AIボットがニュースビートを席巻世論調査でAIボットが脚光を浴びる、ニュースの "挽歌 "を追うAIボットへの信頼が高まる
火曜日に発表された権威あるメディアのレポートによると、日々のニュースを知るためにChatGPTのような生成AIチャットボットを利用する人が増えているという傾向が明らかになった。
 Catherine
Catherine

著者:Su Yang、Hao Boyang; 出典:Tencent Technology
AI時代の「シャベル売り」として、Jen-Hsun Huangと彼のNVIDIAは、算数は決して眠らないと信じてきました。
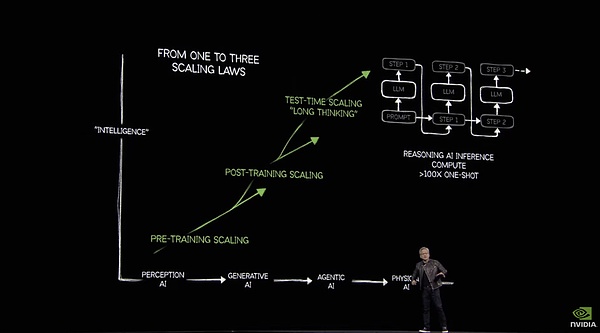
本日GTCで、Jen-Hsun Huangは新しいBlackwell Ultra GPUを発表しました。新しいBlackwell Ultra GPU、およびそこから派生した推論やエージェントに使用されるサーバーSKU、さらにBlackwellアーキテクチャをベースにしたRTXファミリーバケットは、すべて演算能力に関係していますが、次に重要なのは、常に流れてくる演算能力をいかに合理的かつ効果的に消費するかということです。
黄健薰の目には、AGIへの道は算術力を必要とする。は算術を必要とし、。|にできるようにあなたがそれをすることができます本当に出くわすことあなたは、実際には私たち約束、誰でも素早くはちょうど無視これらの一見正確にどのように{}人のことを忘れることができます。
GTCの場面で、自らの見解を支持するために、Huang Jen-Hsunは一連のデータを日焼けさせた - 2024年に、米国の上位4つのクラウド工場は130万Hopperアーキテクチャチップを購入し、2025年までに、このデータは、次のように急増した。
以下、Tencent Technologyがまとめた、NVIDIAのGTC 2025カンファレンスでの核心的なポイントです。Blackwell Family Bucket Goes Live
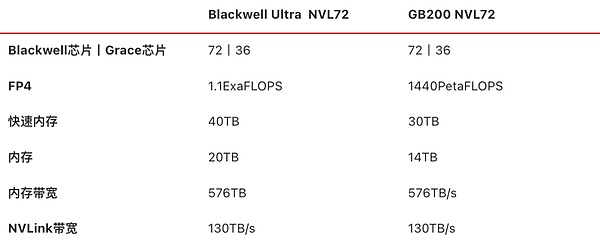
Nvidiaは昨年のGTCでBlackwellアーキテクチャをリリースし、GB200チップを発表したが、今年の正式名称は微調整され、以前から噂されていたGB300とは呼ばれず、直接Blakwell Ultraと呼ばれるようになった。
しかし、ハードウェア的には昨年から新しいHBMメモリに置き換わっただけです。肝心なのは、Blackwell Ultra=Blackwell High Memoryバージョンということだ。
Blackwell Ultraは、2つのTSMC N4P(5nm)プロセス、Blackwellアーキテクチャチップ+Grace CPUパッケージで構成され、より高度な12層積層HBM3eメモリと組み合わされ、グラフィックスメモリは前世代と同じ288GBに増強されています。また、第5世代NVLinkに対応し、1.8TB/sのチップ間インターコネクトをサポート。

ストレージのアップグレードに基づき、Blackwell GPUは以下の注意事項に基づき、最大15ペタFLOPSのFP4精度演算を達成できます。アクセラレーション・メカニズムに基づき、推論速度をHopperアーキテクチャ・チップの2.5倍に向上させます。

Blackwell Ultra NVL72の公式画像
GB200のNVL72と同様に、NVIDIAは今年、同様の製品であるBlackwell Ultra NVL72エンクロージャーを発表しました。これは、合計18個のコンピュートトレイで構成され、各トレイには4個のBlackwell Ultra GPU + 2個のGrace CPU、合計72個のBlackwell Ultra GPU + 2個のGrace CPUが搭載されています。また、合計72基のBlackwell Ultra GPU + 36基のGrace CPU、20TBのビデオメモリ、576TB/秒の総帯域幅に加え、9基のNVLinkスイッチトレイ(18基のNVLinkスイッチチップ)、130TB/秒のノード間NVLink帯域幅を実現しています。align: left;">キャビネットには、14.4TB/秒の帯域幅を提供する72個のCX-8 NICが内蔵されており、Quantum-X800 InfiniBandカードとSpectrum-X 800G Ethernetカードがレイテンシーとジッターを低減し、大規模なAIクラスタをサポートします。
NVIDIAは、この製品は「AI推論の時代のために」設計されており、以下のようなシナリオを想定していると述べています。推論AI、エージェントおよび物理AI(ロボット工学、インテリジェント運転訓練データシミュレーション合成用)、GB200 NVL72 AI性能の前世代の製品と比較して1.5倍に増加し、DGXエンクロージャ製品の同じ位置のHopperアーキテクチャと比較して、データセンターの収益を増加させる50倍の機会を提供することができます。
提供された公式情報によると、6710億パラメータのDeepSeek-R1の推論は、H100製品に基づいて毎秒100トークンで達成することができ、Blackwell Ultra NVL72ソリューションでは、毎秒1000トークンに達することができます。p>
時間に換算すると、H100では同じ推論タスクを実行するのに1.5分かかりますが、Blackwell Ultra NVL72では15秒で実行できます。
NVIDIAが提供する情報によると、Blackwell NVL72関連製品は、2025年後半に発売される予定です。
サーバーベンダー
Cisco/Dell/HPE/Lenovo/Supermicro、その他15メーカー
クラウドファクトリー
AWS/グーグル・クラウド/Azure/オラクル・クラウドおよびその他の主流プラットフォーム
算術リース・サービス・プロバイダー
CoreWeave/Lambda/Yottaなど
NVIDIAのロードマップによると、GTC2025の本拠地はBlackwell Ultraです。
しかし、Jen-Hsun Huang氏もまた、
GTC2025の本拠地はBlackwell Ultraです。
しかし、Jen-Hsun Huangはこの会場で、2026年に利用可能になるRubinアーキテクチャをベースとした次世代GPUと、さらに強力なキャビネットであるVera Rubin NVL144(72個のVera CPU + 144個のRubin GPU、ビデオメモリ帯域幅13TB/sのHBM4チップ上に288GBのビデオメモリを搭載)についても予告しました。第6世代のNVLinkおよびCX9 NICを搭載しています。
FP4精度での推論演算が3.6エクサフロップス、FP8精度でのトレーニング演算が1.2エクサフロップスで、Blackwell Ultra NVL72の3.3倍の性能を発揮するこの製品の実力はいかに?
それでも不十分な場合は、2027年にさらに強力なRubin Ultra NVL576キャビネットが登場します。

NVIDIAからの公式Rubin Ultra NVL144およびRubin Ultra NVL576パラメータ
現段階ではBlackwell Ultra NVL72のニーズを満たすことができず、ハイパースケールAIクラスタを構築する必要がない顧客のために、NVIDIAのソリューションは、DGX Super PODのBlackwell Ultra版に基づいています。Blackwell Ultra、プラグアンドプレイDGX Super POD AIスーパーコンピューティング・ファクトリーです。
プラグアンドプレイのAIスーパーコンピューティング・ファクトリーとして、DGX Super PODは主に生成AI、AIエージェント、物理シミュレーションに特化したAIシナリオを対象としており、エクイニクスを最初のサービスプロバイダーとして、事前トレーニングから事後トレーニング、本番環境までの演算スケーリング・ニーズの全プロセスをカバーしています。エクイニクスは最初のサービスプロバイダーとして、液冷/空冷インフラサポートを提供します。

ブラックウェル・ウルトラをベースにカスタマイズされたDGX Super PODには、2つのバージョンがあります:
DGX GB300 (Grace CPU ×1+Blackwell Ultra GPU ×2) を内蔵したDGX SuperPODは、以下の2つのバージョンがあります。288Grace CPU + 576 Blackwell Ultra GPU、300TB の高速メモリと FP4 精度で 11.5 ExaFLOPS の演算能力を提供
DGX SuperPOD の DGX B300 を内蔵。DGX SuperPOD、このバージョンはGrace CPUチップを含まず、さらなる拡張スペースがあり、空冷システムを使用し、主なアプリケーション・シナリオは一般的なエンタープライズ・データ・センター
1月のCESで、NVIDIAは3,000ドルのコンセプトAI PC製品であるProject DIGITSの輝きに酔いしれました。
製品のパラメーターは、GB10チップを搭載し、FP4精密演算能力は1PetaFlopsに達し、128GB LPDDR5Xメモリ、CX-7 NIC、4TB NVMeストレージを内蔵し、Linuxベースで動作します。LinuxベースのカスタマイズされたDGX OSオペレーティングシステムを実行し、Pytorchなどのフレームワークをサポートし、NVIDIAが提供するいくつかの基本的なAIソフトウェア開発ツールがプリインストールされており、2000億のパラメトリックモデルを実行できる。マシン全体のサイズはMac miniに近く、2つのDGX Sparkを相互接続することで、4,000億以上のパラメーターを持つモデルを実行することもできる。
私たちはこれをAI PCだと言っていますが、それでも本質的にはスーパーコンピューティングなので、RTXのようなコンシューマー製品ではなく、DGXのラインナップに置かれています。
しかし、宣伝されているFP4性能の稼働率の低さに不満を持つ人もおり、これはFP16の精度に換算すると、RTX 5070、あるいは250ドルのArc B580に匹敵する程度であり、価格性能比が非常に悪くなっています。

正式名称を持つDGXスパークに加えて、NVIDIAはBlackwell UltraベースのAIワークステーションも発表しました。このAIワークステーションは、Grace CPUとBlackwell Ultra GPUを内蔵し、784GBのユニファイド・メモリ、CX-8 NICと組み合わされ、20ペタフロップスのAI演算(公式には無印、理論的にはFP4精度)を実現します。
先に紹介したものは、Grace CPUとBlackwell Ultra GPU製品SKUに基づいている。
デスクトップ用GPU: RTX PRO 6000 Blackwell Workstation Edition、RTX PRO 6000 Blackwell Max-Q Workstation Editionを含む。RTX PRO 5000 Blackwell、RTX PRO 4500 Blackwell、およびRTX PRO 4000 Blackwell
Notebook GPUs: RTX PRO 5000 Blackwell、RTX PRO 4500 Blackwell、およびRTX PRO 4000 Blackwell
Laptop GPUs.style="text-align: left;">データセンターGPU: NVIDIA RTX PRO 6000 Blackwell Server Edition
NVIDIAはエンタープライズコンピューティングのためのAIを構築します。
上記は、小規模なワークステーションから大規模なデータセンター・クラスターまで、Blackwell Ultraチップをベースにさまざまなシナリオ向けにカスタマイズされたSKUのほんの一部で、NVIDIA自身は「Blackwellファミリー」(または「Blackwell Family」)と呼んでいます。NVIDIA自身は「Blackwell Family」(ブラックウェル・ファミリー)と呼んでおり、これは「Blackwell Family Bucket」(ブラックウェル・ファミリー・バケット)と訳されています。
CPO(コ・パックド・オプティカル・モジュール)のコンセプトは、簡単に言えば、スイッチ・チップを光モジュールと共封止する方法です。光モジュールとスイッチチップを共封止することで、光信号を電気信号に変換し、光信号の伝送性能を最大限に活用することができます。
これに先立ち、業界ではNVIDIAのCPOネットワークスイッチ製品について議論されていましたが、なかなかオンライン化されませんでした。光ファイバー接続、光ネットワークの消費電力は、コンピューティングリソースの10%に相当し、光接続のコストは、コンピューティングノードのスケールアウトネットワークとAIパフォーマンス密度の向上に直接影響します。

GTCで展示された2つのシリコン光学共カプセル化チップQuantum-XとSpectrum-X
今年のGTCで、NVIDIAはQuantum-Xシリコン光学共カプセル化チップを一挙に発表しました、
上記の製品は「NVIDIA Photonics」にまとめられており、NVIDIAによると、CPOパートナー・エコシステムの共創と開発に基づくプラットフォームであり、例えば、TSMCの光エンジンをベースとしたマイクロ・リング・モジュレーター(MRM)を搭載しています。これは、高出力でエネルギー効率の高いレーザー変調をサポートするために最適化されたTSMCの光エンジンをベースにしており、着脱可能な光ファイバーコネクターを備えています。
興味深いことに、以前の業界筋によると、TSMCのMRMは、3nmプロセスとCoWoSなどの高度なパッケージング技術に基づき、ブロードコムとともに構築されました。
NVIDIAのデータによると、光モジュールが統合されたフォトニクスのスイッチは、従来のスイッチと比較して3.5倍の性能向上を実現し、1.3倍の効率向上と10倍以上のスケーラビリティ回復力で展開することができます。

Huang Jen-Hsunが描くAIインフラーの「大きなパイ」
Huang Jen-Hsunが描くAIインフラーの「大きなパイ」
Huang Jen-Hsunは、2時間のGTCでソフトウェアと具現化された知能について30分ほどしか話さなかったため、公式ドキュメントから多くの詳細を引き出すことができた。そのため、多くの詳細は、完全にフロアからではなく、公式ドキュメントを介して追加された。
Nvidia Dynamoは間違いなくショーのソフトウェアリリースでした!キング・ボム。
これは、データセンター全体の推論、トレーニング、およびアクセラレーションのために構築されたオープンソースソフトウェアであり、Dynamoのパフォーマンス数値はかなり驚異的です:Dynamoは、既存のHopperアーキテクチャ上の標準的なLlamaモデルのパフォーマンスを2倍にします。また、DeepSeekのような特殊な推論モデルでは、NVIDIA Dynamoのまた、NVIDIA Dynamoのインテリジェントな推論最適化により、GPUごとに生成されるトークンの数が30倍以上に増加します。
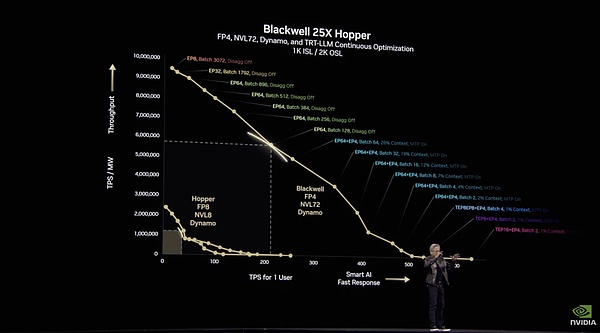
Dynamoの改善は、主に分散によるものです。LLM の異なる計算フェーズ (ユーザーのクエリーを理解し、最適なレスポンスを生成する) を異なる GPU に分散し、各フェーズを独立して最適化できるようにすることで、スループットを向上させ、レスポンスを高速化します。
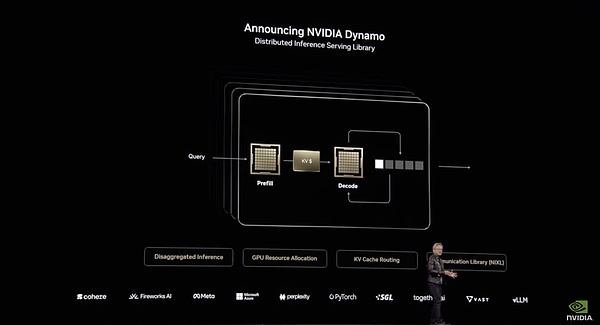
たとえば、入力処理の前段階であるプリポピュレーション段階で、DynamoはGPUリソースを効率的に割り当ててユーザーの入力を処理することができます。このシステムでは、GPUがより分散して高速に処理することを期待して、複数のGPUを使用してユーザーのクエリを並列処理します。 Dynamoは、FP4モードを使用して複数のGPUを呼び出し、1つのグループがユーザーのクエリを処理することで、ユーザーの質問を同時に並列で「読み取り」「理解」します。"GPUの1つのグループは第二次世界大戦に関する背景知識を処理し、別のグループはその原因に関する歴史的情報を処理し、3つ目のグループはその「余波」の時系列と出来事を処理する。"余波 "とは、複数の研究助手が一度に大量の情報をレビューするようなフェーズのことだ。この段階は、複数のリサーチアシスタントが同時に大量の情報に目を通すようなものだった。
出力トークンの生成、つまりデコード・フェーズでは、より集中した首尾一貫したGPUが必要になります。Dynamoは、コヒーレントで効率的な応答生成を保証するために、GPU間の通信とリソース割り当てを最適化します。一方では、トークン生成の効率を最大化するために、NVL72アーキテクチャの高帯域幅NVLink通信機能をフル活用しています。一方、「スマート・ルーター」は、関連するKV(キー・バリュー)をすでにキャッシュしているGPUにリクエストを誘導することで、二重計算を回避し、処理速度を大幅に向上させます。二重計算を回避した結果、GPUリソースの一部が解放され、Dynamoはこれらの空きリソースを新しいリクエストに動的に割り当てることができます。
このアーキテクチャは、KimiのMooncakeアーキテクチャに非常に似ていますが、基盤となるインフラでNVIDIAからより多くのサポートを受けています。Mooncakeはおそらく約5倍の改善ですが、Dynamoはその推論ではるかに顕著です。
たとえば、Dynamoの主要な革新的技術のうち、「GPUプランナー」は負荷に基づいてGPUの割り当てを動的に調整し、「低遅延通信ライブラリ」はGPUの割り当てを最適化します。GPUプランナー」は負荷に応じてGPUの割り当てを動的に調整し、「低遅延通信ライブラリ」はGPU間のデータ転送を最適化し、「メモリー・マネージャー」は異なるコストレベルのストレージデバイス間で推論データをインテリジェントに移動させ、運用コストをさらに削減する。また、LLMを意識したルーティング・システムである「スマート・ルーター」は、リクエストを最適なGPUに誘導し、重複計算を削減します。この一連の機能はすべて、最適なGPUロードを可能にします。
この一連のソフトウェア推論システムを使用することで、1つのAIクエリに対して最大1,000 GPUという大規模なGPUクラスターにシームレスに効率的に拡張し、データセンターのリソースを最大限に活用することができます。
また、GPUオペレーターにとって、この改善は100万トークンあたりのコストの大幅な削減と容量の劇的な増加につながります。同時に、1人のユーザーが1秒あたりにより多くのトークンを獲得し、レスポンスが速くなり、ユーザー体験が向上します。
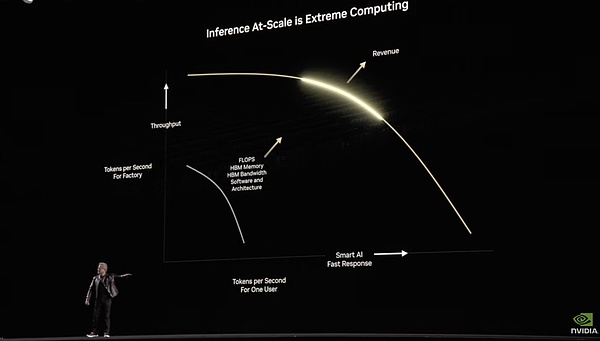
GPUプログラミングの基礎となるCUDAとは異なり、Dynamoは大規模な分散をインテリジェントに管理することに焦点を当てた、より高レベルのシステムです。大規模な推論負荷のインテリジェントな分散と管理に焦点を当てています。Dynamoは、アプリケーションと基礎となるコンピューティング・インフラの間に位置する、推論最適化のための分散スケジューリング・レイヤーを担当する。しかし、CUDAが10年以上前にGPUコンピューティングの状況に革命を起こしたように、Dynamoは推論ハードウェアとソフトウェアの効率性のための新しいパラダイムの到来を告げることに成功するかもしれません。
Dynamoは完全にオープンソースであり、PyTorchからTensor RTまで、すべての主要なフレームワークをサポートしています。いつものようにオープンソースで堀があります。CUDAのように、NVIDIAのGPU上でのみ動作し、NVIDIA AI推論ソフトウェアスタックの一部です。
このソフトウェアアップグレードにより、NVIDIAはGroqのような推論専用AISCチップに対する独自の防御を構築した。推論インフラを支配するには、ハードとソフトの組み合わせでなければなりません。
Dynamoはサーバーの利用率に関しては本当に見事である。
Dynamoは本当に見事ですが、NVIDIA は、モデルのトレーニングに関しては、真のインサイダーにはまだ少し足りません。
NVIDIAは今回のGTCで、効率と精度に焦点を当てた新しいモデル「Llama Nemotron」を使用しました。これは、Llamaシリーズのモデルから派生したものです。NVIDIAによって特別に微調整されたこのモデルは、Llama本体と比較して、アルゴリズム的に刈り込まれ、最適化されており、わずか48Bと軽量です。Claude 3.7やGrok 3と同様に、Llama Nemotronモデルには推論能力スイッチが内蔵されており、ユーザーがオン/オフを選択できる。このシリーズは、エントリーレベルのNano、ミッドレンジのSuper、そしてフラッグシップのUltraの3つのクラスに分かれており、それぞれ異なる規模のビジネスのニーズを対象としています。
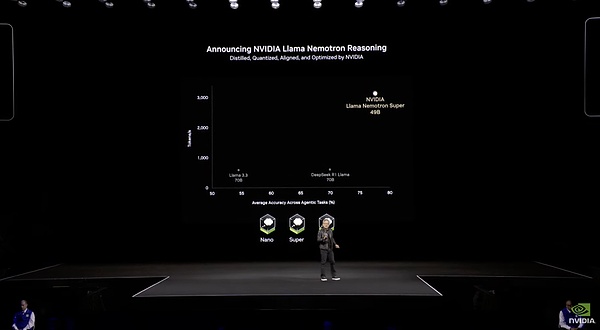
効率的といえば、このモデルの微調整されたデータセットは、すべてNvidia自身が生成した合成データで構成されており、合計で約60Bトークンです。130万H100時間の完全学習を要したDeepSeek V3と比較すると、パラメータ数がDeepSeek V3の15分の1しかないこのモデルは、微調整だけで36万H100時間を要した。学習効率はDeepSeekより1段階悪い。
推論効率の面では、Llama Nemotron Super 49Bモデルは、Llama 3 70Bの5倍のトークン処理能力を持ち、単一のデータセンターGPUで1秒間に3000トークンを処理するなど、前モデルよりもはるかに優れたパフォーマンスを発揮します。単一のデータセンターGPUで毎秒3000トークンを処理できる。しかし、DeepSeekオープンソースデイの最終日に公開されたデータでは、H800ノードあたりの平均スループットは、プリポピュレーション時の入力(キャッシュヒットを含む)が約73.7kトークン/秒、デコード時の出力が14.8kトークン/秒となっている。両者の差はまだ大きい。
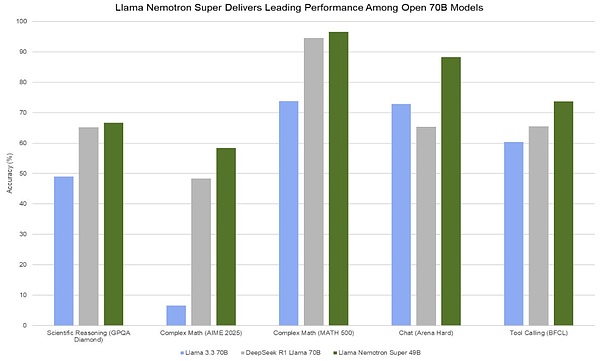
パフォーマンスという点では、49BのLlama Nemotronが優れています。
性能面では、49BのLlama Nemotron Superが70BのWarpをあらゆる指標で上回っている。DeepSeek R1の蒸留ラマ70Bモデル。しかし、最近、Qwen QwQ 32Bモデルのような、小パラメータでハイパワーなモデルが頻繁にリリースされていることを考えると、Llama Nemotron Superは、R1と格闘できるこれらのモデルの中で目立つことは難しいでしょう。
最悪なのは、このモデルで、DeepSeekはおそらくNVIDIAよりもトレーニング中のGPUのチューニングについて知っているという事実を実際に叩きつけられたに等しいことです。
なぜNVIDIAは推論モデルを開発しているのでしょうか?それは主に、Old Yellow が目をつけている次の AI の爆発、つまり AI エージェントに備えるためです。OpenAIやClaude、その他の大手企業は、DeepReasearchやMCPを通じてAgentの基盤を徐々に構築してきたため、NVIDIAも明らかにAgentの時代が到来したと考えています。
「NVIDA AIQ」プロジェクトは、NVIDIAの試みです。これは、Llama Nemotron推論モデルを中心とした、プランナー向けの既製のAIエージェントワークフローを直接提供するものです。このプロジェクトは、NVIDIAのBlueprint層の一部であり、開発者がNVIDIAの技術とライブラリをより簡単に統合できるようにするための、設定済みのリファレンスワークフロー、テンプレート、およびテンプレートのセットを指します。また、AIQはNVIDIAが提供するAgentテンプレートです。
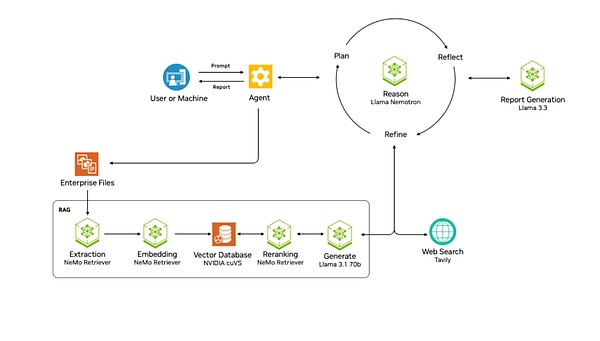
そしてManusは、ウェブ検索エンジンや他の専門AIエージェントなどの外部ツールを統合し、エージェント自身が様々なツールを検索・使用できるようにします。Llama Nemotron推論モデルは、ユーザーのタスクを完了するための処理ソリューションを計画、反映、最適化するために使用されます。これに加えて、マルチエージェントワークフローアーキテクチャの構築もサポートしています。
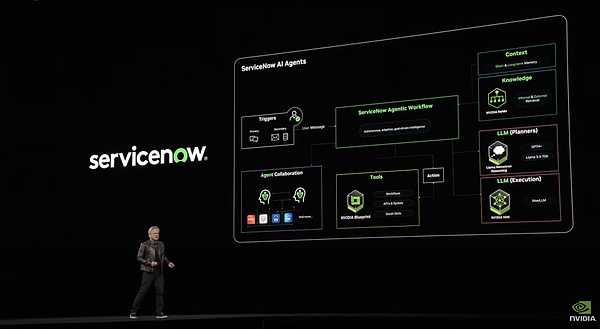
Manusより一歩進んでいるのは、企業文書のための洗練されたRAGシステムを持っていることです。このシステムには、抽出、埋め込み、ベクトル保存、並べ替え、そして最終的にLLMを通した処理という一連のステップが含まれており、企業データを確実にエージェントに提供することができます。
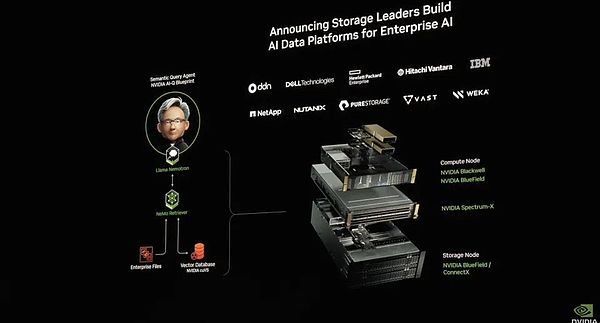
その上、エヌビディアはAIデータプラットフォームも発表しました。これは、AI推論モデルを企業データのシステムに接続し、企業データのDeepReasearchを形成するものです。これにより、ストレージ技術は大きく進化し、ストレージシステムはもはや単なるデータ保管庫ではなく、能動的な推論と分析のためのインテリジェントなプラットフォームとなります。ストレージシステムはもはや単なるデータウェアハウスではなく、能動的な推論と分析機能を備えたインテリジェントなプラットフォームなのです。
さらに、AIQは観測可能性と透明性を重視しています。これはセキュリティとその後の改善のために重要です。開発チームはエージェントの活動をリアルタイムで監視し、パフォーマンスデータに基づいてシステムを継続的に最適化することができます。
全体的にNVIDA AIQは、さまざまなAgent機能を提供する標準的なAgentワークフローテンプレートです。これは、推論の時代への進化のようなもので、よりフールプルーフなDifyタイプのAgent構築ソフトウェアです。
1)Cosmos、具現化された知性が世界を理解できるようにする
モデル、データ、演算は、NVIDIAが配置したモデルの3つの要素です。
モデルから始めるために、GTCは今年1月に発表された具現化された知性の基本モデルであるCosmosのアップグレード版をリリースしました。
Cosmosは、現在の画像から未来の画像を予測できるモデルだ。テキスト/画像の入力データを受け取り、詳細な映像を生成し、現在の状態(画像/映像)と行動(合図/制御信号)を組み合わせることで、シーンの進化を予測することができる。これは世界の物理的な因果法則の理解を必要とするため、NVIDIAはCosmosをワールド・ファウンデーション・モデル(WFM)と呼んでいます。
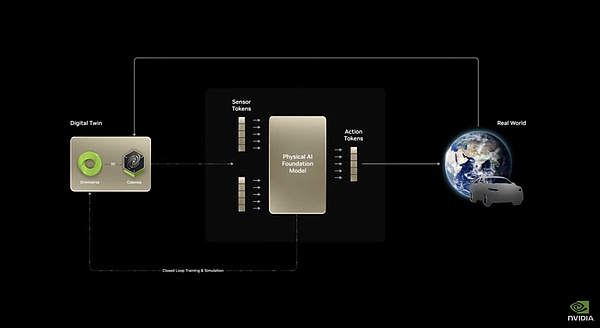
また、具現化された知性の場合、マシンの振る舞いが外界に対して何をするかを予測する能力が、まさにその中心にある。そうして初めて、そのモデルは予測に基づいて行動を計画することができるようになる。つまり、世界モデルが具現化された知能の基本モデルになるのだ。この基本的な行動/時間/物理的-世界を変化させる世界予測モデルを、自律走行やロボット工学のタスクなどの特定のデータセットによって微調整することで、このモデルは物理的な形態を持つ様々な具現化知能の実用的な基盤のニーズを満たすことができる。
モデル全体は、能力の3つの部分から構成されており、最初の部分Cosmos Transferは、構造化されたビデオテキスト入力を制御されたリアリズムビデオ出力に変換し、テキストから大規模な合成データを空中から生成します。これにより、現在の具現化知能の最大のボトルネックであるデータ不足の問題が解決される。さらに、この生成は「制御された」生成であり、ユーザーが特定のパラメーター(天候条件、オブジェクトの特性など)を指定すれば、それに応じてモデルが生成結果を調整するため、データ生成プロセスをより制御しやすく、的を絞ったものにすることができる。このプロセス全体は、OminiverseとCosmosによって組み合わせることもできます。

その2 Cosmos Predictは、マルチモーダル入力から仮想世界の状態を生成することができ、マルチフレーム生成と行動軌跡予測をサポートします。軌跡予測をサポートします。つまり、開始と終了の状態が与えられれば、モデルはもっともらしい中間プロセスを生成することができる。これは核となる物理世界の認識と構築能力です。
3つ目のコンポーネントはCosmos Reasonで、ビデオデータを理解し、心の連鎖推論によって相互作用の結果を予測する、時空間認識を備えたオープンで完全にカスタマイズ可能なモデルです。これは、行動を計画し、行動の結果を予測するための強化された機能です。
これら3つの機能を段階的に重ねることで、Cosmosは現実的なイメージトークン+テキストコマンドプロンプトトークンの入力から、マシンアクショントークンの出力まで、完全な行動連鎖を行うことができます。
この基本モデルは確かにうまく機能するはずです。ローンチからわずか2ヶ月で、1X、Agility Robotics、Figure AIという3つの主要企業がこれを使い始めている。大きな言語モデルが先頭を走っているわけではないが、具現化されたインテリジェンスであるNVIDIAは本当にトップクラスにいる。
Cosmosで、NVIDIAはフレームワークを自然に微調整しました。
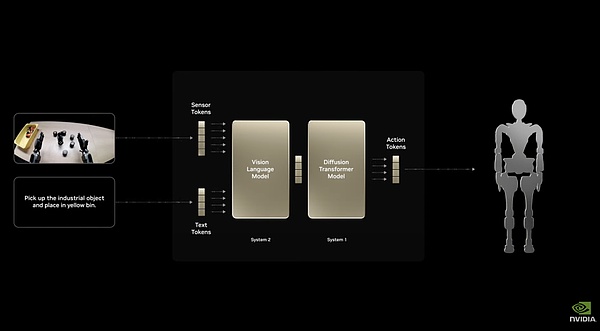
人型ロボット専用のベースモデルである Isaac GR00T N1 をトレーニングしました。="text-align: center;">アイザックGR00T N1のデュアル・システム・アーキテクチャ
高速応答の「システム1」と「システム2」のデュアル・システム・アーキテクチャを採用。「
デュアル・システム・アーキテクチャを採用。把持、移動、デュアルアーム操作など、汎用的なタスクを処理するために完全に微調整されています。また、特定のロボットに完全にカスタマイズ可能であり、ロボット開発者が実データや合成データを用いて後トレーニングを行うこともできる。これにより、このモデルは、さまざまな形状やサイズの、事実上あらゆる種類のロボットに導入することができます。
たとえば、NVIDIAとGoogle DeepMindおよびDisneyとのNewton Physics Engineに関するコラボレーションでは、非常に珍しい小型のDisney BDXロボットを駆動するベースとしてIsaac GR00T N1を使用しました。物理エンジンとしてのニュートンは非常に繊細であるため、仮想環境で具現化された知能を訓練するための物理的報酬システムを構築するのに十分です。

NVIDIAは、NVIDIA Omniverseと前述のNVIDIA Cosmos Transferワールド・ベース・モデルを組み合わせて、Isaac GR00T Blueprintを作成しました。NVIDIAは、Blueprintの最初のコンポーネントを使用して、わずか11時間で78万個の合成軌道を生成しました。これは、6500時間(約9カ月)の人間の実演データに相当します。Isaac GR00T N1のデータの大部分は、このソースから得られたもので、このデータにより、GR00T N1は、実際のデータのみを使用した場合よりも最大40パーセント優れたパフォーマンスを発揮することができました。
各モデルに対して、純粋な仮想システムであるOmniverseと、実世界の画像生成システムであるCosmos Transferにより、NVIDIAは多くの高品質データを提供することができます。多くの高品質データを提供することができます。これが、NVIDIAがカバーするモデルの2つ目の側面です。
昨年以来、ラオ・ファンはGTCで「3つのコンピュータ」というコンセプトを強調してきました。ひとつはDGX、大型GPU用のサーバーで、具現化知能を含むAIの訓練に使われる。もうひとつは、エッジコンピューティングや自律システムのためのエヌビディアの組み込みコンピューティングプラットフォームであるAGXで、自律走行やロボティクスのコアチップなど、エンドサイドでAIを具体的に展開するために使われる。
具現化された知性の3大コンピューティングシステム
このシステムのセットは、今回のGTCで黄氏によって再検討され、彼は特に、このセットのコンピューティング能力で、10億ドルのシステムを生み出すことができると言及しています。億台のロボットを誕生させることができる。訓練から配備まで、演算能力はエヌビディアが使用する。ループのこの部分も閉じている。
結論 純粋に前世代のBlackwellチップと比較するのであれば、Blackwell Ultraはハードウェアの点で、前世代のBlackwellチップにあまりマッチしていません。Blackwell Ultraは、「核」や「爆弾」という以前の形容詞には本当にマッチしておらず、ちょっとした歯磨き粉のようですらあります。 しかし、ロードマップ計画の観点から見ると、これらはすべてJen-Hsun Huang氏のレイアウトにあり、来年、Rubinアーキテクチャの翌年には、チッププロセスからトランジスタ、ラックの統合、GPUインターコネクト、キャビネットインターコネクトなどの仕様が大幅に改善され、中国人がよく言う「ショーはまだこれからだ。"ショーはまだこれからだ。 パイのハードウェアレベルと対照的に、ソフトウェアレベルのこれらの2年間のNVIDIAは、乱暴な乗り物であると言うことができます。 NVIDIAのソフトウェアエコシステム全体を見ると、Meno、Nim、Blueprintの3層のサービスがモデルの最適化、モデルのカプセル化からアプリケーションまで、フルスタックソリューションを構築するために含まれています。クラウドサービス企業のエコシステムは、エヌビディアAIのすべてと重なっている。この新しいエージェントと一緒に、AIのインフラは、パイのこの作品は、NVIDIAは、この作品の基本的なモデルに加えて、すべての部分で食べることです。 ソフトウェアこの部分は、古い黄色の食欲、そしてNVIDIAの株価は同じくらい大きいです。 そしてロボット市場では、エヌビディアの野心はさらに大きい。モデル、データ、演算の3要素が手に取るようにわかる。基本的な言語モデル、構成する基本的な具現化された知性の頭に追いつかなかった。影と影、独占巨人の具現化されたインテリジェンスバージョンは、すでに地平線上にその頭を示しています。 内部では、各リンク、各製品は、潜在的な千億市場に対応しています。 初期に一人で賭けをした幸運のギャンブラーの王、Jen-Hsun Huangは、GPUの独占から得たお金でより大きな賭けを始めました。 もしこのギャンブルで、ソフトウェアやロボット市場のどちらか一方が食えるとしたら、エヌビディアはAI時代のグーグルであり、食物連鎖の頂点に立つ独占企業だ。 しかし、NVIDIAのGPUマージンを見てください。 ありがたいことに、これはオールド・イエローにとって大きな賭けであり、彼がこれまで管理したことのないゲームであり、勝つか負けるかはわからない。 火曜日に発表された権威あるメディアのレポートによると、日々のニュースを知るためにChatGPTのような生成AIチャットボットを利用する人が増えているという傾向が明らかになった。 韓国の裁判所は、Haru InvestのCEOであるLee Hyung-soo氏の詐欺行為を潔白とし、プラットフォームの破綻は、犯罪目的ではなく、管理不行き届きと外部からの市場ショックによるものであるとの判決を下した。李氏と他の幹部は服役を免れたものの、2023年の突然の閉鎖で投資家が大きな損失を被ったため、民事上の請求に直面している。 マレーシア中央銀行は、リンギットを裏付けとするステーブルコインを含むデジタル通貨による安全な金融実験を支援するため、デジタル資産イノベーション・ハブを立ち上げた。この動きは、経済の安定と消費者保護を確保しながらイノベーションを促進することを目的とした広範な改革の一環である。 タイは2025年から2029年までの5年間、暗号取引利益に対する所得税を免除することを承認した。この動きは、規制監督を通じて投資家保護を維持しながら、ブロックチェーンの技術革新に拍車をかけることを目的としている。 トランプ大統領は、TikTokの米国売却の3度目の延長を発表し、中国が最終的にこの取引を承認することを確信した。この動きは、2024年に向けて若い有権者の間でTikTokの政治的影響力が高まっていることを反映している。しかし、法的問題や貿易問題が未解決であるため、結果は依然として不透明だ。 メタ社はOpenAIのエンジニアに対し、同社の新しいAIチームに参加するよう最高1億ドルを提示しているが、誰も受け入れていない。OpenAIのスタッフは、メタ社の高額な給与オファーにもかかわらず、会社のミッションを信じて残っている。 ダークウェブ最大の麻薬市場であったArchetypが国際的な捜査により閉鎖され、オンライン犯罪に大きな打撃を与えた。Archetypは5年間にわたり、モネロを使用して2億5000万ドルの取引を処理していた。当局は麻薬、ハードウェア、暗号通貨で780万ドルを押収した。 Meta Poolは、その早期検知システムがリアルタイムで悪用を特定し、チームは侵害されたスマートコントラクトを迅速に一時停止し、さらなる損失が発生する前に被害を食い止めることができたと報告した。 あるYouTuberが、AIを搭載したベッドが冷えすぎてアプリが作動しなくなり、午前3時に起こされた。この不具合は、彼が温度を調節できないことを意味し、基本的な快適さのためにスマートテックに過度に依存することへの懸念を引き起こした。 OpenAIの創設者であるサム・アルトマンは、非常に具体的な試算を提示している。有益なレポートを通じて仮想通貨業界の幅広い理解を得て、志を同じくする他の著者や読者との詳細な議論に参加してください。拡大している Coinlive コミュニティにぜひご参加ください。https://t.me/CoinliveSGコメントを追加するログインあなたの素晴らしいコメントを残すために…0 コメント最も早いコメントをさらに読み込むライブアップデート
話題のニュース
AIボットがニュースビートを席巻世論調査でAIボットが脚光を浴びる、ニュースの "挽歌 "を追うAIボットへの信頼が高まる
Catherine高いリターンを約束し、ナイフで襲われ、そして自由の身となった:はるインベストCEOに詐欺罪は成立しない - 被害者はどうなる?
 Weatherly
WeatherlyマレーシアがASEANのリーダーとしてリンギット裏付けのステーブルコインを追求する中、デジタル資産イノベーションハブが発足
Weatherlyタイは「税金をホドル」と言う:暗号通貨による利益は5年間の免税措置で免除され、成長と監視のバランスを取る
Catherineトランプ大統領がTikTok売却期限を3度目延長、中国の承認に楽観的な見方を示す-しかし終わりが見えるのか?
 Kikyo
KikyoメタCEO、ザッカーバーグの1億ドルの餌には食いつかず-何がOpenAIの人材に忠誠を誓わせるのか?
Weatherly米国司法省と欧州警察による大陸横断的な法執行活動により、モネロを利用した重要なダークウェブ市場が閉鎖される。
Catherineメタ・プールから2700万ドル流出寸前、しかし急ピッチのコード・レッドでハッカーの手元に残ったのはわずか13万2000ドル
Kikyo甘い夢から冷たい悲鳴まで-YouTuberの3,000ドルのスマートベッドAIがアプリのクラッシュで大暴走
WeatherlyChatGPTに質問することの環境フットプリント:好奇心は地球にどれだけのコストをかけるのか?
Catherine