Binanceの創設者CZが辞任、法的問題の中で引退を受け入れる
バイナンスの創設者である趙長鵬(CZ)は最近辞任し、銀行秘密法違反の罪を認めた。保釈金1億7500万ドルを支払ったにもかかわらず、CZは米国に留まっている。
 Joy
Joy

出典:Master Zuo Crooked Neck Mountain
芸術作品は完成することはなく、放棄されるだけである。"">誰もがAIエージェントについて話していますが、同じことを話しているわけではありません。それは、AIエージェントについて、一般的な観点からも、AI実践者の観点からも、私たちが気にしているのとは異なる観点につながります。
ずいぶん前に、私はと書きました。当時から現在に至るまで、暗号とAIの組み合わせは一方的な恋愛関係であり、AIの実務家はWeb3/ブロックチェーン用語にほとんど言及しない一方で、暗号の実務家はAIに恋をしている。AIエージェントフレームワークがトークン化されることの素晴らしさを目の当たりにした後、私たちは本当にAI実践者を私たちの世界に引き入れることができるのだろうかと思う。
AIはCryptoのエージェントであり、これは現在のAI熱狂を暗号の観点から見る最良の方法です。CryptoのAIへの熱狂は他の業界とは異なり、私たちは特に金融資産の発行と運用をその中に入れ子にすることに興味があります。
問題の根源に迫ると、AIエージェントには少なくとも3つの流れがあり、OpenAIのAGI(Generalised Artificial Intelligence)は、この言葉を技術レベルを超越したバズワードにすることで、大きな一歩を踏み出しました。しかし、本質的にエージェントは新しい概念ではなく、AIによる実現が加わったとしても、革命的な技術トレンドとは言い難い。
そのうちの1つが、OpenAIの目から見たAIエージェントで、自律走行分類のL3に似ています。AIエージェントは、ある程度の高次の運転補助能力を持つと見なすことができますが、完全に人間を置き換えることはできません。

2つ目は、その名の通り、AIエージェントはAI対応のエージェントであり、エージェントの仕組み、コンピュータの分野でのモードは珍しいものではありませんが、OpenAIの計画では、エージェントは対話形式(ChatGPT)、L3段階以降の推論形式(あらゆる種類のBot)となり、その特徴は「自律的に作業を遂行する」ことです。自律的な振る舞い」、つまりLangChainの創設者であるハリソン・チェイスが定義しているように、「AIエージェントは、LLMを使ってプログラムに関する制御フローの決定を行うシステムである」ことが特徴です。プログラムの制御フロー決定を行う。"
そこが素晴らしいところです。 LLMが登場する以前は、エージェントは主に人間が設定した自動化処理を実行していました。例えば、クローラープログラムを設計する場合、プログラマーは、LLMを設定します。クローラーを設計するとき、プログラマーはUser-Agentを設定し、ブラウザのバージョン、オペレーティングシステム、および実際のユーザーが使用するその他の詳細を模倣します。 もちろん、AIエージェントがより詳細に人間の行動を模倣するために使用されるのであれば、AIエージェントのクローラーフレームワークが出現し、クローラーが「より人間に近く」なります。
このような変化において、AIエージェントの追加は既存のシナリオと組み合わせなければならず、完全なオリジナリティを発揮できる分野は、CurosrやGithub copilotなどのコード補完・生成機能だけでなく、LSP(Language Server Protocol)などの更なる発展下での考え方においても、ほぼ存在しない。
Apple: AppleScript (スクリプトエディター) - AppleScript (スクリプトエディター) - AppleScript (スクリプトエディター) - AppleScript (スクリプトエディター) - AppleScript (スクリプトエディター) - AppleScript (スクリプトエディター)Alfred -- Siri -- ショートカット -- Apple Intelligence
Terminal: Terminal (macOS) / Power shell (Windows) -- iTerm 2。--Warp(AI Native)
人間とコンピュータのインタラクション: Web 1.0 CLI TCP/IP Netscapeブラウザ --Web 2.0 GUI/RestAPI/検索エンジン/Google/スーパーアプリ --Web 3.0 AIエージェント+ダップ?
少し説明すると、人間とコンピュータのインタラクションのプロセスにおいて、Web 1.0のGUIとブラウザの組み合わせは、Windows+IEの組み合わせに代表されるように、本当に一般の人が敷居なくコンピュータを使うことを可能にし、APIはインターネットの背後にあるデータの抽象化と伝送の標準であり、Web 2.0時代のWeb2.0時代はChromeの時代であり、モバイルへのシフトは人々のインターネット利用の習慣を変え、WeChat、Metaなどの超プラットフォームアプリは人々の生活のあらゆる側面をカバーしている。
第三に、CryptoにおけるIntentのコンセプトは、AI Agentサークルの爆発的な広がりの先駆けです。しかし、これはCrypto内でのみ有効であることに注意してください。機能的に不自由なビットコインスクリプトからイーサリアムのスマートコントラクトまで、それ自体がAgentのコンセプトの一般化であり、その後クロスチェーンブリッジを生み出しました。--クロスチェーンブリッジ、チェーンの抽象化、EOA-AAウォレットは、すべてこれらのアイデアの自然な拡張であり、AIエージェントによるCryptoの「侵略」がDeFiシナリオにつながったことは驚くべきことではない。しかし、OpenAIの定義では、このような危険なシナリオは、L4/L5が真に実現される必要すらあり、そうなると、一般人が遊んでいるのは、コードの自動生成やAIのワンクリック要約、代筆などの機能であり、両者のコミュニケーションは次元が違う。
私たちが本当に望んでいることを理解し、次の焦点はAIエージェントの組織ロジックについて話すことで、技術的な詳細は隠されるでしょう、結局のところ、AIエージェントのエージェンシーの概念は、技術の大衆人気の前に障害物から技術を削除することです、そのような金鉱に個人PC業界のブラウザのように、私たちの焦点は、次のようになります。つまり、人間とコンピュータの相互作用というレンズを通して見たAIエージェントと、AIエージェントとLLMの違いとつながり、そして第3部「暗号とAIエージェントの組み合わせに残されたもの」につながるという2点に焦点を当てます。
ChatGPTモデルの前では、人間とコンピューターの相互作用はGUIとCLIによって支配されていました。
GUIという考え方は、ブラウザ、アプリ、その他の特定の形をとり続け、CLIとシェルの組み合わせはほとんど変わりませんでした。
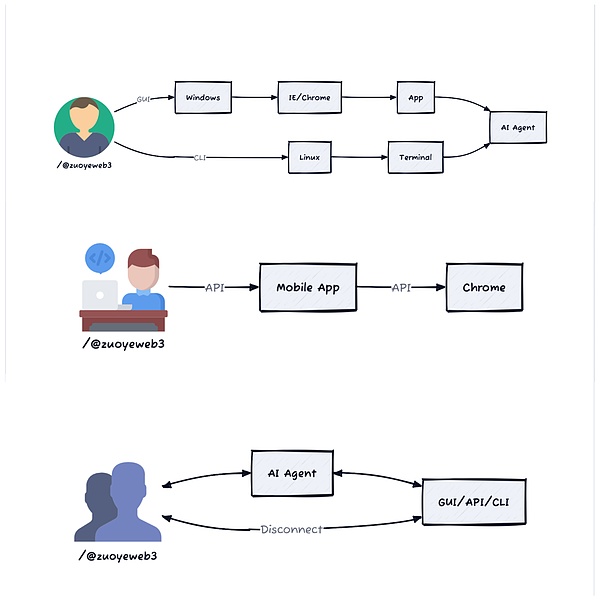
しかし、これは人間とコンピュータのインタラクションの「フロントエンド」表面に過ぎない。インターネットの発展に伴い、データの量と種類が増えたことで、「バックエンド」のインタラクションの間のアプリとアプリの間のデータとデータも増えており、この2つは相互に依存している。単純なウェブ閲覧行動でさえ、両者の連携と協力が必要なのだ。
人とブラウザとアプリの間のインタラクションがユーザーポータルであるとすれば、API間のリンクとジャンプはインターネットを機能させるものであり、実際にはエージェントの一部であり、一般ユーザーがコマンドラインとAPIの用語を理解しなくても目的を達成できるようにするものです。
LLMも同様で、ユーザーはさらに一歩進んで、検索する必要さえありません。
ユーザーがチャットウィンドウを開く;
ユーザーが自然言語、つまりテキストや音声を使って自分のニーズを説明する;
LLMはこれをフロー化された操作ステップに解析する;。
LLMは結果をユーザーに返します。
このプロセスにおいて、最大の難関はGoogleであることがわかります。なぜなら、ユーザーは検索エンジンを開く必要がなく、GPTのようなあらゆる種類の対話ウィンドウ、トラフィックの入り口が静かに変化しているからです。
では、AIエージェントはどのような役割を果たすのでしょうか?
一言で言えば、AIエージェントはLLMの特殊化です。
現在のLLMはAGIではありません。つまり、OpenAIの理想的なL5オーガナイザーではありません。と何度もGPTに伝えると、一定の確率で次のインタラクションで1+1+1=?と尋ねると、次の対話では一定の確率で4という答えが返ってくる。
この時点でGPTのフィードバックは完全に個々のユーザーから来るので、もしモデルがネットワーク化されていなければ、あなたの情報によって動作メカニズムが変わってしまい、後で1+1=3しか知らない知恵遅れのGPTになってしまう可能性は十分にあります。しかし、モデルがネットワーク化されるようにすれば、GPTのフィードバックメカニズムはもっと多様になります。しかし、もしモデルがネットワーク化されることが許されるのであれば、GPTのフィードバック・メカニズムはより多様なものになります。
物事を難しくし続けるのですが、もしローカルでLLMを使わなければならないのであれば、そのような問題をどのように避けるのでしょうか?
シンプルで残酷な方法は、2つのLLMを同時に使用し、同時に、エラーの確率を減らすために、質問に答えるたびに、2つのLLMにお互いを検証させなければならないと指定することです。失敗した場合は、2人のユーザーに一度に1つのプロセスを扱わせ、1人は質問に責任を持ち、1人は質問の微調整に責任を持ち、言語をより標準化しようとする方法があります、より合理的に。
もちろん、LLMが遅れたバーの答えを取得したように、ネットワークが完全に問題を回避できないこともあります。これは実際、自然言語理解のためのRAG(Retrieval-Augmented Generation)です。
人間と機械はお互いを理解する必要があり、複数のLLMがお互いを理解し、協力できるようにすれば、人間のエージェントが他のリソースを呼び出すという、AIエージェントの動作モードに本質的にすでに触れていることになります。leaf="">その結果、私たちはLLMとAIエージェントのつながりを把握しました。LLMは、人間がダイアログウィンドウを通してコミュニケーションできる知識の集合体ですが、実際には、いくつかの特定のタスクストリームは、アプレット、ボット、コマンドの特定のコレクションにグループ化できることがわかり、私たちはこれらをエージェントと定義しました
AI エージェントとは?span leaf="">AIエージェントは依然としてLLMの一部であり、両者を同一視することはできません。AIエージェントがLLMの上で呼び出される方法は、外部プログラム、LLM、および他のエージェントとのコラボレーションに特に重点を置いており、AIエージェント=LLM+APIという感情があるのはそのためです。
AIエージェントの仕様は、LLMワークフローに追加することができます。
人間のユーザーがチャットウィンドウを開く;
ユーザーは自然言語、つまりテキストまたは音声で自分のニーズを説明する;
LLMはこれをクラスAI AgentタスクへのAPI呼び出しに解析します。
AIエージェントはユーザーXにアカウントとAPIパスワードを尋ね、ユーザーの説明に基づいてXと通信します;
AIエージェントは最終結果をユーザーに返します。エージェントは最終結果をユーザーに返します。
人間とコンピュータのインタラクションの進化を思い出してください。 Web 1.0やWeb 2.0に存在したブラウザやAPIなどはまだ存在するでしょうが、ユーザーはそれらを完全に無視してAIエージェントと対話するだけで、API呼び出しなどのプロセスを会話形式で利用することができます。
これらのAPIサービスは、相手がインターフェイスを開き、ユーザーがアクセスできるのであれば、ローカルデータ、ネットワーク上の情報、外部アプリのデータなど、どのようなタイプでも構いません。
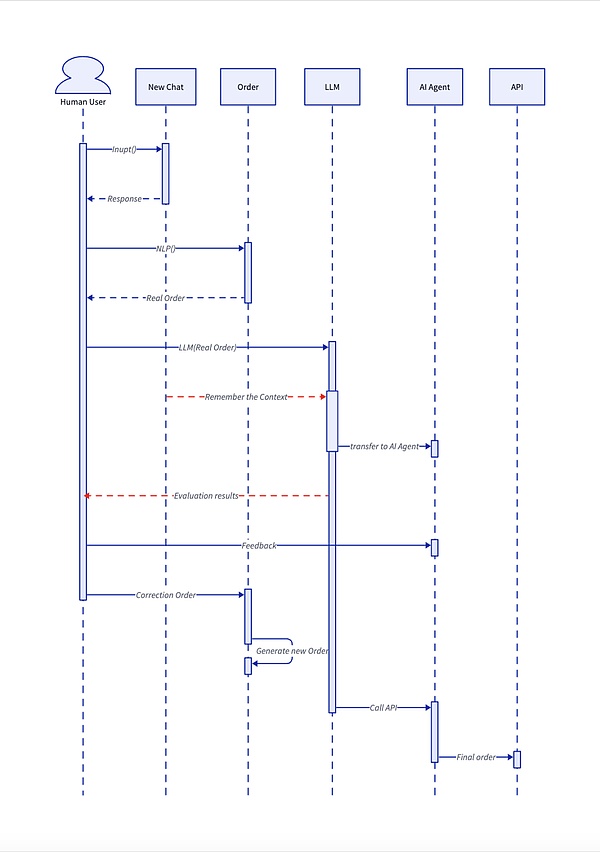
完全なAPIサービス。span leaf="">完全なAIエージェントの使用プロセスが上の図に示されています。LLMはAIエージェントとは別の部分として、またはプロセスの2つのサブセクションとして見ることができますが、どのように分割しても、ユーザーのニーズに応えることがすべてです。 人間とコンピュータの相互作用のプロセス、あるいはユーザー自身との対話の観点から見ると、自分の考えを表現するだけで、AI/LLM/AIエージェントは何度も何度もあなたのニーズを推測し、フィードバックメカニズムを含めるだけでなく、LLMが記憶のコンテキスト(Context)の現在のシナリオを要求することで、AIエージェントが現在の状況を突然忘れることがないようにすることができます。は、AIエージェントが何をしているのかを突然忘れることがないようにすることができます。 要するに、AIエージェントはより人格的な製品であり、これは従来のスクリプトや自動化ツールとの本質的な違いです。L3レベルのAIエージェントは、自分自身を理解し表現する人間の能力を持っていないため、外部APIと連動させることは危険を伴います。 AIフレームワークが収益化できるという事実は、私がまだ暗号に興味を持っている理由の大きな部分です。結局のところ、ほとんどのAIアルゴリズムとモデリングフレームワークはオープンソース製品であり、本当のクローズドソースはデータやその他の機密情報なのです。 要するに、AIのフレームワークやモデルは、コンテナや組み合わせのための一連のアルゴリズムであり、ガチョウの煮込みの鉄鍋に相当するが、ガチョウの品種だけでなく、火の習得は、販売された製品の風味を区別するための鍵はガチョウであるべきですが、今Web3の顧客が来て、彼らはガチョウを放棄する鍋を購入するボックスを購入したい。 理由は複雑ではありませんが、Web3のAI製品は基本的に知恵の断片を拾っている、既存のAIフレームワーク、アルゴリズム、および独自のカスタマイズされた製品を改善するための製品であり、技術的な原理の背後にあるさえ異なる暗号AIフレームワークは、技術的に区別することができないので、非常に異なっていない、名前の必要性、シーンのアプリケーション。技術的に区別できないので、名前、アプリケーションのシナリオなどについて何かをする必要があるので、AIフレームワーク自体へのいくつかの小さな調整は、このようにCrypto AIエージェントのためのフレームワークバブルを作成し、異なるトークンのサポートとなっています。 学習データやアルゴリズムに多額の投資をする必要がないため、特に名称の差別化手法が重要で、DeepSeek V3は安くても医者の髪が必要で、GPUや消費電力も大きい。 ある意味、これが最近のWeb3の一貫したスタイルです。つまり、トークン配布プラットフォームはトークンよりも価値がある、Pump.Fun/Hyperliquidはどれも同じです。Hyperliquidは、Agentがアプリケーションであり資産であるはずだが、Agent配布フレームワークが最も人気のある製品となっている。 実はこれも一種の価値観の固定化であり、あらゆる種類のAgentが差別化されていないため、Agentの枠組みはより安定し、資産発行のサイフォン効果の価値を生み出すことができる。 バージョン2.0が出現しつつある一方で、典型的にはDeFiとAIエージェントの組み合わせであり、DeFAIのコンセプトはもちろん熱刺激された市場行動ですが、次のことを考慮に入れると異なります:AIフレームワークの収益化について
MorphoはAaveのような古いレンディング商品に挑戦しています。
ステーブルコインはオフチェーンシナリオの決済ツールになりつつある。
AIがDeFiの基本的なロジックを改良しているのは、DeFiのトランスフォーメーションの文脈にある。 DeFiの最大のロジックが、以前はスマートコントラクトの実現可能性を検証することだったとすれば、AIエージェントはDeFiを作るロジックを変化させているので、DeFiを理解しなくてもDeFi製品を作ることができる。DeFi製品を作るためにDeFiを理解する必要はなく、それはチェーンの抽象化よりもさらに進んだ根本的なエンパワーメントです。
誰もがプログラマーになる時代がやってくる。 複雑な計算は、AIエージェントの背後にあるLLMやAPIにアウトソーシングすることができ、個人は自然言語を効率的にプログラミング・ロジックに変換して、自分のアイデアに集中するだけでよい。
この記事では、暗号AIエージェントのトークンやフレームワークについては触れません。Cookie.Funは、AIエージェントの情報集約とトークン発見のプラットフォームとして、そしてAIエージェントのフレームワークとして、そして最後には、行ったり来たりするエージェントトークンとして、すでに十分な仕事をしているので、この記事に情報を掲載し続ける価値はありません。
しかし、この観察期間では、市場はまだ暗号AIエージェントのポインタが何であるかの本当の探査を欠いている、我々は常にポインタを議論することはできません、メモリの変更は本質である。
あらゆる対象を資産化できるのもCryptoの魅力です。
バイナンスの創設者である趙長鵬(CZ)は最近辞任し、銀行秘密法違反の罪を認めた。保釈金1億7500万ドルを支払ったにもかかわらず、CZは米国に留まっている。
JoyWall Street MemesはDiscordのサイバー攻撃に迅速に対応し、Discordハック救済基金を立ち上げ、被害者への補償のために$WSMトークンで$46,000を空輸した。11月17日までに請求書を提出した人は、漏洩したウォレット資金を1:1で返金され、コミュニティはTelegramで感謝の意を表明した。チームはまた、Wall Street Memes Casino Loyalty Programを紹介し、来週開始予定のWall Street Casino Affiliate Programを予告している。
 Jixu
Jixuナイジェリアで発生した246,153ドルの暗号窃盗事件の余波を探る:逮捕、回収作業、そしてデジタル領域におけるより広範な影響。
 Hui Xin
Hui Xin法的緊張が高まる中、バイナンスの元CEOであるChangpeng "CZ" Zhao氏は、UAEへの帰国を妨げようとする米国政府の動きと闘う。
Hui XinBRICS諸国は戦略的な脱ドル運動の先頭に立ち、世界貿易における長年にわたる米ドルの優位に挑戦し、伝統的な金融秩序の変革を示唆している。
 Jasper
Jasperジェイ・クレイトン前SEC委員長は、リップル社との過去の法的衝突にもかかわらず、暗号通貨を意外にも支持しており、リップル社のブラッド・ガーリングハウス最高経営責任者(CEO)は、クレイトン氏の新たな支持の真摯さに疑問を呈し、彼の発展的なスタンスにおける潜在的な矛盾についての懸念を提起している。
Jasperこの動きは、日本政府が2023年6月3日に、安定コインの規制を目的とした決済サービス法を改正したことを受けたものだ。
 Davin
Davin北朝鮮のハッキング集団「キムスキー」が、暗号通貨窃盗の手口で韓国政府関係者を標的にしたため、サイバーセキュリティ対策が急ピッチで進められている。
Hui Xinノーザン・アトランティック航空は、航空機整備にAIロボットを活用することで、燃料消費量の削減、グリコールの再利用、検査の90%迅速化を実現し、環境に優しい空の実現に向けて大胆な一歩を踏み出した。
Jasper日本の国税庁(NTA)は、2022年度に615件の問い合わせのうち548件が確認され、暗号税の違反が増加していることを明らかにした。1件当たりの平均申告漏れ所得は20万6000ドルに減少したものの、累積額は1億2650万ドルに増加し、コインを保有する企業に対する現行の仕組みの影響に対する批判の中で、日本における税制改革を求める声が高まっている。
Jixu