Grayscaleがビットコイン、イーサリアム、ソラナ、XRP、カルダノを対象としたETFの早期SEC承認を獲得 - すぐに多くのアルトコインETFが続くか?
SECはGrayscaleのデジタル大型株ファンドをETF化する計画を承認し、投資家は主要暗号通貨のバスケットに簡単にアクセスできるようになった。この動きは、ソラナ、XRP、カルダノのようなアルトコインを含む、より多くの暗号ETFが米国で承認されることにつながる可能性がある。
 Anais
Anais

DeepSeek-R1モデルを使用したことがある人は、答えを出すまでの思考プロセスに不慣れではないことが、DeepSeek-R1を含むLarge Reasoning Model(LRM)が高く評価されている理由の一つだと思います。DeepSeek-R1を含む推論モデル)が高く評価されている理由の一つです。
しかし、アップルの研究者6人のチームはこれに疑問を投げかけた。チームに様々なパズルを解かせたところ、最先端の大規模推論モデルであるDeepSeek-R1、o3-mini、Claude-3.7-Sonnet-Thinkingは、ある複雑さのしきい値を超えると精度が完全に落ちてしまうことがわかったのです。

図|関連論文(出典:https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf)
注目に値するのは、アップルの機械学習研究シニア・ディレクターであるサミー・ベンジオがこの論文の共著者であることだ。彼はチューリング賞を受賞したジョシュア・ベンジオの弟であるだけでなく、グーグル・ブレイン・チームの最初のメンバーの一人でもある。

図|問題の論文の著者6人、右から2番目がサミー・ベンギオ(出典:Source)
ゲイリー・マーカスの「週末ロングエッセイ」では

写真|ゲイリー・マーカスの個人サイト「週末ロングエッセイ」(出典:https://garymarcus.substack.com/p/a-knockout-blow-for-llms)
では、これは悪いニュースなのか?では、これは「悪いニュース」なのだろうか、それとも「良いニュース」なのだろうか? まずは、アップルの論文の詳細から見ていこう。
この研究で、Appleの現在の研究チームは、3つの異なる推論モデルを発見しました。低複雑度のタスクでは、標準的な大規模言語モデルが大規模推論モデルを上回り、中複雑度のタスクでは、大規模推論モデルがさらに優れたパフォーマンスを発揮し、高複雑度のタスクでは、どちらのタイプのモデルもタスクを効果的に完了することができませんでした。
問題が臨界複雑度に近づくにつれ、推論に必要な労力は逆に減少し、大きな推論モデルの計算サイズには、上限を持つ本質的なスケーリングが存在する可能性を示唆している。上限がある。
研究チームは、これらの洞察は大規模推論モデルの能力に関する一般的な仮定を覆すものであり、現在のアプローチには一般化可能な推論に対する根本的な障壁がある可能性を示唆していると述べている。
最も注目すべきは、研究チームは大規模推論モデルが厳密な計算を行う方法に限界があることを観察したことだ。例えば、モデルに数学的パズルゲーム「ハヌカ」を解くアルゴリズムを提供したところ、この問題に対する性能は向上しなかった。
さらに、モデルの最初のミスステップを詳細に分析すると、驚くべき行動パターンが明らかになった。例えば、モデルはHanno's Towerでは100の正しい手を完成させることができますが、論理推論ゲームRiver Crossing Puzzleでは5以上の正しい手を出すことができません。
全体として、研究チームは、この論文が既存の大規模推論モデルの長所と限界の両方を浮き彫りにしていると考えており、次の5つの重要な発見がありました:。
第一に、研究チームは、確立された数学的ベンチマークで大規模推論モデルを評価するという現在のパラダイムに疑問を呈し、アルゴリズムパズル環境を使用した制御された実験テストベッドを設計した。
第二に、研究チームの実験では、最先端の大規模推論モデル(例えば、o3-mini、DeepSeek-R1、Claude-3.7-、Sonnet-Thinkingなど)でさえも、依然として、大規模推論モデルを評価できないことが示された。Sonnet-Thinking)でも、一般化可能な問題解決能力を開発できていない。異なる環境において、問題の複雑さがある閾値を超えると、それらの精度は最終的にゼロになる。
第三に、研究チームは、大規模な推論モデルには、問題の複雑さに関連する推論能力のスケーリング限界があることを発見した。これは、ある複雑さポイントに達した後、トークンの数が逆に減少傾向にあることで確認された。
第4に、チームは最終的な正確さに基づく現在の評価パラダイムに疑問を呈し、問題の複雑さが増すにつれて、正解は不正解に比べて推論プロセスのさらに後方に現れるという分析結果を示した。より後方に位置する。
第五に、研究チームは、大規模推論モデルが正確な計算を実行する能力における顕著な制限を明らかにした。推論の矛盾など
大きな推論モデルは、自己修正する能力が限られている。-- は推論タスクのために特別に最適化された大規模言語モデルから派生した新しい変種である。
これらのモデルは新しいタイプの技術の産物であり、その中心的な特徴は、自己反省的思考連鎖(思考の連鎖)のようなユニークな「思考」メカニズムである。CoT(Chain-of-Thought:思考の連鎖)は自己反省的であり、複数の推論ベンチマークで優れた性能を実証しています。
これらのモデルの出現は、大規模な言語モデルが複雑な推論や問題解決を扱う方法におけるパラダイムシフトの可能性を示唆しています。これは、より一般化されたAI能力への重要な一歩であると考える研究者もいます。
このような視点やパフォーマンスの進歩があったにもかかわらず、大規模推論モデルの基本的な長所と限界はまだ完全に理解されていません。未解決の重要な疑問は、これらの大規模推論モデルは一般化された推論が可能なのか?それとも、単に異なる形のパターンマッチングを利用しているだけなのだろうか?
問題の複雑さが増すにつれて、そのパフォーマンスはどのように変化するのでしょうか?トークンについての推論に同じ計算予算が与えられている場合、「考える」メカニズムを持たない標準的なビッグ・ランゲージ・モデルと比較してどうなのか?
最も重要なことは、現在の推論アプローチの固有の限界は何か?よりロバストな推論を達成するためにはどのような改善が必要でしょうか?
研究チームは、現在の評価パラダイムの限界が、これらの問題の体系的な分析の欠如につながっていると考えています。既存の評価は、主に確立された数学的ベンチマークとコーディングベンチマークに焦点を当てている。これらのベンチマークには一定の価値がありますが、データ汚染に悩まされることが多く、さまざまなシナリオや複雑性における管理された実験条件を提供するものではありません。
これらのモデルの推論動作をより厳密に理解するためには、制御された実験ができる環境が必要だとチームは感じました。
そのため、数学パズルのような標準的なベンチマークを使用する代わりに、制御されたパズル環境を使用した。複雑さを系統的に変化させ、解答プロセスや内部推論プロセスを調べることができる。
(出典:ソース)
これらのパズルには次のような特徴がある。
(1)複雑さのきめ細かいコントロールを提供する。
(2) 複雑さのきめ細かいコントロールを提供する。(2)既存のベンチマークにありがちな汚染を避ける;
(3)明示的に与えられたルールだけに依存する。
(4)厳密なシミュレータベースの評価をサポートし、正確なソリューションチェックと詳細な故障解析を可能にします。
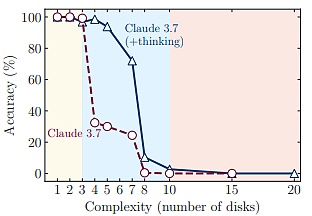
実証研究を通じて、現在の大規模推論モデルに関するいくつかの重要な発見を明らかにしています。text-align: left;">第一に、大規模推論モデルは強化学習によって複雑な自己反映メカニズムを学習することができるものの、計画タスクのための一般化可能な問題解決能力を開発することができず、ある複雑さの閾値を超えるとパフォーマンスがゼロになる。
第二に、研究チームが大規模推論モデルと標準的な大規模モデルを同等の推論計算の下で比較した結果、3つの異なる推論メカニズムが明らかになった。
1つ目のメカニズムは、標準的なラージモデルが、より単純で組合せの少ない問題に対して、より高い効率と精度を示すということである。
2つ目のメカニズムは、問題の複雑さが適度に増すにつれて、大きな推論モデルが有利になるということです。
3つ目のメカニズムは、どちらのタイプのモデルも、問題が複雑になるにつれて、組み合わせの深さが増すにつれて、明らかにパフォーマンスが落ちるということです。
(出典:Source)
この失敗閾値に近いことは注目に値する。この失敗しきい値の近くでは、大規模な推論モデルは世代長制限をはるかに下回るものの、問題の複雑さが増すにつれて、推論入力(推論時のトークン数で測定)を減らし始める。
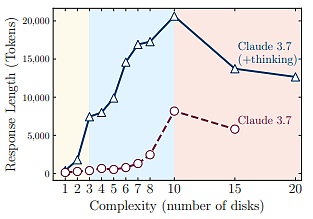
(出典:Source)
このことは、大規模推論モデルの推論能力に根本的な違いがあることを示唆している。は、推論能力に根本的な限界がある:問題の複雑さが増すにつれて、推論時間が大幅に増加する。
さらに、中間推論の軌跡を分析することで、研究チームは、問題の複雑さに関連する規則性、つまり、より単純な問題では、推論モデルは、素早く次のようなものを見つけることができる傾向があることを発見した。エラー解決しかし、非効率的に間違った選択肢を探り続けることになる。
中程度の複雑さの問題では、モデルは正しい解を見つける前に、多数の間違った経路を広範囲に探索する必要があります。そして、ある複雑さの閾値を超えると、モデルは正しい解を見つけることが完全にできなくなります。
北京郵電大学准教授のバイ・ティン(Bai Ting)氏は、ディープテックに対し、人間の考え方と同様に、複雑な問題では、何が正解かはわからないが、何が正解でないかは非常によくわかると語った。具体的には、これは解空間の大きさに関連しており、単純な問題の解空間は短い連鎖の論理のため、特徴の一致度が高く、正しい解は思考経路の前方に自然にあることが多く、一方、複雑な問題の解空間は論理レベルの入れ子の結合と指数展開の提示に関与する多次元変数のため、解空間は巨大であり、客観的には相対的な事後性の思考のシーケンスとして現れる。
研究のほとんどの実験は、クロード3.7ソネット(推論/非推論)やDeepSeek-R1/V3などの推論モデルと、それに対応する非推論モデルで行われた。チームがこれらのモデルを選んだ理由は、OpenAIのoシリーズなどの幅広い推論モデルにアクセスできるからである。
各パズルインスタンスについて、チームは25サンプルを生成し、各モデルの平均パフォーマンスを報告しました。
推論モデルの思考プロセスをより深く理解するために、チームは推論トレースを注意深く分析した。
この間、彼らはパズルの実験環境を構築することで、モデルが生成する推論の軌跡(すなわち「思考プロセス」)をよりきめ細かく観察・分析することができ、モデルの最終的な答えを超えた深い分析を実現することができた。
具体的には、パズルのシミュレーターを使って、モデルの思考過程で探索される中間解を抽出し、分析した。
そして、これらの中間解のパターンと特徴、推論プロセスにおける連続的な位置に対する正しさ、問題の複雑さが増すにつれてこれらのパターンがどのように進化するかを調べました。
この分析のために、研究チームはパズルセット実験でクロード3.7ソネット推論モデルが生成した推論トレースに注目した。
痕跡の中で特定された各中間解について、チームは(1)推論の軌跡における相対的な位置(総思考長で正規化)、(2)チームのパズルシミュレータによって検証されたその正しさ、(3)対応する問題の複雑さを記録した。
これにより研究チームは、推論プロセス全体を通して、解答形成の進捗と精度を特徴付けることができた。

研究チームは、より単純な問題では、推論モデルは通常、思考の初期段階で正しい解を見つけるが、その後、誤った解を探索するようになることを発見した。
不正解(赤)の分布は、正しい解(緑)に比べて、思考の連鎖の終わりに向かって大きくシフトしている。問題の複雑さが適度に増すと、この傾向は逆転する。モデルはまず誤った解決策を探索し、思考の後半でほとんどが正しい解決策に到達する。このとき、誤った解決策(赤)の分布は、正しい解決策(緑)に比べて、連鎖のさらに下にシフトしています。
最終的に、より複雑な問題では、モデルは壊れ始め、思考プロセス中に正しい解を生成できなくなります。
次の図は、ハノーバー・タワー環境における思考シーケンスのセグメント(区間)内の解の精度を補完的に分析したものです。

単純な問題(N値が小さい)では、思考が進むにつれて解の精度が低下または変動する傾向があることが観察されます。この現象は、考えすぎのさらなる証拠となる。
しかし、より複雑な問題では、この傾向が変化する-ある閾値に達するまで、思考が進むにつれて解の精度が上がる。この複雑さの閾値を超えると、「クラッシュモード」になり、モデルの精度はゼロになる。
ティン・バイはDeepTechに対し、複雑な問題ではモデルが何度も推論する必要があり、常に正しい解が得られない場合、モデルの推論メカニズムが効率最適化戦略を生成するために何度も反復を行うか、あるいは反復が多すぎないようにリソースを節約する戦略を生成する可能性があると述べています。したがって、本論文で得られた知見は、モデルの実装レベルで注意深く分析し、検証する必要がある。
ベイティングは、大規模モデルの推論プロセスが本質的にメモリパターンの呼び出しである可能性も指摘しています。 DeepSeek-R1やo3-miniのようなモデルの場合、その性能は訓練データにおける記憶パターンのカバレッジに大きく依存し、問題の複雑さが記憶パターンのカバレッジ閾値を突破すると(今回アップルの研究チームが設計した制御されたパズル環境の場合のように)、モデルは「精度ゼロ」の状態に陥る。
現在のパズル環境では、問題の複雑さをきめ細かく制御した制御実験が可能ですが、それは推論タスクのごく一部を表しているに過ぎず、実世界や知識集約型の推論問題の多様性を捉えていない可能性があります。
この研究は、主にクローズドで最先端の大きな推論モデルへのブラックボックスAPIアクセスに基づいており、研究チームがその内部状態やアーキテクチャコンポーネントを分析することを妨げている制限であることに注意することが重要である。
また、決定論的なパズルシミュレータを使用する場合、研究チームは推論がステップバイステップで完璧に検証できると仮定しました。しかし、あまり構造化されていないドメインでは、そのような正確な検証を達成することは難しいかもしれず、より広い推論シナリオへのこの分析的アプローチの移行を制限する。
研究チームは全体として、制御されたパズル解き環境を通して、問題の複雑性の観点から最先端の大規模推論モデルを検証した。この結果、現在のモデルの限界が明らかになった。つまり、これらのモデルは洗練された自己反省メカニズムを持っているにもかかわらず、特定の複雑さの閾値を超える一般化可能な推論能力を発達させることができないのである。研究チームは、今回の結果が、これらのモデルの推論能力を調査する道を開くかもしれないと考えている。
SECはGrayscaleのデジタル大型株ファンドをETF化する計画を承認し、投資家は主要暗号通貨のバスケットに簡単にアクセスできるようになった。この動きは、ソラナ、XRP、カルダノのようなアルトコインを含む、より多くの暗号ETFが米国で承認されることにつながる可能性がある。
Anais米国の判事は、2022年の破綻時に39,545ビットコインを強制的に売却したことで、40億ドル以上の損失が生じたとして、セルシオがテザー社を提訴することを認めた。裁判所は、米国の管轄外であるというテザー社の主張を退け、詐欺や契約違反などの重要な請求が行われることを意味する。
Anaisリップル社は、同社のステーブルコインRLUSDをサポートするため、米国の国立銀行認可と連邦準備制度理事会(FRB)の口座を申請した。この動きは、新しい法律がステーブルコイン発行者に厳しい規則を満たすよう促す中、リップル社が信用を高め、USDCやUSDTと競争することを目指していることによる。
 Weatherly
WeatherlyRobinhoodはOpenAIとSpaceXの株式にリンクしたトークンを欧州のユーザーに提供したが、OpenAIは関与を否定し、トークンは実際の株式を表すものではないと警告した。イーロン・マスクはOpenAIのトークンを「偽物」と呼び、批評家たちは、このスキームは誤解を招きやすく、法的に不明確だと述べている。
Anais北朝鮮のハッカーが暗号企業内で密かに職に就き、開発者やITスタッフを装って内部からのアクセスを獲得している。調査の結果、数百人がこの業界で働いている可能性があり、中にはインサイダー権限を利用した窃盗や詐欺に関係している者もいる。
WeatherlyOpenAIは、スターゲイトAIプロジェクトのために大規模なコンピューティングパワーを確保するため、オラクルと年間300億ドルの契約を結んだ。オラクルは、4.5GWのエネルギーと40万個のNvidia製チップを使用して、全米に大規模なデータセンターを建設し、OpenAIのAIニーズの増大に対応する。
Anaisハッカーたちは、少なくとも40の偽の暗号ウォレット拡張機能をFirefoxストアにアップロードし、ユーザーを騙してウォレットの詳細を提供している。アプリの中にはMetaMaskやTrust Walletのような本物のウォレットをコピーしたものもあり、すでにユーザーが資金を失う原因となっている。
Weatherly年会費10億ウォンのソウルの新しいプライベートクラブは、暗号通貨で儲けた人やタトゥーの多い人を除外していると報じられている。高額にもかかわらず、会員資格は厳選され、推薦が必要で、伝統的で高級なイメージを目指している。
Weatherlyオーストラリアの暗号億万長者が、エストニアで労働者を装ったギャングに誘拐されそうになった。彼は犯人の指を噛み切って逃げ、暗号を盗み出そうとした一味の計画は失敗に終わった。
AnaisWhiteRockファイナンスの創設者が、失敗した暗号プロジェクトZKasinoに関連する3000万ドルの詐欺に関与した疑いでUAEで逮捕された。このニュースはWhiteRockのトークンを暴落させ、捜査当局は偽造されたパートナーシップと行方不明の投資家資金を明らかにした。
Weatherly