compress the amount of on-chain data and ensure that the on-chain data really exists in the MAST tree. Moreover, only disclosing a small portion of data fragments + Merkle Proof on the BTC chain instead of disclosing all data can achieve a good privacy protection effect.
Reference: Data Withholding and Fraud Proof: Why Plasma Does Not Support Smart Contracts
< img src="https://img.jinse.cn/7173446_image3.png">
( MAST tree example)
BitVM's solution attempts to express all logic gate circuits in Bitcoin scripts and then organize them It becomes a huge MAST tree. The leaf at the bottom of this tree (Content in the picture) corresponds to the logic gate circuit implemented with Bitcoin script.
Layer2's Proposer will frequently publish the root of the MAST tree on the BTC chain. Each MAST tree is associated with a transaction. , involving all its input parameters/operation codes/logic gate circuits. In a way, this is similar to Arbitrum’s Proposer publishing a Rollup Block on the Ethereum chain.
When a dispute occurs, the challenger declares on the BTC chain that he wants to challenge which Root issued by the Proposer, and then asks the Proposer to reveal the Root corresponding a piece of data. Afterwards, the Proposer presented the Merkel proof and repeatedly disclosed small data fragments of the MAST tree on the chain until the controversial logic gate circuit was jointly located with the challenger. Then you can perform Slash.
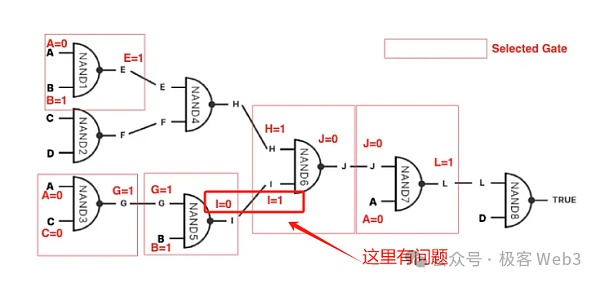
(Source: https://medium.com/crypto-garage/deep-dive-into-bitvm-computing-paradigm-to -express-turing-complete-bitcoin-contracts-1c6cb05edfca)
5. Go here , the most important part of the entire BitVM solution has basically been explained. Although some of the details are still a bit obscure, I believe readers can already get the essence and gist of BitVM. As for the bit value commitment mentioned in its white paper, it is to prevent the Proposer from "assigning both a value of 0 and a value of 1" to the input value of the logic gate when being challenged and forced to verify the logic gate circuit on the chain, causing ambiguity. Sexual confusion.
Summary: BitVM’s solution first uses Bitcoin scripts to express logic gate circuits, and then uses logic gate circuits to express the operations of EVM/other VMs code, and then use operation codes to express the processing flow of any transaction instruction, and finally organize it into a merkle tree/MAST tree.
Such a tree, if the transaction processing process expressed is very complex, can easily exceed 100 million leaves, so the Commitment should be reduced as much as possible The block space occupied and the scope of the fraud proof.
Although the single-step fraud proof only requires a very small piece of data and logic gate script onchain, the complete Merkle Tree needs to be stored in the Off-chain, in case someone challenges, the data on the tree can be onchain at any time.
Every transaction that occurs in Layer2 will generate a large Merkle Tree. The computing and storage pressure on the nodes can be imagined. Most People may not be willing to run nodes (but these historical data can be expired and eliminated, and B^2 network specially introduces zk storage proof similar to Filecoin to encourage storage nodes to save historical data for a long time)
However, optimistic Rollup based on fraud proof does not need to have too many nodes, because its trust model is 1/N, as long as 1 of N nodes is honest, If fraud proof can be initiated at critical moments, the Layer 2 network is safe.
However, there are still many challenges in the design of Layer 2 solutions based on BitVM, such as:
1.Theoretically, in order to further compress the data, there is no need to directly verify the opcode in Layer1. The opcode processing flow can be compressed again into zk proof. Let challengers challenge the verification steps of zk proof. This can greatly compress the amount of data on the chain. But the specific development details will be complicated.
2. Proposer and Challenger must interact repeatedly off the chain, how should the protocol be designed, commitment and challenges The process, how to further optimize the processing flow, requires a lot of brain cells.
References:
1.BitVM White paper
https://bitvm.org/bitvm.pdf
2.Deep dive into BitVM -Computing paradigm to express Turing-complete Bitcoin contracts-
https://medium .com/crypto-garage/deep-dive-into-bitvm-computing-paradigm-to-express-turing-complete-bitcoin-contracts-1c6cb05edfca
3.Merkelized Abstract Syntax Trees
https://hashingit.com/elements/research-resources/2014-12- 11-merkelized-abstract-syntax-trees.pdf


 JinseFinance
JinseFinance





