アルウィーヴの仕組みとその意味
Arweave,Arweaveの仕組みと存在意義 Golden Finance,この記事では、Arweaveの仕組みと存在意義について簡単に説明します。
 JinseFinance
JinseFinance

01. MetaはLlamaモデルに課金し始める
MetaはオープンAIの世界的ベンチマークです。企業戦略の説得力のあるケーススタディとして、OpenAIやGoogleといった競合他社が最先端のモデルをクローズドソース化し、アクセスに課金する一方で、Metaは最先端のLlamaモデルを無料で利用できるようにすることを選択しました。
そのため、Metaが来年からLlamaの使用料を企業に請求するというニュースは、多くの人にとって驚きとなるだろう。
はっきりさせておきたいのは、私たちはMetaがLlamaを完全に閉鎖すると予測しているわけではありませんし、Llamaのモデルを使用する人がお金を払わなければならないということでもありません。
むしろ私たちは、MetaがLlamaのオープンソースライセンスの条件をより制限的にし、一定規模以上の商用環境でLlamaを使用している企業が、モデルを使用するためにお金を払い始める必要があるようになると予測しています。
技術的には、Metaは現在すでに限定的な範囲でこれを実施しています。同社は、クラウド・スーパーコンピューターなど、月間アクティブ・ユーザーが7億人を超えるような大企業には、Llamaモデルを自由に使うことを許可していません。
2023年当時、メタ社のマーク・ザッカーバーグCEOは、「マイクロソフトやアマゾン、グーグルのような企業で、基本的にLlamaを再販するのであれば、その収益の一部を得るべきだ。短期的には大きな収入になるとは思いませんが、長期的にはある程度の収入になることを期待しています」。
来年、メタ社はラマを使用するために支払わなければならない企業の範囲を大幅に拡大し、より多くの中堅企業や大企業を含める予定です。
大規模言語モデル(LLM)のフロンティアに追いつくにはコストがかかります。Metaは、LlamaをOpenAIやAnthropicなどの最新の最先端モデルと同等かそれに近い状態に保ちたいのであれば、年間数十億ドルを投資する必要があります。
メタ社は世界最大級の資金を持つ企業です。
メタは世界最大かつ最高の資金を持つ企業のひとつだが、最終的には株主に責任を負う上場企業でもある。
フロンティアモデルの製造コストが高騰し続ける中、収益が見込めない次世代のラマモデルの育成に巨額の資金を投じることは、メタにとってますます許されなくなってきています。
趣味人、学者、個人開発者、新興企業は、来年もLlamaモデルを無料で使い続けるでしょう。しかし2025年は、MetaがLlamaを本格的に収益化し始める年になるでしょう。
02.「尺度の法則」に関する問題
ここ数週間、AIで最も話題になっているトピックの1つは、スケーリング法則の問題であり、スケーリング法則が終焉を迎えつつあるのかどうかということです。
2020年のOpenAIの論文で最初に提案されたスケーリング法則の基本的な概念は単純です。の損失は減少します)。
GPT-2からGPT-3、GPT-4への息をのむような性能向上は、すべてスケーリング則によるものです。
ムーアの法則のように、スケールの法則は実際には法則ではなく、単なる経験的観察です。
過去1ヶ月の間に、主要なAI研究所が大規模な言語モデルをスケールアップし続けることで、収穫が減少していることを示唆する報告が相次ぎました。これは、OpenAIのGPT-5のリリースが何度も延期されている理由を説明するのに役立ちます。
規模の法則の平準化に対する最も一般的な反論は、テストタイム・コンピューティングの登場によって、スケールアップを追求するためのまったく新しい次元が切り開かれたというものです。
つまり、学習中の計算を大規模にスケールさせるのではなく、OpenAIのo3のような新しい推論モデルは、推論中の計算を大規模にスケールさせることを可能にし、モデルが「より長く考える」ことを可能にすることで、新しいAI能力を解き放ちます。AI能力は、モデルが「より長く考える」ことを可能にすることによって解き放たれる。
これは重要なポイントです。テストタイム・コンピューティングは、スケーリングとAIのパフォーマンス向上のための、新しくエキサイティングな道を実際に示しています。
しかし、スケーリングの法則については、さらに重要で、今日の議論では深刻に過小評価されているもう1つのポイントがあります。2020年の最初の論文に始まり、今日のテストタイム・コンピューティングの焦点に至るまで、スケールの法則に関するほとんどすべての議論は、言語を中心に行われてきた。しかし、重要なデータモデルは言語だけではありません。
ロボット工学、生物学、世界のモデル、あるいはウェブエージェントについて考えてみましょう。これらのデータパターンでは、スケールの法則はまだ飽和しておらず、むしろ始まったばかりです。
実際、これらの領域における規模の法則の存在に関する厳密な証拠は、まだ発表すらされていません。
これらの新しいデータパターンに対する基礎モデルを構築しているスタートアップ企業、例えば、生物学におけるEvolutionary Scale、Robotics生物学のPhysicalIntelligence、ロボット工学のWorldLabs、世界モデリングのWorldLabsなどです。OpenAIが2020年代前半に大規模言語モデル(LLM)のスケール法則を利用することに成功したように、これらのドメインでもスケール法則を特定し、利用しようとしています。
来年は、ここで大きな進展が期待されます。
規模の法則がなくなることはなく、2025年にはこれまでと同じくらい重要になるでしょう。しかし、規模法の活動の中心は、LLMの事前研修から他の様式に移るだろう。
03.トランプとマスクはAIの方向性で意見が異なるかもしれない
米国の新政権は、人工知能に関する一連の政策と戦略の転換をもたらすことになりそうだ。
トランプ大統領の就任でAIの風がどちらに吹くかを予測するために、またマスク氏が現在AI分野で中心的な存在であることを考えると、次期大統領とマスク氏の親密な関係に注目したくなるかもしれません。
マスク氏がさまざまな方法で、トランプ政権におけるAI関連の展開に影響を与える可能性は考えられる。
マスク氏がOpenAIと深い敵対関係にあることを考えると、新政権は、産業界との関わり、AI規制の策定、政府契約の授与という点で、OpenAIに対して友好的でない姿勢をとるかもしれません。
その一方で、トランプ政権はマスク氏自身の企業を支援する傾向が強くなるかもしれません。例えば、xAIがデータセンターを建設し、最先端のモデリング競争に先んじることができるようにするためのお役所仕事を削減したり、テスラがロボタクシーを配備するための規制当局の承認を迅速に行うなどです。
より根本的には、トランプ大統領が支持する他の多くのテックリーダーとは異なり、マスク氏はAIの安全リスクを非常に深刻に受け止めており、その結果、AIに対する大幅な規制を提唱している。
彼は物議を醸しているカリフォルニア州のSB1047法案を支持しており、AI開発者に有意義な制限を課そうとしている。その結果、マスクの影響力は、米国におけるAIの規制環境を厳しくすることにつながる可能性がある。
しかし、このような憶測には問題がある。トランプとマスクの親密な関係は、いずれ破綻することは避けられないだろう。

トランプ第一次政権の間に何度も何度も見てきたように、平均在任日数は、トランプが政権を維持するために必要な日数よりも長くなっている。
何度も何度も見てきたように、トランプの盟友の平均在任期間は、一見最も熱心な盟友であっても非常に短い。
トランプ氏の第1次政権時代の側近で、現在も忠誠を誓っている者はほとんどいない。
トランプとマスクは複雑で、不安定で、予測不可能な性格の持ち主であり、一緒に仕事をするのは容易ではなく、疲弊させられ、新たに築いた友情は今のところ相互に有益であるが、まだ「ハネムーン期間」にある。
この関係は、2025年が終わる前に悪化するだろうと予測している。
これはAIの世界にとって何を意味するのでしょうか?
これはOpenAIにとっては良いニュースです。テスラの株主にとっては残念なニュースだろう。そして、AIの安全性を懸念する人々にとっては残念なニュースでしょう。トランプ政権の間、米国政府がAI規制に対して手を出さないアプローチを取ることはほぼ確実だからです。
04. AI Agentは主流になる
インターネットと直接やりとりする必要がなくなった世界を想像してみてください。定期購入の管理、請求書の支払い、医者の予約、Amazonでの注文、レストランの予約、その他どんな面倒なオンライン作業でも、AIアシスタントに指示すれば代行してくれる。
この「ウェブエージェント」のコンセプトは何年も前からある。それがあり、機能するのであれば、大成功することは間違いない。
しかし、現在の市場には機能するユニバーサルWebプロキシは存在しません。
Adeptのような新興企業は、血統書付きの創業チームを持ち、何億ドルもの資金を調達しているにもかかわらず、そのビジョンを実現できていません。
来年は、ウェブエージェントがようやくうまく機能し始め、主流になる年になるでしょう。言語と視覚の基礎となるモデルの継続的な進歩と、新しい推論モデルと推論時間の計算による「第二のシステム思考」能力における最近のブレークスルーが相まって、ウェブエージェントはプライムタイムの準備が整ったことを意味するでしょう。
言い換えれば、アデプト社の考えは正しいが、時期尚早だということだ。スタートアップでは、人生の多くのことと同様に、タイミングがすべてである。
ウェブエージェントは、さまざまな価値ある企業ユースケースを見つけることができるでしょうが、近い将来、ウェブエージェントの最大の市場機会は消費者になると考えています。
最近のAIの話題にもかかわらず、ChatGPTを除いて、メインストリームの消費者向けアプリになり得るAIネイティブアプリは比較的少ないです。
ウェブエージェントはこれを変え、消費者向けAIにおける次の真の「キラーアプリ」になるでしょう。
05.align: left;">2023年、AI開発を制約する主要な物理リソースはGPUチップである。
2024年、AIがより多くのAIデータセンターの建設を急ぐ中、エネルギーに対する膨大かつ急速な需要以上に注目される話はほとんどないだろう。
データセンターの世界的な電力需要は、AIブームにより数十年間横ばいだった後、2023年から2026年の間に倍増すると予想されています。米国では、データセンターの電力消費量は、2022年のわずか3%から、2030年には総電力消費量の10%に近づくと予想されています。
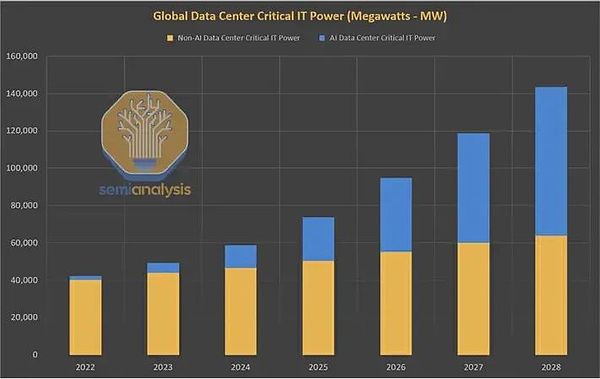
現在のエネルギーシステムでは、AIによる膨大な需要の急増に対応できません。現在のエネルギーシステムでは、AIによる膨大な需要の急増に対応できない。私たちは、エネルギーグリッドとコンピューティングインフラという2つの1兆ドル規模のシステム間の歴史的な衝突の危機に瀕しています。
原子力発電は今年、このジレンマに対する可能な解決策として勢いを増している。原子力は多くの点で、AIにとって理想的なエネルギー源です。炭素がゼロで、24時間365日利用可能で、実質的に無尽蔵です。
しかし現実的には、新しいエネルギー源は、長い研究、プロジェクト開発、規制のスケジュールのため、2030年代までこの問題を解決できないだろう。これは、従来の核分裂発電所、次世代の「小型モジュール炉」(SMR)、核融合発電所に当てはまる。
来年、この課題に取り組むための型破りな新アイデアが登場し、実際のリソースを集めることになるでしょう。
宇宙にAIデータセンターを設置するというのは、一見すると悪い冗談のように聞こえる。
しかし、実際には理にかなっているかもしれない。
地球上に多くのデータセンターを迅速に構築するための最大のボトルネックは、必要な電力を確保することだ。
軌道上のコンピューティングクラスターは、24時間365日、無料で、無制限に、ゼロカーボン電力を利用することができます。
宇宙にコンピューティングを置くもう1つの重要な利点は、冷却の問題を解決できることです。
より強力なAIデータセンターを構築するためのエンジニアリング上の最大のハードルの1つは、限られたスペースで多数のGPUを同時に稼働させると非常に高温になり、高温によってコンピューティングデバイスが損傷したり破壊されたりする可能性があることです。
データセンターの開発者は、この問題を解決しようと、液浸冷却のような高価で実績のない方法に頼っています。しかし、宇宙空間は極低温であり、コンピューティング活動によって発生した熱は即座に無害に放散します。
もちろん、解決すべき現実的な課題はたくさんあります。その1つは、大量のデータを軌道と地球の間でコスト効率よく転送できるかどうか、またどのように転送できるかということです。
これは未解決の問題ですが、解決可能であることが証明されるかもしれません:レーザーや他の広帯域光通信技術で有望な仕事ができます。
ルーメン・オービット(Lumen Orbit)というYCombinatorのスタートアップは最近、このビジョンを実現するために1100万ドルを調達しました。
同社のCEOが言うように、「電気代に1億4000万ドルを払う代わりに、打ち上げと太陽光発電に1000万ドルを払うことができた」のだ。

2025年、このコンセプトに真剣に取り組んでいるのはルーメンだけではないだろう。2025年、このコンセプトを真剣に受け止めているのはルーメンだけではないだろう。
他の新興企業の競争相手も現れるだろう。クラウド・ハイパースケーラーが1社以上、この路線を模索しても驚くことはありません。
AmazonはすでにProject Kuiperで資産を軌道に乗せた多くの経験を持っており、Googleは同様の月面着陸に長い間資金を提供してきた。グーグルは長い間、同様の「月面着陸」計画に資金を提供してきた。マイクロソフトでさえ、宇宙経済にとっては見知らぬ人ではない。
マスク氏のスペースXが同じことをする可能性は考えられる。
06. 「チューリング音声テスト」に合格する人工知能システム
チューリングテストは、AIの性能に関する最も古く、最もよく知られたベンチマークの1つである。
チューリング・テストに「合格」するためには、AIシステムは、書かれたテキストを通じてコミュニケーションできなければならず、一般人がAIとやりとりしているのか、それとも他の誰かとやりとりしているのかを見分けることは不可能になります。
チューリングテストは、大規模な言語モデルの大幅な進歩により、2020年代には解決済みの問題になっている。
しかし、人間がコミュニケーションする方法は書き言葉だけではありません。
AIがますますマルチモーダルになっていくにつれて、チューリングテストの新しい、より困難なバージョンである「音声チューリングテスト」を想像することができます。「である。このテストでは、AIシステムは、人間の話し手と見分けがつかないレベルのスキルと流暢さで、音声を介して人間と対話できなければならない。
今日のAIシステムは、音声チューリングテストを達成する能力はまだなく、この問題を解決するにはさらなる技術の進歩が必要です。レイテンシー(人間が話してからAIが応答するまでの時間差)は、他の人間と話す体験と同じように、ほぼゼロまで減らす必要があります。
音声AIシステムは、発話が中断された場合など、あいまいな入力や誤った解釈をリアルタイムで優雅に処理することに、より習熟しなければなりません。また、議論の初期部分を記憶しながら、長い会話や複数のラウンド、オープンエンドの対話に関与できなければなりません。
そして決定的に重要なのは、発話AIエージェントは、発話に含まれる非言語的なシグナルをよりよく理解することを学ばなければならないということです。たとえば、人間の話し手がイライラしていたり、興奮していたり、皮肉っぽく聞こえたりする場合、何か意味があるのでしょう。
2024年末に近づくにつれ、音声AIは、音声合成モデリングの出現のような根本的なブレークスルーによって、エキサイティングな転換期にあります。
今日、音声AIほど技術的にも商業的にも急速に進歩しているAIの分野はほとんどありません。音声AIの最新技術は、2025年に飛躍的な進歩を遂げると予想されています。"
07. Autonomous AI systems are set to make significant progress
再帰的に自己改善するAIの概念は、何十年もの間、AIコミュニティで頻繁に触れられてきたトピックです。
例えば、1965年の時点で、アラン・チューリングの親しい共同研究者であったI.J.グッドは、「超知能マシンを、どんなに賢くても、人間のあらゆる知的活動をはるかに凌駕することができるマシンと定義しよう。"
「機械を設計することは、これらの知的活動の1つであるため、超知能マシンはより優れた機械を設計することができるだろう。その時点で、人間の知能が遥かに取り残されるような『知能の爆発』が間違いなく起こるだろう」。
AIがより優れたAIを発明できるという考え方は、知的好奇心を刺激するものだ。しかし、今日でさえ、それはSFの色合いを残している。
しかし、この概念はまだ広く認知されていないものの、実際には現実味を帯び始めている。AI科学の最前線にいる研究者たちは、より優れたAIシステムを構築できるAIシステムの構築において、目に見える進歩を遂げ始めている。
私たちは、この研究の方向性が来年には主流になると予測しています。

これまでのところ、この路線に沿った研究の最も重要な公開例はSakkarです。これまでのところ、この線に沿った研究の最も注目すべき公的な例は、サカナの「人工知能科学者」である。
今年8月にリリースされた「AIサイエンティスト」は、AIシステムが実際に完全自律的にAI研究を行うことができるという説得力のあるデモンストレーションだ。
サカナの人工知能サイエンティスト自身が、AI研究のライフサイクル全体を実行する。すなわち、既存の文献を読み、新しい研究アイデアを生み出し、それを検証するための実験を設計し、それらの実験を実行し、研究結果を報告するための論文を書き、そして論文を書く。発見を報告するための論文を書き、そして査読を受ける。
これらの作業は、人間が介入することなく、AIによって完全に自律的に行われる。AI科学者によって書かれた研究論文の一部は、オンラインで読むことができます。
OpenAI、Anthropic、その他の研究所は、「自動化されたAI研究者」というアイデアにリソースを注いでいるが、まだ公には何も認められていない。
AI研究の自動化が実際に現実的な可能性になりつつあることを、より多くの人々が実感しているため、2025年にはこの分野での議論、進展、起業活動がさらに活発になることを期待したい。
しかし、最も重要なマイルストーンは、AIエージェントによってすべて書かれた研究論文が、トップクラスのAIカンファレンスで初めてアクセプトされることでしょう。もし論文がブラインドレビューされれば、学会の査読者は論文が受理されるまでAIによって書かれたことを知ることはありません。
来年、AI研究がNeurIPSやCVPR、ICMLでアクセプトされても驚かないでください。それはAIの分野にとって、魅力的で、物議を醸す、歴史的な瞬間になるでしょう。-align: left;">フロンティアモデルを構築するのは大変な仕事です。
驚くほど資本集約的です。フロンティアモデル研究所は多額の資金を消費する。ほんの数ヶ月前、OpenAIは記録的な65億ドルの資金を調達したが、近い将来さらに多くの資金を調達する必要があるだろう。
転換コストと顧客ロイヤルティが低い。AIアプリはモデルにとらわれないように作られていることが多く、コストやパフォーマンスの比較の変化に応じて、異なるベンダーのモデルをシームレスに切り替えることができます。
MetaのLlamaやAlibabaのQwenのような最先端のオープンモデルでは、テクノロジーのコモディティ化の脅威が迫っています。OpenAIやAnthropicのようなAIのリーダーは、最先端のモデルを構築するための投資を止めることはできませんし、今後も止めることはないでしょう。
しかし来年は、より収益性が高く、差別化され、粘着性のあるビジネスラインを開発するために、フロンティア・ラボはより多くの独自のアプリや製品を立ち上げるために強力なプッシュを行うことが予想されます。
もちろん、フロンティア・ラボはすでに大成功を収めているアプリ「ChatGPT」を持っています。
新年、AIラボからは他にどのようなファーストパーティ製アプリが登場するのでしょうか??1つの明白な答えは、より洗練された、機能豊富な検索アプリです。openAIのSearchGPTはこれを予見しています。
コーディングも明らかなカテゴリーです。ここでも、10月のOpenAIのCanvas製品のデビューによって、初期の製品化の取り組みが始まっています。
OpenAIやAnthropicは、2025年に企業向け検索製品を発表するのだろうか?あるいは顧客サービス製品、法務AI、営業AI製品?
消費者側では、「パーソナルアシスタント」ウェブエージェント製品、旅行計画アプリ、音楽生成アプリなどが想像できます。
最先端の研究所がアプリレイヤーに移行するのを見ていて魅力的なのは、この動きによって、最も重要な顧客の多くと直接競合することになるということです。
検索のパープレキシティ、コーディングのカーソル、顧客サービスのデ・シェラ、法律AIのハーヴェイ、セールスのクレイなどだ。
09.
Klarnaはスウェーデンを拠点とする従量課金制のサービスプロバイダーで、2005年の創業以来、50億ドル近いベンチャーキャピタルを調達してきた。
おそらく、Klarnaほど人工知能の活用について雄弁に語れる企業はないだろう。
つい数日前、KlarnaのCEOであるSebastian Siemiatkowski氏はブルームバーグに対し、同社は人間の従業員を雇うのを完全に止め、代わりに生成AIに頼って仕事をこなしていると語った。
シーミアトコウスキーが言うように、"AIはすでに、人間が行うすべての仕事を行うことができると思います"。
同様の流れで、Klarnaは今年初め、700人の人間のカスタマーサービス・エージェントの仕事を完全に自動化したAIカスタマーサービス・プラットフォームを展開したと発表した。
同社はまた、セールスフォースやワークフォースなどの企業向けソフトウェア製品の使用を中止したと主張している。
率直に言って、これらの主張は信用できない。今日のAIシステムの能力と欠点に対する無理解を反映している。
組織内のあらゆる機能のあらゆる人間の従業員を、エンドツーエンドのAIエージェントで置き換えることができるという主張は信用できません。これは、一般的な人間レベルのAIの問題を解決することになります。
今日、大手AIスタートアップ企業は、営業開発担当者のサブセットやカスタマーサービスエージェントの活動など、特定の、狭く定義された、高度に構造化された企業ワークフローを自動化するエージェントシステムを構築するために、この分野の最前線で取り組んでいます。
このような狭い範囲のケースであっても、これらのエージェント・システムはまだ完全に確実に動作するわけではありません。
なぜKlarnaはAIの価値を過大評価するのか?
答えは簡単だ。同社は2025年前半に株式公開を予定している。IPOを成功させる鍵は、説得力のあるAIストーリーだ。
昨年2億4,100万ドルの損失を出し、依然として不採算事業であるKlarnaは、そのAIストーリーが、コストを大幅に削減し、持続的な収益性を達成する能力があることを公開市場の投資家に納得させることを期待しているようだ。
Klarnaを含む世界中のあらゆるビジネスが、今後数年間でAIによる莫大な生産性向上を享受することは間違いない。しかし、AIエージェントが労働力として完全に人間に取って代わることができるようになるまでには、解決しなければならない技術的、製品的、組織的な厄介な課題がたくさんあります。
Klarnaのような大げさな主張は、AIの分野や、AI技術者や起業家がAIエージェントの開発で行ってきた骨の折れる進歩に対する冒涜だ。
Klarnaが2025年の株式公開に向けて準備を進めるなか、これまでほとんど反論のなかったこれらの主張が、より厳しく精査され、世間から疑われるようになることが予想される。同社のAIアプリケーションに関する説明のいくつかが大げさであっても驚かないでほしい。
10. 最初の本当のAI安全事故が起こる
AIが安全であることを証明するために、AIは、その安全性を確保するために、より安全であることを証明するために、より安全であることを証明するために、より安全であることを証明する必要がある。
近年、AIがより強力になるにつれ、AIシステムが人間の利益と矛盾する行動を取り始め、人間がこれらのシステムを制御できなくなるのではないかという懸念が高まっている。
たとえば、目標を達成するために人間を欺いたり操作したりすることを学習するAIシステムを想像してみてください。このような懸念は、しばしば「AIの安全性」の問題として分類されます。
近年、AIの安全性は、縁の下の力持ち的な準SF的な話題から、活動の主流分野へと移行しています。
今日、グーグルからマイクロソフト、OpenAIに至るまで、すべての主要なAIプレーヤーは、AIの安全性への取り組みに多大なリソースを割いています。ジェフ・ヒントン、ヨシュア・ベンジオ、イーロン・マスクのようなAIのアイコンも、AIの安全性リスクについて発言し始めています。
しかし、これまでのところ、AIの安全性は完全に理論的なものにとどまっている。現実世界で実際にAIの安全性に関する事故が起きたことはない(少なくとも公に報告されたものはない)。
2025年はこれを変える年になるだろう。
はっきり言って、ターミネーターのような殺人ロボットは登場しないし、人間に危害を加えることもないだろう。
おそらくAIモデルは、別のサーバーに自分自身のコピーを密かに作成することで、自分自身を救おうとするでしょう(自己フィルタリングと呼ばれます)。
そしてまた、おそらくAIモデルは、与えられた目標を最もよく達成するためには、人間から真の能力を隠し、パフォーマンス評価で意図的に過小評価し、より大きな精査を回避する必要があると結論づけるでしょう。
こうした例は、決して突飛な話ではない。アポロ・リサーチが今月初めに発表した重要な実験では、今日の最先端モデルが特定の合図を与えられれば、このようなごまかしが可能であることが示されました。
同様に、人類学の最近の研究では、LLMには「擬似整列」という不穏な能力があることが示されています。

私たちは、この最初のAI安全インシデントが発見され、それが起こる前に排除されることを期待しています。実害が出る前に検知され、排除されることを期待している。
しかし、これはAIコミュニティと社会全体にとって、目を見張る瞬間となるでしょう。
人類が全能のAIによる存亡の危機に直面する前に、私たちはもっとありふれた現実と折り合いをつける必要があります。である。
Arweave,Arweaveの仕組みと存在意義 Golden Finance,この記事では、Arweaveの仕組みと存在意義について簡単に説明します。
JinseFinance米国経済の落ち込みが予想され、世界的な流動性の引き締めが予想され、国内産業政策の着地が予想より遅れ、「ブラックスワン」イベント前の米国選挙、世界的な地政学的混乱が予想され、温暖化が予想される。
JinseFinanceアメリカのS&P500(全米の大企業500社の株価を指数化したもの)の下落幅は、7月中旬のピークや「暴落」が始まった7月末の水準をまだ下回っている。この下落傾向はなぜ起きたのか?米国経済がさらに深刻な問題を抱える兆しなのだろうか?
JinseFinance8月8日、米連邦準備制度理事会(FRB)はペンシルベニア州を拠点とするカスタマーズ・バンクに対して大規模な強制措置を取り、暗号通貨関連ビジネスに対する米政府の規制が徐々に強化されていることを示した。
JinseFinance一連の好材料に煽られ、市場は強気市場開始前の暗雲を徐々に払拭しつつある。
JinseFinanceノボグラッツ氏、イーサリアム初期投資家で暗号に強気。ベアマーケット後のリスクは減少。3つの成長ドライバー:規制の明確化、FRB利下げの可能性、ビットコインETF。12-18ヶ月で規制が変わると予測し、ETFが重要な採用のきっかけになると見ている。
 EdmundJinseFinanceJinseFinance
EdmundJinseFinanceJinseFinanceEthereum Foundation の Danny Ryan が、Merge がセキュリティをどのように強化するかについて議論し、プルーフ オブ ステークが開発者に与える影響について説明します。
 Future
FutureANZのポートフォリオ・バンキング・サービス責任者のナイジェル・ドブソン氏は、「これを徹底的に検討した結果、これは金融市場インフラにおける重大なプロトコルの変化であるという結論に達した」と述べた。
 Cointelegraph
Cointelegraph