نص: لان شي
لقد كانت الأيام العشرة الماضية منذ أن أصبح DeepSeek مشهورًا هي الفترة التي شهدت أكبر قدر من الضوضاء. لأكون صادقًا، فإن معظم منتجات المناقشة لديها شعور بالوقت الإضافي لتلبية مؤشرات الأداء الرئيسية، ويجادل الجميع حول ما إذا كانت بشرية أم وهمية. عدد قليل فقط منهم يتمتع بقيمة الاحتفاظ. ومع ذلك، هناك بودكاستان استفدت منهما كثيرًا بعد الاستماع إليهما. أوصي بهما بشدة.
أحد هذه الأسباب هو أن تشانغ شياو جون دعا بان جياي، وهو طالب دكتوراه من مختبر الذكاء الاصطناعي بجامعة كاليفورنيا في بيركلي، لشرح ورقة DeepSeek جملة بجملة. يمكن أن يؤدي الإخراج عالي الكثافة لمدة 3 ساعات تقريبًا إلى قتل خلايا المخ، لكن الإندورفين الذي يتم إفرازه بعد القتل يكون متفجرًا أيضًا.
الحلقة الأخرى هي مجموعة بودكاست مكونة من ثلاث حلقات لبين تومسون حول DeepSeek، والتي تصل مدتها إلى أكثر من ساعة. هذا الرجل هو مؤسس News Letter وأحد أكثر المحللين خبرة في مجال التكنولوجيا في العالم. يعيش في تايبيه طوال العام ولديه نظرة أعمق إلى الصين/آسيا مقارنة بنظرائه الأميركيين.
لنبدأ بحلقة Zhang Xiaojun. بعد قراءة ورقة DeepSeek، قام الضيف Pan Jiayi بسرعة بتطوير مشروع صغير الحجم لإعادة إنتاج نموذج R1-Zero، والذي حصل على ما يقرب من 10000 نجمة على GitHub.
إن هذا النوع من نقل المعرفة الذي ينتقل من جيل إلى جيل هو في الواقع إسقاط للمثالية في مجال التكنولوجيا. وكما قال فلود سونغ، الباحث في دارك سايد أوف ذا مون، فإن نموذج التفكير الخاص بكيمي k1.5 كان مستوحى في الأصل من مقطعي فيديو أصدرتهما شركة OpenAI. وحتى في وقت سابق، عندما أصدرت جوجل "الاهتمام هو كل ما تحتاجه"، أدركت شركة OpenAI على الفور مستقبل Transformer. إن سيولة الحكمة هي الشرط الأساسي لكل تقدم.
ولهذا السبب شعر الجميع بخيبة أمل شديدة إزاء تصريح مؤسس أنثروبيك داريو أمودي بأن "العلم ليس له حدود، ولكن العلماء لديهم وطن". وبينما كان ينكر المنافسة، كان يتحدى أيضًا الفطرة السليمة الأساسية.
دعنا نعود إلى محتوى البودكاست. ، وعملية العثور على الإجابة كانت جميلة جدًا ؛
- يمكن أن توفر المصدر المفتوح أكثر من المصدر المغلق ، وهو أمر مفيد للغاية لنمو القوى العاملة وإخراج النتائج. لا يزال النموذج السائد محاذاة مع GPT-4 ، وهو أمر نادر للغاية في السوق الذي يدعو إلى "الابتكار المستمر". o1 في حد ذاته هو أيضًا محاولة لخط تقني جديد، باستخدام نماذج اللغة لتعليم الذكاء الاصطناعي التفكير؛
- لقد أعاد o1 تحقيق تحسن خطي في مستوى الذكاء في اختبار المعايير، وهو أمر رائع. لم يكشف التقرير الفني عن الكثير من التفاصيل، ولكن تم ذكر جميع النقاط الرئيسية، مثل قيمة التعلم التعزيزي. التدريب المسبق والضبط الدقيق الخاضع للإشراف يعادلان تزويد النموذج بالإجابات الصحيحة للتقليد. بمرور الوقت، يتعلم النموذج نسخ النموذج، لكن التعلم التعزيزي يسمح للنموذج بإكمال المهمة بنفسه. أنت فقط تخبره ما إذا كانت النتيجة صحيحة أم خاطئة. إذا كانت صحيحة، فافعل المزيد منها، وإذا كانت خاطئة، فافعل القليل منها؛
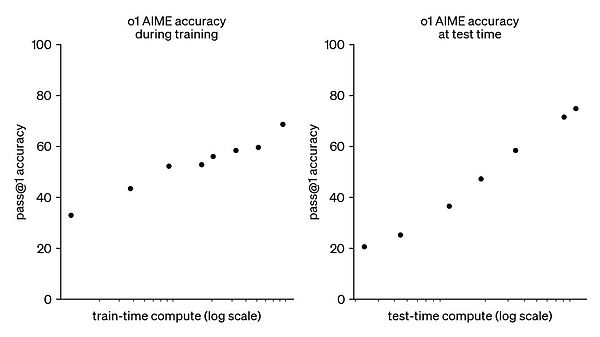
- اكتشف Openai أن التعلم التعزيز يمكن أن ينتج عنه تأثير بالقرب من التفكير البشري (سلسلة من الفكر). في الواقع ، فإن نموذج المنطق هو نتاج الحساب الاقتصادي. تأثير Lier هو نفسه تقريبًا ، لذا فقد بدأت الصناعة الآن في اتخاذ طريق التفكير بأداء أفضل للتكلفة ؛
- قد لا يكون لإطلاق o3-mini في نهاية الشهر الماضي أي علاقة تذكر بـ DeepSeek-R1، لكن سعر o3-mini انخفض إلى ثلث سعر o1-mini، والذي لابد أنه تأثر بشكل كبير. تعتقد OpenAI أن نموذج عمل ChatGPT له خندق، لكن بيع واجهات برمجة التطبيقات ليس كذلك، ويمكن استبداله كثيرًا. كان هناك أيضًا جدل في الصين مؤخرًا حول ما إذا كان ChatBot عملاً جيدًا. من الواضح أن DeepSeek لم يكتشف حتى كيفية التعامل مع هذه الموجة من الزيارات. قد يكون هناك صراع طبيعي بين القيام بسوق على مستوى المستهلك وإجراء أبحاث متطورة؛ في نظر الخبراء الفنيين، فإن DeepSeek-R1-Zero أجمل من R1 لأنه يتطلب تدخلاً بشريًا أقل. لقد توصل النموذج إلى عملية إيجاد الحل الأمثل في آلاف الخطوات من التفكير، ولا يعتمد كثيرًا على المعرفة السابقة. ومع ذلك، نظرًا لأنه لم يتم محاذاته، لا يمكن تسليم R1-Zero للمستخدمين. على سبيل المثال، يتم إخراجه بلغات مختلفة. لذلك في الواقع، لا يزال DeepSeek's R1، الذي تم الاعتراف به في السوق الشامل، يستخدم طرقًا قديمة مثل التقطير والضبط الدقيق وحتى الزرع المسبق لسلاسل التفكير؛ يتضمن هذا مشكلة عدم مزامنة القدرة والأداء. قد لا يكون النموذج ذو أفضل قدرة هو الأفضل أداءً، والعكس صحيح. يرجع الأداء المتميز لـ R1 إلى حد كبير إلى اتجاه الجهد اليدوي. لا يحتوي R1 على مجموعة تدريب حصرية. تحتوي مجموعة كل شخص على شعر كلاسيكي وما إلى ذلك. من غير الممكن أن يعرف R1 أكثر. قد يكون السبب الحقيقي هو شرح البيانات. يقال أن DeepSeek وجد طلابًا من القسم الصيني بجامعة بكين للقيام بالشرح، مما سيحسن بشكل كبير وظيفة المكافأة للتعبير الأدبي. بشكل عام، لا تحب الصناعة استخدام طلاب الفنون الحرة. حقيقة أن ليانغ وينفينج نفسه يقوم أحيانًا بالشرح لا تظهر حماسه فحسب، بل تُظهر أيضًا أن مشروع الشرح وصل منذ فترة طويلة إلى النقطة التي يحتاج فيها إلى اجتياز اختبار محترف لتدريب الذكاء الاصطناعي. تدفع OpenAI أيضًا 100-200 دولار أمريكي في الساعة لدعوة طلاب الدكتوراه للقيام بالشرح لـ o1؛ البيانات وقوة الحوسبة والخوارزميات هي العجلات الثلاث لصناعة النماذج الكبيرة. تأتي الاختراقات الرئيسية لهذه الموجة من الخوارزميات. اكتشف DeepSeek-R1 سوء فهم، أي أن التركيز على وظائف القيمة في الخوارزميات التقليدية قد يكون فخًا. تميل وظائف القيمة إلى إصدار أحكام على كل خطوة من خطوات عملية التفكير، وبالتالي توجيه النموذج إلى المسار الصحيح في كل التفاصيل. على سبيل المثال، عندما يحل النموذج مشكلة 1 + 1 يساوي ماذا، عندما يكون لديه الوهم بأن 1 + 1 = 3، فإنه يبدأ في معاقبته، مثل العلاج بالصدمات الكهربائية، ولا يسمح له بارتكاب الأخطاء؛ هذه الخوارزمية سليمة من الناحية النظرية، لكنها أيضًا مثالية للغاية. ليست كل الأسئلة بسيطة مثل 1+1، خاصة عندما يتم استنتاج آلاف تسلسلات الرموز في سلسلة طويلة من التفكير. إذا كانت كل خطوة تحتاج إلى الإشراف، فإن نسبة المدخلات والمخرجات ستصبح منخفضة للغاية. لذلك، اتخذ DeepSeek قرارًا يتعارض مع التعاليم الأسلاف. لم يعد يستخدم دالة القيمة لإرضاء اضطراب الوسواس القهري أثناء البحث. إنه يسجل الإجابات فقط ويسمح للنموذج بمعرفة كيفية الحصول على الإجابة بالخطوات الصحيحة. حتى لو كان لديه حل 1+1=3، فلن يبالغ في تصحيحه. بدلاً من ذلك، سيدرك أن هناك خطأ ما أثناء عملية التفكير ويجد أنه لا يمكنه الحصول على الإجابة الصحيحة عن طريق الحساب بهذه الطريقة، ثم يقوم بتصحيح نفسه؛ الخوارزميات هي أكبر ابتكار لـ DeepSeek في الصناعة بأكملها، بما في ذلك كيفية التمييز بين ما إذا كان النموذج يقلد أم يستدل. أتذكر أنه بعد ظهور o1، زعم العديد من الأشخاص أن النموذج العام يمكنه أيضًا إخراج سلاسل فكرية من خلال كلمات سريعة، لكن هذه النماذج لم تكن لديها القدرة على الاستدلال. في الواقع، كانت مجرد تقليد. لا يزال يعطي إجابات بالطريقة المعتادة، ولكن من أجل تلبية متطلبات المستخدم، عاد وأعطى أفكارًا بناءً على الإجابات. هذا تقليد، عمل لا معنى له لإطلاق الأسهم أولاً ثم رسم الأهداف. بذلت DeepSeek أيضًا الكثير من الجهود في كسر المكافآت ضد النماذج، بشكل أساسي لمعالجة مشكلة النماذج التي أصبحت ماكرة. لقد خمن تدريجيًا كيفية التفكير للحصول على المكافآت، لكنه لم يفهم حقًا سبب التفكير بهذه الطريقة؛ في السنوات الأخيرة ، كانت الصناعة تتطلع إلى ظهور النماذج في الماضي. تحسين أدائها في إطالة سلسلة تفكيرها بشكل نشط. التعلم المستمر بعد التقطير تم إصدار K1.5 في نفس الوقت مثل Deepseek -R1 ، ولكن نظرًا لأنه لا يعتبر تراكمًا دوليًا غير كافٍ ، فقد تأثرت بتأثيرها في مجال التفكير القصيرة على ذلك ، فهي لا تتأثر بأسباب تقترب من ذلك. انتظر منذ فترة طويلة من الأسئلة-يبدو أن هناك بعض العوائد المنتظمة. في الوقت الحاضر ، لا يزال خندق Openai عميقًا للغاية 3. لم يكن هناك أي ابتكار على المستوى المعماري، وكان تأثير DeepSeek على سوق المصادر المفتوحة غير متوقع على الإطلاق. كانت مجموعة المواهب في Meta قوية للغاية، لكن الهيكل التنظيمي لم يحول هذه الموارد إلى إنجازات تكنولوجية.
وفي حديثه عن بودكاست بن تومسون، فقد قام بالتحقق من صحة حكم بان جيايي في العديد من الأماكن. على سبيل المثال، أزال R1-Zero الميزة التقنية لـ HF (ردود الفعل البشرية) في RLHF، ولكن تم وضع المزيد من المناقشات حول المنافسة الجيوسياسية وماضي الشركات الكبرى. السرد سلس للغاية:
- أحد الدوافع التي دفعت وادي السيليكون إلى المبالغة في التأكيد على سلامة الذكاء الاصطناعي هو أنه يمكن استخدامه لتبرير السلوك المغلق. منذ وقت مبكر من بروتوكول GPT-2، كان المقصود تجنب استخدام نماذج اللغة الكبيرة لتوليد محتوى "مخادع ومتحيز"، لكن "المخادع والمتحيز" بعيد كل البعد عن خطر الانقراض البشري. هذا هو في الأساس استمرار للحرب الثقافية، ويستند إلى افتراض مفاده أنه "عندما تمتلئ الصوامع، فإن آداب السلوك معروفة"، أي أن شركات التكنولوجيا الأمريكية تتمتع بمزايا مطلقة في التكنولوجيا، لذلك نحن مؤهلون لصرف انتباهنا عن مناقشة ما إذا كان الذكاء الاصطناعي تمييزيًا عنصريًا؛
- تمامًا مثل ما قاله Openai عندما قرر إخفاء سلسلة الفكر O1 - قد لا يتم محاذاة سلسلة الفكر الأصلية ، وقد يشعر المستخدمون بالإهانة بعد رؤيته ، لذلك قررنا أن نقطعها ولا تُعرفها على هذا الوضع الصلح في هذا النوع من الرؤوس التي تُعتقد أنها تُعتقد أن هناك أيًا من الأهداف. يعتقد الرئيس التنفيذي السابق لـ Reddit أن وصف Deepseek - هو المدير الفني للاتحاد السوفيتي الأول قبل الولايات المتحدة يختلف عن جميع شركات التكنولوجيا في ذلك الوقت. - يعتقد رون الباحث في OpenAI أن تحسين DeepSeek للترقية للتغلب على شريحة H800 - لا يمكن للمهندسين استخدام CUDA من Nvidia ويمكنهم فقط اختيار PTX الأقل تكلفة - هو عرض خاطئ، لأنه يعني أن الوقت الذي أضاعوه عليه لا يمكن تعويضه، بينما يمكن للمهندسين الأمريكيين التقدم بطلب للحصول على H100 دون قلق. إن إضعاف الأجهزة لا يمكن أن يجلب ابتكارًا حقيقيًا.
- لو كانت شركة جوجل قد استمعت إلى نصيحة رون في عام 2004 ولم "تهدر" الباحثين القيمين لبناء مراكز بيانات أكثر اقتصادا، فربما كانت شركات الإنترنت الأمريكية تستأجر خوادم علي بابا السحابية اليوم. في العقدين الماضيين من تدفق الثروة، فقدت وادي السيليكون القوة الدافعة لتحسين البنية التحتية. اعتادت المصانع الكبيرة والصغيرة على نماذج الإنتاج كثيفة رأس المال وهي سعيدة بتقديم نماذج الميزانية في مقابل الاستثمار. حتى أنهم استخدموا شرائح إنفيديا كضمان. أما عن كيفية تقديم أكبر قدر ممكن من القيمة بموارد محدودة، فلا أحد يهتم؛ ستدعم شركات الذكاء الاصطناعي بالتأكيد مفارقة جيفونز، أي أن الحوسبة الأرخص تخلق استخدامًا أكثر، لكن السلوك الفعلي في السنوات القليلة الماضية كان غير متسق، لأن كل شركة أظهرت تفضيلًا للبحث على التكلفة، حتى جلبت DeepSeek حقًا مفارقة جيفونز إلى أعين الجميع؛ - تزداد قيمة شركة إنفيديا، ويصبح سعر سهم إنفيديا أكثر خطورة. ويمكن أن يتعايش هذان الأمران. إذا كان بإمكان DeepSeek تحقيق مثل هذا الإنجاز على شريحة مقيدة للغاية، فتخيل مقدار التقدم التكنولوجي الذي سيحدث عندما يحصلون على موارد حوسبة كاملة الطاقة. هذا كشف ملهم للصناعة بأكملها، لكن سعر سهم إنفيديا يعتمد على افتراض أنها المورد الوحيد، والذي قد يكون مزيفًا؛
- تختلف الشركات التكنولوجية الصينية والأمريكية بشكل واضح في حكم القيمة لمنتجات الذكاء الاصطناعي. تعتقد الصين أن التمايز يكمن في تحقيق هيكل تكلفة متفوق، وهو ما يتفق مع إنجازاتها في الصناعات الأخرى. تعتقد الولايات المتحدة أن التمايز يأتي من المنتج نفسه وهامش الربح الأعلى الناتج عن هذا التمايز، لكن الولايات المتحدة بحاجة إلى التفكير في عقلية الفوز بالمنافسة من خلال رفض الابتكار، مثل تقييد الشركات الصينية من الحصول على الرقائق اللازمة لأبحاث الذكاء الاصطناعي؛
- بغض النظر عن مدى جودة سمعة كلود في سان فرانسيسكو، فمن الصعب تغيير ضعفه الطبيعي في نموذج مبيعات واجهة برمجة التطبيقات، وهو أنه من السهل جدًا استبداله. يسمح ChatGPT لشركة OpenAI بمقاومة أكبر للمخاطر كشركة تكنولوجيا استهلاكية. ومع ذلك، في الأمد البعيد، سيفيد DeepSeek كل من أولئك الذين يبيعون الذكاء الاصطناعي وأولئك الذين يستخدمون الذكاء الاصطناعي. يجب أن نكون ممتنين لهذه الهدية السخية.
حسنًا، هذا كل شيء. آمل أن تساعدك هذه المهمة على فهم الأهمية الحقيقية لـ DeepSeek لصناعة الذكاء الاصطناعي بشكل أفضل بعد انتشارها على نطاق واسع.


 Joy
Joy


