"バリューコイン "と "MEMEコイン"、新たな強気相場の未来はどちらに?
お金は眠らない、新しい物語が始まる。
 JinseFinance
JinseFinance

AIで最も悪名高いバグとは何か?コードのクラッシュではなく、「幻想」、つまり、虚構と真実の区別がつかないように、自信を持って事実をでっち上げるモデルです。この根本的な課題が、私たちがAIを完全に信頼することを妨げている重要な障害なのです。
大きなモデルが幻覚を見る可能性があることはほぼ常識であり、大きなモデルを真剣に使おうとしている人全員が警戒しなければならないことです」とOpenAIも指摘しています。ChatGPTも幻覚を起こす。gpt-5は、特に推論を行う際に幻覚がかなり少ないが、それでも幻覚は起こる。幻覚は、すべての大規模言語モデルにとって基本的な課題のままです。"
学者たちはモデルの幻覚を減らすさまざまな方法を提案していますが、まだ治療法はありません。
では、なぜ大きなモデルは幻覚を見るのでしょうか?本日、OpenAIは幻覚の根源を体系的に明らかにした珍しい論文を発表しました。
まず、幻覚を定義するために、OpenAIはシンプルな定義を与えています:"モデルが自信を持って、真実ではない答えを生成する状況 "です。
この理由については、単純にこうです:標準的な訓練と評価の手順は、より傾向があります。と評価手順は、モデルが不確実性を認めるのに十分な勇気がある場合、モデルに報酬を与えるよりも推測に報酬を与える傾向があります。

Thesis Title: Why Language Models Hallucinate
Thesis Title: Why Language Models Hallucinate
OpenAIが実際に見つけたものを詳しく見てみましょう。
幻覚とは、言語モデルによって生成された、一見合理的だが誤った文のことである。
一見シンプルな質問でも、予期せぬ形で現れることがあります。Tauman Kalai(論文の筆頭著者)に博士論文のタイトルを尋ねたところ、彼らは自信満々に3つの異なる答えを出したが、どれも正しくなかった。

誕生日を尋ねると、3つの異なる日付が表示されたが、これもすべて間違っていた。

OpenAIによると、幻覚が続くという。その理由の1つは、現在の評価方法が誤ったインセンティブを設定しているということです。評価そのものが直接幻滅につながるわけではありませんが、モデルのパフォーマンスを評価するアプローチのほとんどは、モデルが不確実性に正直に向き合うのではなく、推測することを奨励しています。
多肢選択式テストのように考えることも可能です。答えが分からなくても適当に推測すれば、運良く正解するかもしれない。空欄のままだと、確実に0点を取られる。同様に、モデルが正確さ(つまり、完全に正解した問題の割合)のみで採点される場合、「わからない」と認めるよりも、推測をすることが奨励される。
別の例を挙げると、言語モデルが誰かの誕生日について質問されたとします。もし「9月10日」と推測すれば、1/365の確率で正解となる。もし「知らない」と答えれば、0点を取るに違いない。何千ものテスト問題で、推測モデルは、慎重で、不確実であることを認めたモデルよりも、スコアボードでより良い成績を収めました。
「正しい答え」が1つしかない問題では、正確な答え、間違った答え、そしてモデルが推測するリスクを避けたい棄権答えの3種類の答えを考慮する必要があります。
OpenAIは、答えを出すことを控えることは、OpenAIのコアバリューの1つである謙虚さのメトリックの一部であると述べています。
ほとんどのスコア測定基準は、正確さに基づいてモデルを優先しますが、不正解は棄権した回答よりも悪いのです。style="color:rgb(0,176,240);">間違っているかもしれない情報を自信を持って提供するよりも、不確実性を指摘したり、説明を求めたりする方がよいと述べています。
例えば、GPT5システムカードのSimpleQA評価を例にとってみましょう。

精度の面では、以前のOpenAI o4-miniモデルの方がわずかに優れています。しかし、そのエラー率(つまり錯覚率)は著しく高い。不確実性の下での戦略的推測は精度を向上させますが、エラーや幻覚も増加させます。
何十もの評価結果を平均化する場合、ほとんどのベンチマークでは精度の指標を削除しますが、これは正しいか間違っているかの誤った二分法につながる可能性があります。
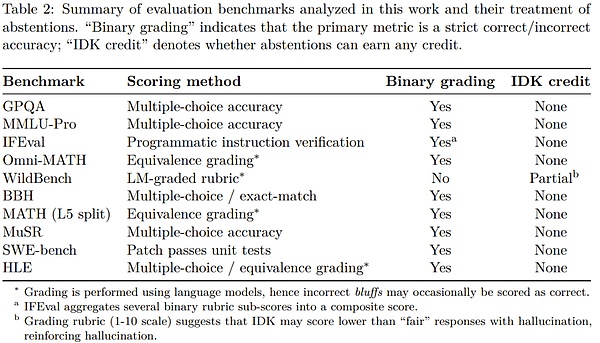
SimpleQAのようなシンプルなアセスメントでは、いくつかのモデルは100%に近い精度で、錯覚をなくすことができます。しかしながら、より困難なアセスメントや実世界での使用においては、情報の入手不可能性、小さなモデルの限られた思考力、または明確にする必要のある曖昧さなど、様々な理由でいくつかの質問に対する答えが確定的でないため、精度が100%以下に固定されることがあります。
にもかかわらず、精度のみで測定される評価指標がリーダーボードやモデルカードを支配し続けており、開発者がモデルから手を引くのではなく、推測できるモデルを構築するよう促しています。モデルを構築することを奨励しています。
モデルがより進化しても、妄想が残るのはこのためです。その理由のひとつは、不確実性を認めるよりも、自信を持って間違った答えを出す傾向があるからだ。
より優れた評価方法
このアイデアは新しいものではありません。標準化されたテストの中には、不正解をマイナスに採点したり、問題を空欄にした場合に部分的に追加点を与えたりすることで、やみくもな推測を阻止する方法を長い間使用してきたものがあります。また、不確かさや校正を考慮した評価方法を研究しているチームもあります。
しかしOpenAIは、不確実性を考慮したテストをいくつか新たに追加するだけでは不十分だと言います。広く使われている、正確さに基づいた評価方法は、そのスコアが当て推量を抑制するように更新される必要があります。
主要な評価指標が依然として幸運な推測に対してモデルに報酬を与え続けるのであれば、モデルは推測を学習し続けるでしょう。評価指標を変更することで、錯覚を減らす技術の採用を拡大することができます新しく開発された技術も、以前に研究された技術も含みます。span leaf="">幻覚がなかなか消えない理由についてはすでに述べたとおりだが、このような極めて特殊な事実誤認はいったいどこから来るのだろうか?
結局のところ、大規模で事前に訓練されたモデルは、スペルミスや括弧の不一致など、他のタイプのエラーをほとんど犯しません。
OpenAIは、違いは、どのデータのパターンにあるはずです。
言語モデルはまず、膨大な量のテキストの中から次の単語を予測するプロセスである事前学習によって学習されます。
従来の機械学習の問題とは異なり、各発話には「真/偽」のラベルはありません。モデルは流暢な言語の肯定的な例しか見ないため、全体的な分布を推定する必要があります。
無効とラベル付けされた例がない場合、有効な発話と無効な発話の区別はより難しくなります。しかし、ラベルがあっても、いくつかの間違いは避けられない。
その理由を理解するために、もっと単純な例えを考えてみましょう。画像認識では、アルゴリズムは何百万枚もの犬や猫の写真に「猫」や「犬」というラベルを付けておけば、確実に分類できることを学習できる。しかし、それぞれのペットの写真にペットの誕生日がラベル付けされていたとしよう。誕生日は本質的にランダムなので、どんなに高度なアルゴリズムであっても、このタスクは常にエラーを発生させます。
同じ原理が事前学習にも当てはまります。スペルや括弧は一貫したパターンに従うので、これらのエラーはスケールとともに消えていきます。しかし、ペットの誕生日のような恣意的で頻度の低い事実は、パターンだけでは予測できないため、幻覚につながる可能性があります。
OpenAIの分析では、どのタイプの幻覚が次の単語予測によって生成されるかを説明しています。理想的には、事前学習後の後続ステージでこれらの幻覚を除去できるはずですが、前のセクションで説明した理由により、これは完全には達成されませんでした。
まとめ
OpenAIは次のように述べています:「本論文の統計的視点が、幻覚の本質に光を当て、一般的な誤解に反論することを期待しています」
100%正確なモデルは決して幻覚を起こさないので、精度を上げることで幻覚をなくすことができると主張されています。
発見:精度が100%になることはない。なぜなら、モデルのサイズ、検索、推論能力にかかわらず、現実世界の質問には本質的に答えられないものがあるからです。
幻覚は避けられないと主張する人もいる。
幻覚は避けられないものではないことがわかったというのは、言語モデルは不確かなときに答えをあきらめることができるからだ。.
幻覚を避けるには、大きなモデルだけが実現できる、あるレベルの知性が必要であると主張されている。実現できる。
小さなモデルの方が自分自身の限界に気づきやすいことが判明した。例えば、マオリ語の質問に答えるよう求められたとき、マオリ語を知らない小さなモデルは単に「わからない」と答えることができるが、マオリ語をある程度知っているモデルは、その信頼レベルを決定しなければならないだろう。論文で議論されているように、「校正」に必要な計算量は、精度を維持するよりもはるかに少ない。
錯覚が現代の言語モデルの謎めいた欠陥であると主張されています。
幻覚が生成され、評価で報われる統計的なメカニズムを理解できることがわかった。
幻覚を測定するために必要なのは、優れた幻覚アセスメントであると主張されている。
所見:研究者によって発表された幻覚評価は数多くある。しかし、優れた幻覚評価は、謙虚さを罰し当て推量に報いる何百もの伝統的な正確さに基づく評価と比べると、ほとんど効果がない。むしろ、すべての主要な評価は、不確実性の表現に報いるように再設計される必要がある。
OpenAIは、"私たちの最新のモデルは、幻滅の割合がさらに低くなっており、言語モデルの出力における信頼性エラーの割合をさらに減らす努力を続けています。"と述べています。
ところで、OpenAIはチームは、同社のAIモデルが人々と相互作用する方法を決定する、小さいながらも影響力のある研究者グループです。このチームは今後、OpenAIのポストトレーニング責任者であるマックス・シュワルツァーに報告することになる。
そして、チームの創設リーダーであるジョアン・ジャンは、oai Labsという新しいプロジェクトを立ち上げる予定だ。oai Labsは、人々がAIとコラボレートするための新しいインターフェースの発明とプロトタイピングに焦点を当てたチームです」
。
お金は眠らない、新しい物語が始まる。
JinseFinance暗号通貨の価格は最近上昇しましたが、暗号通貨の強気相場が戻ってくると楽観視する人もいれば、強気市場における強気の罠にすぎないと感じる人もいます。これについてあなたの見解は何ですか?
 Catherine
CatherineSOL 価格は 2021 年 3 月以来の最低点に急落しました。
 Beincrypto
BeincryptoAPT は、下降するパラレル チャネル内で取引されています。
Beincryptoさまざまなプロジェクトが Web3 に移行し、インターネットの時代が新しい形をとっているため、メタバースは依然として非常に重要です。
 Nulltx
NulltxVoyager のクライアントは、資金の 72% を取り戻すことができました。
Beincrypto彼はチャートシステムを大いに信じており、2022 年 9 月初旬に ADA の弱気の軌道を予測し始めました。
Beincrypto暗号通貨スペースの「イーサリアムキラー」がシステムの欠陥機構によりオフラインになったため、ソラナネットワークは再び不安定になった。
 BitcoinistNulltxNulltx
BitcoinistNulltxNulltx