コネクティビティの新時代:スターリンクの画期的な動き
イーロン・マスクのスターリンクは、遠隔地でのスマートフォン接続を可能にする「Direct-to-Cell」衛星技術を導入し、暗号コミュニティから好意的な反応を集めている。
 Alex
Alex

Source: heart of the machine
2月に突然、OpenAIとの協力関係の終了を発表した有名なロボット・スタートアップのFigure AIは、今週木曜日の夜にその理由を公表した。

Helix (ヘリックス) は、知覚、言語理解、行動を統合した汎用視覚言語行動 (VLA) モデルです。知覚、言語理解、学習制御を統合し、ロボット工学における長期的な課題を克服します。
Helixは多くの初の技術を生み出しました:
Full-body control: 手首、胴体、頭部、個々の指をカバーする、ヒューマノイドロボットの上半身の初の高速連続制御VLAモデルです。ロボットコラボレーション:2台のロボットが1つのモデル制御でコラボレーションし、これまでに見たことのないタスクを達成することができます;
何でもつかむ:自然言語のコマンドに従うだけで、これまでに出会ったことのない何千ものアイテムを含む、どんな小さなオブジェクトでも拾うことができます;
単一のニューラルネットワーク:Helix物体を掴んで置いたり、引き出しや冷蔵庫を使ったり、ロボット間で相互作用したりといったすべての行動を学習するために、ニューラルネットワークの重みのセットを使用します。ローカライゼーション:Helixは、ローカルGPU上で動作する史上初のロボットVLAモデルであり、すでに商業的な着陸準備が整っています。
今年、自動車メーカーが大規模なエンドツーエンド技術を推進し、VLA駆動ロボットが実用化に向けてカウントダウンしているスマートドライビングの分野において、Helixは具現化された知能における大きなブレークスルーです。
Helixニューラルネットワークの重みのセットは、2台のロボットで同時に動作し、連動してこれまでに見たことのない食料品を整理します。
フィギュアは、家庭環境はロボット工学が直面する最大の課題だと言います。管理された工業環境とは異なり、家庭には壊れやすいガラス製品、くしゃくしゃの衣服、散らばったおもちゃなど、無数の不規則な物体があり、それぞれが形、大きさ、色、質感において予測不可能です。ロボットが家庭で役立つためには、要求に応じてインテリジェントな新しい動作を生成できる必要があります。
現在のロボット工学技術は、家庭環境には対応できません。現在のところ、ロボットに新しい行動を1つ教えるにも、かなりの人手が必要です。博士号レベルの専門家による何時間もの手動プログラミングか、何千回ものデモンストレーションが必要で、どちらも法外なコストがかかります。
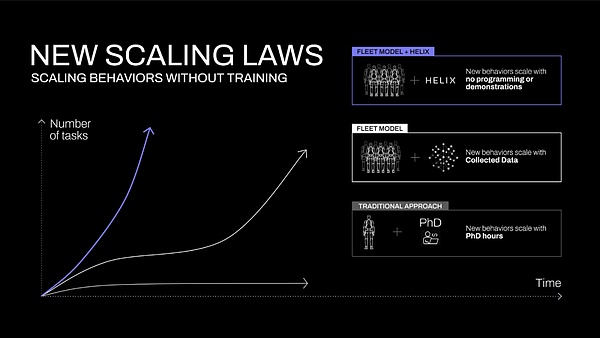
図1:ロボットのスキルの新しい拡張曲線を取得するためのさまざまなアプローチ。ロボットスキルの新しい拡大曲線を取得するためのさまざまなアプローチ。従来のヒューリスティクスでは、スキルの成長は専門家による手動スクリプトに依存している。従来のロボット模倣学習では、スキルの拡張は収集されたデータに依存している。一方、Helixでは、新しいスキルは言語によって即座に指定することができます。
現在、AIの他の分野では、この瞬時に汎化する能力を習得している。視覚言語モデル(VLM)に取り込まれた豊富な意味的知識が、単純にロボットのアクションに直接翻訳されるようになれば、技術的なブレークスルーが達成されるかもしれません。
この新しい能力は、ロボット工学の発展の軌跡を根本的に変えるだろう(図1)。このギャップを埋めるために、FigureはHelixを開発しました。
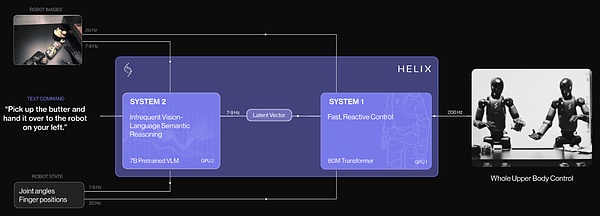
Helix は、ロボット工学のための最初の「システム1+システム2」VLAモデルです。ヒューマノイドロボットの上半身全体を高速で器用に制御するための「システム1+システム2」VLAモデルです。
従来のアプローチは、VLMバックボーンは汎用的だが高速ではなく、ロボットの視覚運動戦略は高速だが十分に汎用的ではないという、根本的なトレードオフに直面していました。 Helixは、エンドツーエンドで通信するように訓練された2つの補完的なシステムによって、このトレードオフを解決します。
システム1 (S1): 高速応答の視覚運動戦略で、S2によって生成された潜在的な意味表現を、200 Hzで正確な連続ロボット動作に変換します。
システム2 (S2): オンボードのインターネット上で事前訓練されたVLMで、シーン理解のために7~9 Hzで動作し、広範な汎化のために言語理解します。
このように切り離されたアーキテクチャにより、各システムが最適なタイムスケールで動作することができます。S2は高レベルの目標について「ゆっくり考える」ことができ、S1はロボットがリアルタイムで実行し適応する行動について「速く考える」ことができます。例えば、協調行動(下記参照)において、S1はS2の意味的目標を維持しながら、パートナーロボットの変化する行動に素早く適応することができる。
 Helixは、ロボットが素早くきめ細かい動作調整を行うことを可能にします。
Helixは、ロボットが素早くきめ細かい動作調整を行うことを可能にします。
Helixは、既存のアプローチに対していくつかの重要な利点を持つように設計されています。
Speed and generalisation: Helixは、単一のタスクに特化した行動クローニング戦略に匹敵する速度でありながら、ゼロサンプルで何千もの新しいテストオブジェクトに汎化することができます。
Speed and generalisation: Helixは、単一のタスクに特化した行動クローニング戦略に匹敵する速度でありながら、何千もの新しいテストオブジェクトに汎化することができます。
スケーラビリティ:Helixは高次元行動空間の連続制御を直接出力するため、以前のVLAアプローチで使用されていた複雑な行動トークン化スキームを避けることができます。
アーキテクチャのシンプルさ:Helixは標準的なアーキテクチャを使用しています。
懸念の分離:S1とS2を分離することで、統一されたビューイングスペースやアクションの表現を見つけることに制約されることなく、各システムを別々に反復することができました。
図に、多様な遠隔操作行動の高品質なマルチロボット、マルチオペレーターデータセット(合計約500時間)からのモデルとトレーニングの詳細の一部を示します。自然言語条件でのトレーニングペアを生成するために、エンジニアは自動的にラベル付けされた視覚言語モデル(VLM)を使用して、事後指示を生成しました。
このVLMは、ロボットのオンボードカメラからセグメント化されたビデオクリップを処理し、"ビデオに映っている行動を実行するために、ロボットにどのような指示を与えますか?"と尋ねます。トレーニング中に処理されたすべての項目は、データの汚染を防ぐために評価から除外されます。
Helixシステムは2つの主要コンポーネントで構成されています:S2はVLMバックボーン、S1は潜在条件付き視覚運動変換器です。VLMはインターネット規模のデータで事前に訓練されています。単眼のロボット画像とロボットの状態情報(手首のポーズや指の位置を含む)を処理し、視覚言語埋め込み空間に投影します。S2は、希望する動作を指定する自然言語命令と組み合わせることで、すべての意味的タスク関連情報を連続的な潜在ベクトルに抽出し、S1に渡して低レベルの動作を制御する。
S1は、低レベルの制御を担当する8000万パラメータのクロスアテンション・エンコーダー・デコーダー・トランスフォーマーである。視覚処理には、完全に畳み込まれたマルチスケールの視覚バックボーンネットワークに依存しており、このネットワークはシミュレートされた環境での事前学習によって初期化される。S1はS2と同じ画像と状態の入力を受け取るが、より応答性の高い閉ループ制御のために、より高い頻度でこれらの入力を処理する。S2からの潜在ベクトルはS1のラベリング空間に投影され、タスク条件を提供するためにシーケンス次元に沿ってS1視覚バックボーンネットワークによって抽出された視覚的特徴と接続される。
動作中、S1は200Hzで完全な上半身のヒューマノイド制御を出力します。これには、所望の手首の姿勢、指の屈曲と外転制御、および胴体と頭部の方向目標が含まれます。図は、行動空間に合成された「タスク完了のパーセンテージ」アクションを追加し、Helixが独自の終了条件を予測できるようにすることで、学習した複数の行動を並べ替えることが容易になります。行動を並べ替えることが容易になります。
Helixのトレーニングは完全にエンドツーエンドです:生のピクセルとテキストコマンドから、標準的な回帰損失で連続的なアクションにマッピングします。
勾配の逆伝播経路は、S1の振る舞いを制御するために使用される隠れた通信ベクトルによって、S1からS2へと行われます。
Helixは、特定のそうそうたるタスクのために調整される必要はなく、単に単一のトレーニングフェーズとニューラルネットワークの重みのセットを維持するだけであるため、タスクごとに個別のアクションヘッダや微調整フェーズを必要としない。
トレーニング中、S1入力とS2入力の間に時間オフセットも追加される。このオフセットは、S1とS2の展開の推論遅延のギャップに一致するように較正され、展開中のリアルタイムの制御要件がトレーニングに正確に反映されるようにします。
Helixのトレーニング設計は、デュアル低消費電力組み込みGPUを搭載した図上ロボットへのモデルの効率的な並列展開を可能にします。 推論パイプラインはS2(高レベルのステガノグラフィ)とS1(低レベルの制御)モデルに分割され、それぞれが専用GPUで実行されます。それぞれ専用のGPUで実行されます。
S2は、最新のオブザベーション(オンボードカメラとロボットの状態)と自然言語コマンドを処理するための非同期バックグラウンドプロセスとして実行されます。高レベルの行動意図をエンコードする共有メモリの隠しベクトルを常に更新します。
S1は独立したリアルタイムプロセスとして実行され、その目的は、上半身の動き全体をスムーズに実行できるようにするために必要な、重要な200Hzの制御ループを維持することです。その入力は最新のオブザベーションと最新のS2暗黙ベクトルです。S2推論とS1推論の間には固有の速度差があるため、S1はロボットの観察に対してより高い時間分解能で自然に実行され、その結果、応答制御のための緊密なフィードバックループを作成します。
この展開戦略は、トレーニング中に導入される時間的オフセットを意図的に反映することで、トレーニング推論分布ギャップを最小化することができる。この非同期実行モデルにより、両方のプロセスがそれぞれの最適な頻度で実行されるため、Helixは最も高速な単一タスク模倣学習戦略と同等の速度で実行することができます。
興味深いことに、FigureがHelixをリリースした後、清華大学の博士課程学生であるYanjiang Guo氏は、このアイデアは彼らのCoRL 2024論文の1つに似ていると発言しました。

論文は、https.//arxiv.org/abs/2410.05273
Fine-Grained VLA Full Upper-Body Control
Helix は、周波数200Hzで35自由度の運動空間を協調制御できます。Helixは、個々の指の動きから、エンドエフェクターの軌道、頭部の視線、胴体の姿勢まで、すべてを制御します。
頭部と胴体の制御には独特の課題があります。頭部と胴体が動くと、ロボットが到達できる範囲と見ることができる範囲が変わり、過去には不安定につながったフィードバックループが生じます。
ビデオ3は、この調整を実際に示しています。ロボットは、把持のための正確な指の制御を維持しながら、最適なリーチのために胴体を調整しながら、頭で両手をスムーズに追跡します。これまで、このような高次元の運動空間でこのレベルの精度を達成することは、たとえ単一の既知のタスクであっても困難でした。Figureによると、タスクやオブジェクトを横断して汎化する能力を維持しながら、このレベルのリアルタイムのコーディネーションを実証できたVLAシステムはこれまでありませんでした。

Zero-Sample Multi-Robot Collaboration
Figureは、2台のFigureロボットが協力してゼロサンプルの食料品貯蔵を達成するという、難しいマルチインテリジェンス・シナリオでHelixの限界に挑戦したと述べています。
ビデオ1には、2つの基本的な進歩が示されています。2台のロボットは、まったく新しい商品(トレーニング中に遭遇したことのないアイテム)の操作に成功し、幅広い形状、サイズ、および素材に対する強固な汎化を実証しています。
さらに、2台のロボットは同じHelixモデルの重みを使用して動作するため、ロボット固有のトレーニングや明示的な役割分担は必要ありません。両者の協調は、「ビスケットの入った袋を右のロボットに渡してください」「左のロボットからビスケットの入った袋を取って、開いている引き出しに入れてください」といった自然言語による合図によって実現されます(ビデオ4参照)。これは、VLAを用いて、複数のロボット間の柔軟で拡張性のある共同作業を実証した初めての例である。全く新しい物体を扱うことに成功したことを考えると、この成果は特に注目に値する。

Helixは精密な複数ロボットの共同作業を可能にします。ロボットのコラボレーション
「何でも拾う」能力の急増


「[X]を拾う」コマンド1つで、Helixを搭載したFigureロボットは基本的にどんな小さな家庭用品でも拾うことができる。系統的なテストでは、事前のデモンストレーションやカスタムプログラミングなしで、ロボットはガラス製品やおもちゃから工具や衣類まで、部屋に散らかった何千もの新しいアイテムをうまく処理しました。
特に注目すべき点は、Helixがインターネット規模の言語理解と正確なロボット制御のリンクを確立できることだ。例えば、「砂漠のオブジェクトを拾う」ように促されたとき、Helixはこの抽象概念に一致するサボテンのおもちゃを識別するだけでなく、最も近い手を選択し、正確なモーターコマンドで安全にそれをつかむことができます。
株式会社フィギュアは、「構造化されていない環境にヒューマノイドロボットを配備するために、この多目的な『音声から動作へ』の把持機能は、エキサイティングな新しい可能性を開きます」と述べています。

Helixは、「[ X ]を拾う」などの高レベルの単語を翻訳することができます。X]」などの高レベルのコマンドを低レベルのアクションに変換します。
Helixのトレーニングは効率的
Helixは非常に少ないリソースで強力なオブジェクトの汎化を達成する、とFigure氏は言います。Helixは、過去に収集されたVLAデータセットのごく一部(<5%)であり、マルチロボットによる体現収集や複数の学習フェーズに依存していません"。彼らは、この収集サイズは現代の単一タスク模倣学習データセットに近いと指摘している。比較的小さなデータ要件にもかかわらず、Helixは、より困難な行動空間、すなわち、高レート、高次元出力を伴う完全な上半身のヒューマノイド制御へと拡張することができます。
単一の重みセット
既存のVLAシステムは、一般的に、異なる高レベルの動作を実行するために、パフォーマンスを最適化するための特別な微調整や専用のアクションヘッドを必要とします。驚くべきことに、Helixは、1組のニューラルネットワークの重み(システム2は7B、システム1は80M)だけを使用して、さまざまなコンテナ内のオブジェクトをピックアップして配置したり、引き出しや冷蔵庫を操作したり、器用な複数のロボットのハンドオフを調整したり、何千もの新しいオブジェクトを操作したりするような動作を実行します。

「Pick up Helix(ヘリックスを拾う)」
Helixは、自然言語によってヒューマノイドロボットの上半身全体を直接制御する、初の「視覚-言語-動作」モデルです。以前のロボットシステムとは異なり、Helixは、タスクに特化したデモンストレーションや大規模な手動プログラミングを必要とすることなく、視野の長い、協調的で器用な操作をその場で生成することができます。
Helixは、自然言語のコマンドだけで、形、大きさ、色、材質が異なる何千もの斬新な家庭用品を拾い上げ、強力な物体汎化能力を実証しています。「これは、ヒューマノイドロボットの行動を拡張するというFigureの変革的な一歩を示すものであり、ロボットが日常的な家庭環境でますますアシストするようになるにつれて、この一歩が重要になると考えています」と同社は述べています。
これらの初期の結果は確かにエキサイティングなものですが、全体的に見れば、私たちが上で見たものはまだ概念実証であり、何が可能かを示しているにすぎません。本当の変化は、Helixが実際に大規模に展開できるようになったときに起こるだろう。遅かれ早かれ、その日はやってくるだろう!
ところで、Figureのリリースは、今年の具現化された知性における多くのブレークスルーのほんの一歩に過ぎないかもしれない。今朝早く、1X Roboticsも新製品を間もなく発売すると発表した。
イーロン・マスクのスターリンクは、遠隔地でのスマートフォン接続を可能にする「Direct-to-Cell」衛星技術を導入し、暗号コミュニティから好意的な反応を集めている。
Alexイーサリアムの共同創設者であるVitalik Buterin氏は、イーサリアムの将来的な見通しが慎重ながらも楽観的である一方で、より広範な市場が低迷する中、3,300USDCを送金。
 Kikyo
Kikyo2024年1月1日より、これらの税務報告義務は、2021年11月にジョー・バイデン合衆国大統領が署名したインフラ法案の一部として浮上した。
Alexビットコインと関連銘柄は、規制当局によるビットコインETFの承認が間近に迫っているとの期待に反応し、暗号市場は乱高下を目撃した。ビットコインの価値は、主要暗号関連銘柄の下落とともに5%下落し、市場の期待と不確実性を反映した。
 Joy
Joyサイファーが49%の権益を保有する合弁会社Bear LLCとChief Mountain LLCは、同国から最新のAvalon A1466採掘機を16,700台購入する。
AlexHyperVerseの調査により、検証不可能な信任状を持つCEOが明らかになり、スキームの正当性に疑念が生じる。投資家は、重要な数字をめぐる矛盾の中で財政的混乱に直面し、暗号投資の状況における規制当局の精査の必要性が浮き彫りになった。
Joy蒸気船ウィリー』がパブリックドメインになったことで、ミッキー・ミームコインが誕生し、ノスタルジーと現代のデジタル文化が融合した一方で、ディズニーはより新しい知的財産を守り続けている。
 Brian
BrianSei NetworkのSEIトークンは、並列化されたEVMへの注力の高まりと今後のネットワーク更新の恩恵を受け、急騰している。
Kikyoサイファー・マイニングは、ビットコイン半減に先立ち、テキサス州でのマイニング能力の拡大を目指し、戦略的に16,700の新規マイナーを獲得した。ビットコイン価格への歴史的影響と結びついた強気の見通しで、サイファーは業界の主要プレーヤーとして浮上することを目指している。
Joy中央銀行は、暗号通貨や暗号資産を含む仮想資産サービスの監視の必要性を強調する世界的な動向に注目している。
Alex