المؤلف: Su Yang، Hao Boyang؛ المصدر: Tencent Technology
باعتباره "بائع المجرفة" في عصر الذكاء الاصطناعي، كان هوانغ رينكسون وشركته NVIDIA يؤمنان دائمًا بأن قوة الحوسبة لا تنام أبدًا. في كلمته في مؤتمر GTC، قال هوانغ رينكسون إن الاستدلال زاد الطلب على قوة الحوسبة 100 مرة. في مؤتمر GTC اليوم، كشف هوانغ رينكسون عن وحدة معالجة الرسومات Blackwell Ultra الجديدة، بالإضافة إلى وحدات تخزين الخوادم المشتقة منها للاستدلال والوكيل، بما في ذلك مجموعة RTX المستندة إلى بنية Blackwell. كل هذا مرتبط بقوة الحوسبة، ولكن الأهم هو كيفية استخدام قوة الحوسبة الهائلة بشكل معقول وفعال. يرى هوانغ رينكسون أن الوصول إلى الذكاء الاصطناعي العام يتطلب قوة حاسوبية، كما أن الروبوتات الذكية المتجسدة تتطلب قوة حاسوبية، وبناء الكون ونماذج العوالم يتطلب قوة حاسوبية أكبر. أما بالنسبة لقوة الحوسبة اللازمة لبناء "عالم موازٍ" افتراضي، فقد أجابت إنفيديا على هذا السؤال - 100 ضعف ما كانت عليه في الماضي. لدعم وجهة نظره، عرض هوانغ رينكسون مجموعة بيانات في موقع GTC - في عام 2024، ستشتري أكبر أربعة مصانع سحابية في الولايات المتحدة ما مجموعه 1.3 مليون رقاقة معمارية من طراز Hopper. وبحلول عام 2025، سيرتفع هذا الرقم إلى 3.6 مليون وحدة معالجة رسومية من طراز Blackwell. فيما يلي بعض النقاط الرئيسية لمؤتمر GTC 2025 الذي نظمته شركة NVIDIA، والذي أعدته شركة Tencent Technology: 1) معالج Blackwell Ultra، "القنبلة النووية السنوية"، يُحدث فرقًا هائلاً. أطلقت NVIDIA معالج Blackwell وأطلقت شريحة GB200 في مؤتمر GTC العام الماضي. وقد خضع الاسم الرسمي لهذا العام لتعديل طفيف، حيث لم يعد يُسمى GB300 كما أشيع سابقًا، بل أصبح يُسمى Blakwell Ultra.
ولكن من وجهة نظر الأجهزة، تم استبدال ذاكرة HBM الجديدة بناءً على ذاكرة العام الماضي. باختصار، Blackwell Ultra = إصدار Blackwell ذو الذاكرة الكبيرة. يتكون معالج بلاكويل ألترا من معالجين بتقنية TSMC N4P (5 نانومتر)، ورقائق بنية بلاكويل، ووحدة معالجة مركزية Grace، وهو مزود بذاكرة HBM3e متطورة مكونة من 12 طبقة. تمت زيادة سعة ذاكرة الفيديو إلى 288 جيجابايت. وكما هو الحال في الجيل السابق، يدعم المعالج الجيل الخامس من تقنية NVLink، ويمكنه تحقيق عرض نطاق ترددي للربط بين الرقاقات يبلغ 1.8 تيرابايت/ثانية.

معلمات أداء NVLink للأجيال السابقة
بناءً على ترقية التخزين، يمكن أن تصل قوة الحوسبة الدقيقة FP4 لوحدة معالجة الرسومات Blackwell إلى 15PetaFLOPS، وسرعة الاستدلال القائمة على آلية تسريع الانتباه أسرع بمقدار 2.5 مرة من سرعة شريحة بنية Hopper.
2) Blackwell Ultra NVL72: خزانة مخصصة لمنطق الذكاء الاصطناعي

بالتحويل إلى الوقت، لنفس مهمة التفكير، يحتاج H100 إلى العمل لمدة 1.5 دقيقة، بينما يمكن لـ Blackwell Ultra NVL72 إكمالها في 15 ثانية.
 وفقًا للمعلومات المقدمة من NVIDIA ، من المتوقع أن تكون المنتجات ذات الصلة Blackwell NVL72 متوفرة في النصف الثاني من عام 2025. يشمل العملاء مصنعو الخوادم ، ومصانع السحابة ، ومقدمي خدمات الحوسبة: /p>
وفقًا للمعلومات المقدمة من NVIDIA ، من المتوقع أن تكون المنتجات ذات الصلة Blackwell NVL72 متوفرة في النصف الثاني من عام 2025. يشمل العملاء مصنعو الخوادم ، ومصانع السحابة ، ومقدمي خدمات الحوسبة: /p>
15 شركات تصنيع بما في ذلك Cisco/Dell/HPE/Lenovo/supermicro
مصانع السحابة
المنصات الرئيسية مثل AWS/Google Cloud/Azure/Oracle Cloud
مزودو خدمات تأجير قوة الحوسبة
CoreWeave/Lambda/Yotta، إلخ.
3) الإعلان المسبق عن شريحة Rubin GPU "القنبلة النووية" الحقيقية
وفقًا لخريطة طريق NVIDIA، سيكون الملعب الرئيسي لـ GTC2025 هو Blackwell Ultra. ومع ذلك، اغتنم هوانغ رينكسون أيضًا هذه الفرصة لمعاينة الجيل التالي من وحدة معالجة الرسومات المستندة إلى بنية Rubin والتي سيتم إطلاقها في عام 2026 والخزانة الأقوى Vera Rubin NVL144 - 72 وحدة معالجة مركزية Vera + 144 وحدة معالجة رسومات Rubin، باستخدام شرائح HBM4 مع 288 جيجابايت من ذاكرة الفيديو، ونطاق ترددي لذاكرة الفيديو يبلغ 13 تيرابايت/ثانية، ومجهزة ببطاقات الشبكة NVLink وCX9 من الجيل السادس.
ما مدى قوة هذا المنتج؟ تصل قوة الحوسبة الاستدلالية بدقة FP4 إلى 3.6ExaFLOPS، وتصل قوة الحوسبة التدريبية بدقة FP8 أيضًا إلى 1.2ExaFlOPS، وهو ما يزيد بمقدار 3.3 مرة عن أداء Blackwell Ultra NVL72. إذا كنت تعتقد أن هذا غير كافٍ، فلا بأس. في عام ٢٠٢٧، ستتوفر وحدة Rubin Ultra NVL576 أقوى، بقوة حوسبة تبلغ ١٥ إكسافلوبس و٥ إكسافلوبس في استدلال الدقة FP4 وتدريب الدقة FP8 على التوالي، أي ما يعادل ١٤ ضعفًا من بلاكويل Ultra NVL72. 4) إصدار Blackwell Ultra من "مصنع الحوسبة الفائقة" DGX Super POD بالنسبة للعملاء الذين لا يمكن تلبية احتياجاتهم بواسطة Blackwell Ultra NVL72 في هذه المرحلة والذين لا يحتاجون إلى بناء مجموعات الذكاء الاصطناعي فائقة الحجم، فإن حل NVIDIA هو مصنع الحوسبة الفائقة DGX Super POD AI الذي يعمل بنظام التوصيل والتشغيل والذي يعتمد على Blackwell Ultra.
بصفته مصنعًا للحوسبة الفائقة للذكاء الاصطناعي جاهزًا للتشغيل، صُمم DGX Super POD بشكل أساسي لسيناريوهات الذكاء الاصطناعي، مثل الذكاء الاصطناعي التوليدي، ووكيل الذكاء الاصطناعي، والمحاكاة الفيزيائية، مما يُغطي احتياجات توسيع قوة الحوسبة للعمليات بالكامل، بدءًا من مرحلة ما قبل التدريب وما بعده، وصولًا إلى بيئة الإنتاج. تُقدم Equinix، بصفتها أول مُزود خدمة، دعمًا للبنية التحتية للتبريد السائل/التبريد الهوائي.
 يتم تقسيم DGX Super POD على أساس Blackwell Ultra إلى نسختين:
يتم تقسيم DGX Super POD على أساس Blackwell Ultra إلى نسختين:
جهاز DGX SuperPOD مع DGX B300 مدمج. لا يحتوي هذا الإصدار على شريحة وحدة المعالجة المركزية Grace، ويوفر مساحة توسعة إضافية، ويستخدم نظام تبريد هوائي. يُستخدم بشكل رئيسي في مراكز البيانات العادية على مستوى المؤسسات.
5) DGX Spark وDGX Station
في يناير من هذا العام، عرضت NVIDIA منتجًا حاسوبيًا ذكيًا مفاهيميًا بسعر 3000 دولار أمريكي في معرض CES - Project DIGITS. والآن أصبح اسمه الرسمي DGX Spark. من حيث معلمات المنتج، فهو مزود بشريحة GB10، مع قوة حوسبة تبلغ 1 PetaFlops بدقة FP4، وذاكرة LPDDR5X مدمجة بسعة 128 جيجابايت، وبطاقة شبكة CX-7، وتخزين NVMe بسعة 4 تيرابايت، وتشغيل نظام تشغيل DGX OS مخصص استنادًا إلى Linux، ودعم الأطر مثل Pytorch، ومثبت مسبقًا ببعض أدوات تطوير برامج الذكاء الاصطناعي الأساسية التي تقدمها NVIDIA، ويمكنه تشغيل 200 مليار نموذج معلمة. حجم الجهاز بالكامل يُشبه حجم جهاز ماك ميني. يُمكن ربط جهازي DGX Spark معًا، ويُمكنهما تشغيل نماذج بأكثر من 400 مليار مُعامل. على الرغم من أننا نقول إنه جهاز كمبيوتر ذكاء اصطناعي، إلا أنه لا يزال ينتمي إلى فئة الحوسبة الفائقة، لذا يتم وضعه في سلسلة منتجات DGX بدلاً من المنتجات المخصصة للمستهلك مثل RTX. ومع ذلك، اشتكى البعض من هذا المنتج. الأداء المعلن عنه لبطاقة FP4 ضعيف الاستخدام. عند تحويلها إلى دقة FP16، لا يمكنها منافسة سوى بطاقة RTX 5070 أو حتى بطاقة Arc B580 التي يبلغ سعرها 250 دولارًا أمريكيًا، لذا فإن أداء التكلفة منخفض للغاية.

جهاز كمبيوتر DGX Spark ومحطة عمل DGX
بالإضافة إلى جهاز DGX Spark المُسمى رسميًا، أطلقت NVIDIA أيضًا محطة عمل ذكاء اصطناعي تعتمد على Blackwell Ultra. تحتوي هذه المحطة على وحدة معالجة مركزية Grace مدمجة ووحدة معالجة رسومية Blackwell Ultra، مع ذاكرة موحدة سعة 784 جيجابايت وبطاقة شبكة CX-8، مما يوفر قوة حوسبة ذكاء اصطناعي تبلغ 20 بيتافلوب (غير مُعلنة رسميًا، ونظريًا بدقة FP4). 6) RTX تكتسح أجهزة الكمبيوتر ذات الذكاء الاصطناعي وتسعى أيضًا لدخول مراكز البيانات. جميع وحدات تخزين المنتجات التي طُرحت سابقًا تعتمد على وحدات معالجة مركزية من Grace ووحدات معالجة رسوميات Blackwell Ultra، وجميعها منتجات موجهة للمؤسسات. ونظرًا لاهتمام الكثيرين بالاستخدام الرائع لمنتجات مثل RTX 4090 في مجال الذكاء الاصطناعي، فقد عززت NVIDIA دمج سلسلتي Blackwell وRTX في هذه الدورة، وأطلقت عددًا كبيرًا من وحدات معالجة الرسوميات المخصصة لأجهزة الكمبيوتر ذات الذكاء الاصطناعي والمزودة بذاكرة GDDR7 مدمجة، والتي تغطي أجهزة الكمبيوتر المحمولة والمكتبية وحتى مراكز البيانات.
ما سبق هو مجرد بعض وحدات التخزين (SKUs) المخصصة لسيناريوهات مختلفة استنادًا إلى شريحة Blackwell Ultra، بدءًا من محطات العمل ووصولًا إلى مجموعات مراكز البيانات. تُطلق عليها NVIDIA اسم "عائلة Blackwell"، والترجمة الصينية "مجموعة حلول Blackwell" هي الأنسب.
NVIDIA Photonics: نظام CPO يقف على أكتاف زملاء الفريق
مفهوم الوحدة البصرية الإلكترونية المجمعة (CPO) هو ببساطة تجميع شريحة التبديل والوحدة البصرية معًا، مما يمكنه تحويل الإشارات البصرية إلى إشارات كهربائية والاستفادة الكاملة من أداء نقل الإشارات البصرية. قبل ذلك، كان قطاع تقنية المعلومات يناقش منتج تبديل الشبكة CPO من إنفيديا، ولكن تأخر إطلاقه. قدّم هوانغ رينكسون شرحًا مباشرًا، حيث أوضح أنه نظرًا للاستخدام المكثف لوصلات الألياف الضوئية في مراكز البيانات، فإن استهلاك الشبكات الضوئية للطاقة يعادل 10% من موارد الحوسبة. وتؤثر تكلفة الوصلات الضوئية بشكل مباشر على شبكة توسيع نطاق عقد الحوسبة وتحسين كثافة أداء الذكاء الاصطناعي.

معلمات شريحتي Quantum-X و Spectrum-X المغلفتين بالسيليكون الفوتوني المعروضتين في GTC
في GTC لهذا العام، أطلقت NVIDIA شريحة Quantum-X المغلفة بالسيليكون الفوتوني المغلفة بالسيليكون، وشريحة Spectrum-X المغلفة بالسيليكون الفوتوني، وثلاثة منتجات تبديل مشتقة: Quantum 3450-LD و Spectrum SN6810 و Spectrum SN6800.
Quantum 3450-LD: 144 منفذًا بسرعة 800 جيجابايت/ثانية، عرض نطاق ترددي للوحة الخلفية 115 تيرابايت/ثانية، تبريد سائل
Spectrum SN6810: 128 منفذًا بسرعة 800 جيجابايت/ثانية، عرض نطاق ترددي للوحة الخلفية 102.4 تيرابايت/ثانية، تبريد سائل
Spectrum SN6800: 512 منفذًا بسرعة 800 جيجابايت/ثانية، عرض نطاق ترددي للوحة الخلفية 409.6 تيرابايت/ثانية، تبريد سائل
المنتجات المذكورة أعلاه مصنفة بشكل موحد على أنها "NVIDIA أعلنت شركة NVIDIA عن منصة "فوتونيات" التي تعتمد على التعاون في إنشاء وتطوير منظومة شركاء CPO. على سبيل المثال، مُحسَّن مُعدّل الحلقة الدقيقة (MRM) الخاص بها استنادًا إلى محرك TSMC البصري، ويدعم تعديل الليزر عالي الطاقة والكفاءة، ويستخدم موصل ألياف بصرية قابل للفصل.
الأمر الأكثر إثارة للاهتمام هو أنه وفقًا لمعلومات الصناعة السابقة، تم إنشاء معدل الحلقة الدقيقة (MRM) الخاص بشركة TSMC بواسطة Broadcom استنادًا إلى عملية 3 نانومتر وتقنيات التغليف المتقدمة مثل CoWoS. وفقًا للبيانات المقدمة من NVIDIA، فإن مفاتيح Photonics التي تدمج الوحدات الضوئية تتمتع بتحسين في الأداء بمقدار 3.5 أضعاف مقارنة بالمفاتيح التقليدية، وزيادة بمقدار 1.3 ضعف في كفاءة النشر، وأكثر من 10 أضعاف في مرونة التوسع.
كفاءة النموذج PK DeepSeek: يركز النظام البيئي للبرمجيات على وكيل الذكاء الاصطناعي

رسم هوانغ رينكسون "الصورة الكبيرة" للبنية التحتية للذكاء الاصطناعي على الفور
لأنه في هذه الدورة التدريبية العامة التي استمرت ساعتين، تحدث هوانغ رينكسون فقط عن البرمجيات والذكاء المجسد لمدة نصف ساعة تقريبًا. ولذلك، فإن العديد من التفاصيل يتم استكمالها بوثائق رسمية بدلاً من أن تأتي بالكامل من الميدان. 1) Nvidia Dynamo، برنامج CUDA الجديد الذي أنشأته Nvidia في مجال الاستدلال.
1) Nvidia Dynamo، برنامج CUDA الجديد الذي أنشأته Nvidia في مجال الاستدلال.
إن Nvidia Dynamo هو بالتأكيد القنبلة البرمجية التي تم إصدارها في هذا الحدث.
إنه برنامج مفتوح المصدر تم تصميمه للاستدلال والتدريب والتسريع عبر مركز البيانات بأكمله. بيانات أداء Dynamo صادمة للغاية: على بنية Hopper الحالية، يمكن لـ Dynamo مضاعفة أداء نموذج Llama القياسي. بالنسبة لنماذج الاستدلال المتخصصة مثل DeepSeek، يمكن لتحسين الاستدلال الذكي من NVIDIA Dynamo زيادة عدد الرموز التي يولدها كل وحدة معالجة رسومية بما يزيد عن 30 مرة.
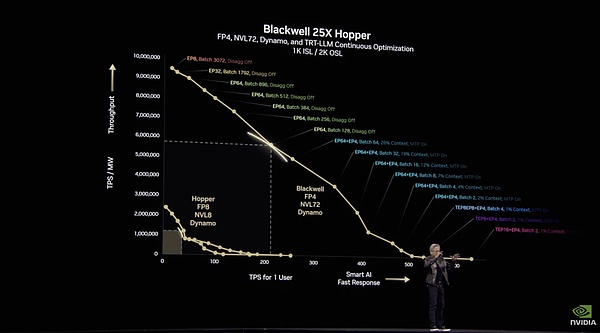
أظهر هوانغ رينكسون أن بلاكويل مع دينامو يمكنه التفوق على هوبر بمقدار 25 مرة.
ترجع هذه التحسينات في دينامو بشكل أساسي إلى التوزيع. يقوم بتوزيع مراحل حسابية مختلفة من LLM (فهم استعلامات المستخدم وتوليد الاستجابات المثلى) على وحدات معالجة الرسومات المختلفة، مما يسمح بتحسين كل مرحلة بشكل مستقل، مما يزيد من الإنتاجية ويسرع الاستجابات.
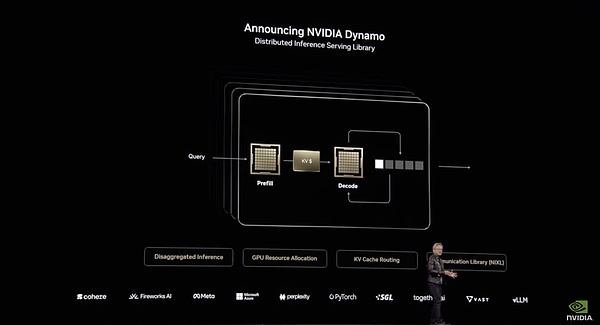
هندسة نظام Dynamo
على سبيل المثال، في مرحلة معالجة الإدخال، أي مرحلة التعبئة المسبقة، يمكن لـ Dynamo تخصيص موارد وحدة معالجة الرسومات بكفاءة لمعالجة إدخال المستخدم. سيستخدم النظام مجموعات متعددة من وحدات معالجة الرسوميات لمعالجة استعلامات المستخدم بالتوازي، على أمل أن تكون معالجة وحدة معالجة الرسوميات أكثر توزيعًا وأسرع. يستخدم دينامو وضع FP4 لاستدعاء وحدات معالجة رسومية متعددة لقراءة أسئلة المستخدم وفهمها بالتوازي. تعالج مجموعة من وحدات المعالجة المعلومات الأساسية المتعلقة بالحرب العالمية الثانية، بينما تعالج مجموعة أخرى البيانات التاريخية المتعلقة بالسبب، وتعالج المجموعة الثالثة التسلسل الزمني وأحداث العملية. تشبه هذه المرحلة قيام عدة مساعدين بحثيين بالبحث عن كمية كبيرة من المعلومات في الوقت نفسه.
عند إنشاء رموز الإخراج، أي مرحلة فك التشفير، يتعين على وحدة معالجة الرسومات أن تكون أكثر تركيزًا وتماسكًا. بالمقارنة مع عدد وحدات معالجة الرسوميات، تتطلب هذه المرحلة نطاقًا تردديًا أكبر لاستيعاب المعلومات الفكرية للمرحلة السابقة، وبالتالي هناك حاجة إلى المزيد من قراءات ذاكرة التخزين المؤقت. يعمل Dynamo على تحسين الاتصال بين وحدات معالجة الرسومات وتخصيص الموارد لضمان توليد استجابة متسقة وفعالة. من ناحية أخرى، فإنه يستفيد بشكل كامل من قدرات الاتصال ذات النطاق الترددي العالي NVLink لهندسة NVL72 لتحقيق أقصى قدر من كفاءة توليد الرموز. من ناحية أخرى، يقوم "الموجه الذكي" بتوجيه الطلب إلى وحدة معالجة الرسوميات التي قامت بتخزين KV (قيمة المفتاح) ذات الصلة مؤقتًا، مما يمكنه من تجنب الحسابات المتكررة وتحسين سرعة المعالجة بشكل كبير. نظرًا لتجنب العمليات الحسابية المتكررة، يتم تحرير بعض موارد وحدة معالجة الرسومات (GPU) ويمكن لـ Dynamo تخصيص هذه الموارد الخاملة بشكل ديناميكي لطلبات واردة جديدة.
تتشابه هذه الهندسة المعمارية إلى حد كبير مع هندسة Mooncake الخاصة بـ Kimi، ولكن NVIDIA قدمت المزيد من الدعم للبنية الأساسية الأساسية. يمكن أن يحسن Mooncake الأداء بنحو 5 مرات، لكن تحسن Dynamo في التفكير أكثر وضوحًا. على سبيل المثال، من بين الابتكارات المهمة في Dynamo، يمكن لـ "GPU Planner" ضبط تخصيص وحدة معالجة الرسومات بشكل ديناميكي وفقًا للحمل، وتعمل "Low Latency Communication Library" على تحسين نقل البيانات بين وحدات معالجة الرسومات، ويقوم "Memory Manager" بنقل بيانات الاستدلال بذكاء بين أجهزة التخزين بمستويات تكلفة مختلفة، مما يقلل من تكاليف التشغيل بشكل أكبر. يقوم جهاز التوجيه الذكي، نظام التوجيه المتوافق مع LLM، بتوجيه الطلبات إلى وحدة معالجة الرسوميات الأكثر ملاءمة لتقليل الحسابات المكررة. تعمل هذه السلسلة من القدرات على تحسين تحميل وحدة معالجة الرسوميات. يمكن توسيع نظام الاستدلال البرمجي هذا بكفاءة إلى مجموعات كبيرة من وحدات معالجة الرسوميات، مما يسمح لاستعلام الذكاء الاصطناعي الواحد بالتوسع بسلاسة إلى ما يصل إلى 1000 وحدة معالجة رسوميات للاستفادة الكاملة من موارد مركز البيانات. بالنسبة لمشغلي وحدة معالجة الرسوميات، أدى هذا التحسين إلى تقليل التكلفة لكل مليون رمز بشكل كبير وزيادة القدرة الإنتاجية بشكل كبير. وفي الوقت نفسه، يمكن لمستخدم واحد الحصول على المزيد من الرموز في الثانية الواحدة، وتكون الاستجابة أسرع، ويتم تحسين تجربة المستخدم.
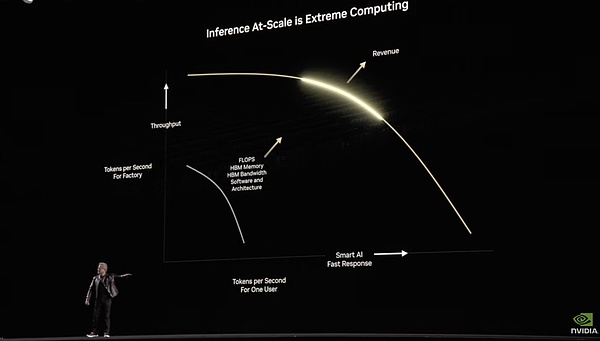
استخدم Dynamo للسماح للخوادم بالوصول إلى خط الربح الذهبي بين سرعة الإنتاج والاستجابة
على عكس CUDA، وهو الأساس الكامن لبرمجة وحدة معالجة الرسومات، فإن Dynamo هو نظام عالي المستوى يركز على التخصيص الذكي وإدارة أحمال الاستدلال واسعة النطاق. وهي مسؤولة عن طبقة الجدولة الموزعة المحسّنة للاستدلال، والتي تقع بين التطبيقات والبنية الأساسية للحوسبة الأساسية. ولكن تمامًا كما أحدثت تقنية CUDA ثورة في مشهد الحوسبة الخاصة بوحدات معالجة الرسوميات منذ أكثر من عقد من الزمان، فقد تنجح تقنية Dynamo أيضًا في إنشاء نموذج جديد لكفاءة البرامج والأجهزة الاستدلالية.
Dynamo هو مصدر مفتوح بالكامل ويدعم جميع الأطر السائدة من PyTorch إلى Tensor RT. حتى لو كان مفتوح المصدر، فهو لا يزال خندقًا. مثل CUDA، فهو يعمل فقط على وحدات معالجة الرسومات NVIDIA وهو جزء من مجموعة برامج الاستدلال بالذكاء الاصطناعي NVIDIA. بفضل هذا الترقية البرمجية، نجحت NVIDIA في بناء دفاعها الخاص ضد شرائح AISC الاستدلالية المخصصة مثل Groq. يتطلب الأمر مزيجًا من البرامج والأجهزة للسيطرة على البنية التحتية للاستدلال. 2) نموذج Llama Nemotron الجديد يتمتع بكفاءة عالية، لكنه لا يزال غير قادر على التفوق على DeepSeek. على الرغم من أن Dynamo مذهل بالفعل من حيث استخدام الخادم، إلا أن NVIDIA لا تزال لديها فجوة مع الخبراء الحقيقيين في نماذج التدريب. استخدمت NVIDIA نموذجًا جديدًا، Llama Nemotron، في GTC هذا، مع التركيز على الكفاءة والدقة. وهو مشتق من سلسلة نماذج Llama. بعد إجراء ضبط دقيق خاص بواسطة NVIDIA، تم تحسين هذا النموذج من خلال تقليم الخوارزمية وأصبح أخف وزناً من نموذج Llama الأصلي، حيث يزن 48 بايت فقط. كما أنها تتمتع بقدرات استدلالية مشابهة لـ o1. مثل Claude 3.7 و Grok 3، يحتوي نموذج Llama Nemotron على مفتاح قدرة استدلال مدمج يمكن للمستخدم اختيار تشغيله أو إيقاف تشغيله. تنقسم هذه السلسلة إلى ثلاثة مستويات: Nano للمبتدئين، وSuper للمتوسطين، وUltra الرائد، وكل منها يستهدف احتياجات الشركات ذات الأحجام المختلفة.
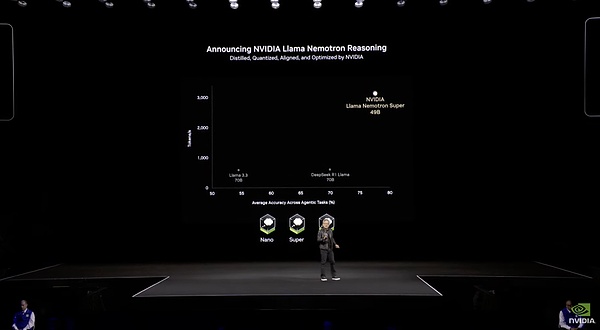
بيانات محددة عن Llama Nemotron
عند الحديث عن الكفاءة، تتكون مجموعة البيانات الدقيقة لهذا النموذج بالكامل من بيانات اصطناعية تم إنشاؤها بواسطة NVIDIA نفسها، بإجمالي حوالي 60B رمزًا. وبالمقارنة مع DeepSeek V3 الذي استغرق تدريبه بالكامل 1.3 مليون ساعة H100، فإن هذا النموذج، الذي يحتوي فقط على 1/15 من معلمات DeepSeek V3، استغرق 360,000 ساعة H100 فقط للضبط الدقيق. كفاءة التدريب أقل بمستوى واحد من DeepSeek. من حيث كفاءة الاستدلال، يُظهر طراز Llama Nemotron Super 49B أداءً أفضل بكثير من طراز الجيل السابق. يصل معدل نقل الرموز فيه إلى خمسة أضعاف معدل نقل الرموز في Llama 3 70B. ويمكنه، باستخدام وحدة معالجة رسومية واحدة لمركز بيانات، معالجة أكثر من 3000 رمز في الثانية. ولكن في البيانات الصادرة في اليوم الأخير من DeepSeek Open Source Day، كان لكل عقدة H800 معدل إنتاج متوسط يبلغ حوالي 73.7 ألف رمز/ثانية مدخلة (بما في ذلك عمليات الوصول إلى ذاكرة التخزين المؤقت) أثناء التعبئة المسبقة أو حوالي 14.8 ألف رمز/ثانية مخرجة أثناء فك التشفير. والفجوة بينهما لا تزال واضحة جدًا.
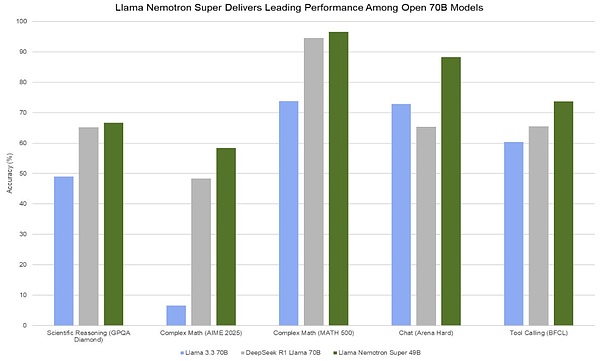
من حيث الأداء، يتفوق 49B Llama Nemotron Super على طراز 70B Llama 70B المقطر بواسطة DeepSeek R1 في جميع المؤشرات. ومع ذلك، بالنظر إلى الإصدار المتكرر مؤخرًا للنماذج ذات المعلمات الصغيرة وعالية الطاقة مثل نموذج Qwen QwQ 32B، فمن المتوقع أن يواجه Llama Nemotron Super صعوبة في التميز بين هذه النماذج التي يمكنها التنافس مع الجسم الرئيسي R1.
الأمر الأكثر خطورة هو أن هذا النموذج يثبت أن DeepSeek قد يعرف كيفية ضبط وحدة معالجة الرسوميات أثناء التدريب بشكل أفضل من NVIDIA. 3) النموذج الجديد هو مجرد مقبلات لنظام NVIDIA AI Agent البيئي، NVIDA AIQ هو الطبق الرئيسي. لماذا طورت NVIDIA نموذج استدلال؟ يأتي هذا بشكل أساسي للتحضير للنقطة المتفجرة التالية للذكاء الاصطناعي التي يركز عليها هوانج - وكيل الذكاء الاصطناعي. وبما أن OpenAI وClaude وشركات كبرى أخرى قامت تدريجياً بتأسيس Agent من خلال DeepReasearch وMCP، فمن الواضح أن NVIDIA تعتقد أن عصر Agent قد وصل.
مشروع NVIDA AIQ هو محاولة من NVIDIA. إنه يوفر بشكل مباشر سير عمل جاهزًا لوكيل الذكاء الاصطناعي للمخطط مع نموذج التفكير Llama Nemotron في جوهره. ينتمي هذا المشروع إلى مستوى Blueprint الخاص بـ NVIDIA، والذي يشير إلى مجموعة من سير العمل والقوالب المرجعية المعدة مسبقًا والتي تساعد المطورين على دمج تقنيات ومكتبات NVIDIA بسهولة أكبر. AIQ هو قالب الوكيل الذي توفره NVIDIA.
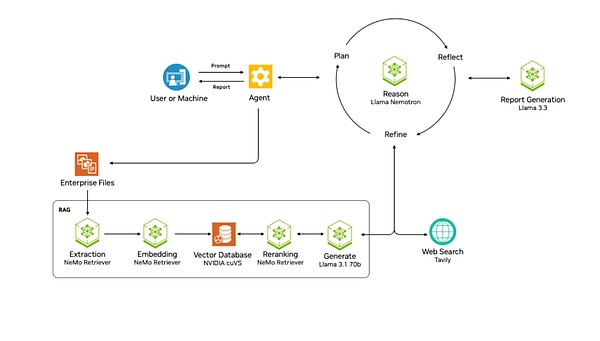
هندسة NVIDA AIQ
مثل Manus، فإنه يدمج أدوات خارجية مثل محركات البحث على الويب ووكلاء الذكاء الاصطناعي المحترفين الآخرين، مما يسمح للوكيل نفسه بالبحث واستخدام أدوات مختلفة. يخطط نموذج التفكير الخاص بـ Llama Nemotron ويعكس ويحسن حلول المعالجة لإكمال مهام المستخدم. بالإضافة إلى ذلك، فهو يدعم أيضًا إنشاء بنية سير عمل متعددة الوكلاء.
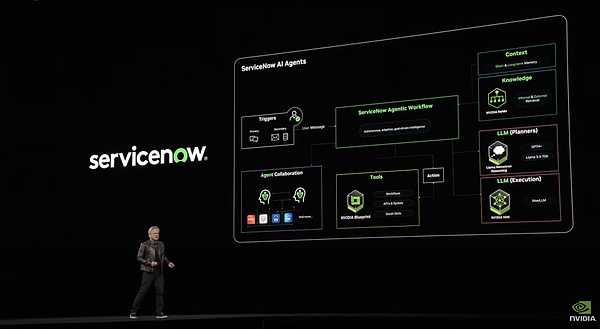
نظام servicenow يعتمد على هذا القالب
يتقدم النظام خطوة واحدة إلى الأمام عن نظام Manus، حيث يحتوي على نظام RAG معقد للملفات المؤسسية. يتضمن هذا النظام سلسلة من الخطوات بما في ذلك الاستخراج والتضمين وتخزين المتجهات وإعادة الترتيب والمعالجة النهائية من خلال LLM، مما يضمن إمكانية استخدام بيانات المؤسسة بواسطة Agent. بالإضافة إلى ذلك، أطلقت NVIDIA أيضًا منصة بيانات الذكاء الاصطناعي لربط نموذج التفكير بالذكاء الاصطناعي بنظام بيانات المؤسسة لتشكيل بحث عميق لبيانات المؤسسة. وقد أدى هذا إلى تطور كبير في تكنولوجيا التخزين، مما جعل أنظمة التخزين لم تعد مجرد مستودعات بيانات، بل أصبحت منصات ذكية ذات قدرات تحليل واستدلال نشطة.
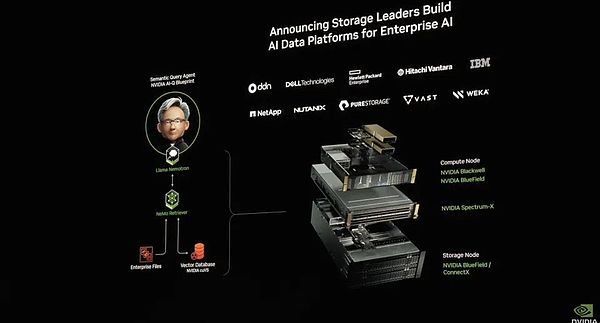
تركيبة منصة بيانات الذكاء الاصطناعي
بالإضافة إلى ذلك، تولي AIQ أهمية كبيرة لآليات المراقبة والشفافية. وهذا مهم جدًا للسلامة والتحسينات اللاحقة. يمكن لفريق التطوير مراقبة أنشطة الوكيل في الوقت الفعلي وتحسين النظام بشكل مستمر استنادًا إلى بيانات الأداء. بشكل عام، يعد NVIDA AIQ قالب سير عمل وكيل قياسي يوفر إمكانيات وكيل مختلفة. إنه برنامج إنشاء وكيل يشبه Dify والذي تطور إلى عصر التفكير وأصبح أكثر أمانًا. تم إصدار النموذج الأساسي للروبوت الشبيه بالإنسان. تهدف إنفيديا إلى بناء حلقة مغلقة تمامًا من البيئة المجسدة.
1) كوزموس، مما يسمح للذكاء المتجسد بفهم العالم.
إذا كان التركيز على العميل لا يزال استثمارًا في الحاضر، فإن تصميم إنفيديا للذكاء المتجسد يمكن اعتباره دمجًا للمستقبل.
قامت شركة NVIDIA بترتيب العناصر الثلاثة للنموذج: النموذج والبيانات وقوة الحوسبة. لنبدأ بالنموذج. أصدرت هذه الشركة نسخةً مُحسّنةً من نموذج الذكاء المُجسّد الأساسي "كوزموس" الذي أُعلن عنه في يناير من هذا العام.
Cosmos هو نموذج يمكنه التنبؤ بالصور المستقبلية من خلال الصور الحالية. يمكنه أخذ بيانات الإدخال من النصوص/الصور، وإنشاء مقاطع فيديو مفصلة، والتنبؤ بتطور المشهد من خلال الجمع بين حالته الحالية (الصورة/الفيديو) مع الإجراءات (الإشارات/إشارات التحكم). نظرًا لأن هذا يتطلب فهم القوانين السببية الفيزيائية للعالم، أطلقت Nvidia على Cosmos اسم النموذج الأساسي العالمي (WFM).
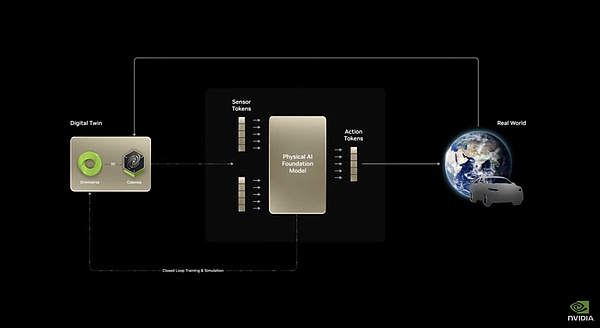
الهندسة المعمارية الأساسية لكوزموس
بالنسبة للذكاء المتجسد، فإن التنبؤ بتأثير سلوك الآلة على العالم الخارجي هو القدرة الأكثر جوهرية. بهذه الطريقة فقط يمكن للنموذج التخطيط للسلوك بناءً على التوقعات، وبالتالي يصبح نموذج العالم هو النموذج الأساسي للذكاء المجسد. باستخدام هذا النموذج الأساسي للتنبؤ بتغير العالم من حيث السلوك/الزمن والطبيعة، ومن خلال ضبط مجموعات بيانات محددة مثل القيادة الذاتية والمهام الروبوتية، يمكن لهذا النموذج تلبية احتياجات التنفيذ العملي لمختلف الذكاء المتجسد بأشكال مادية. يتكون النموذج بأكمله من ثلاث قدرات. الأول، Cosmos Transfer، يُحوّل نص الفيديو المُدخل إلى مُخرج فيديو واقعي قابل للتحكم، مُولّدًا بيانات تركيبية واسعة النطاق من العدم باستخدام النص. وهذا يحل أكبر مشكلة تواجه الذكاء المجسد اليوم - مشكلة عدم كفاية البيانات. علاوة على ذلك، فإن هذا الجيل هو جيل "قابل للتحكم"، مما يعني أنه يمكن للمستخدمين تحديد معلمات محددة (مثل الظروف الجوية، وخصائص الكائن، وما إلى ذلك)، وسوف يقوم النموذج بتعديل نتائج الجيل وفقًا لذلك، مما يجعل عملية توليد البيانات أكثر قابلية للتحكم واستهدافًا. يمكن أيضًا دمج العملية بأكملها مع Ominiverse و Cosmos.

Cosmos عبارة عن محاكاة للواقع مبنية على Ominiverse
الجزء الثاني، Cosmos Predict، يمكنه إنشاء حالات العالم الافتراضي من مدخلات متعددة الوسائط، مما يدعم إنشاء إطارات متعددة والتنبؤ بمسار العمل. وهذا يعني أنه في ظل حالة بداية ونهاية، يمكن للنموذج أن يولد عمليات وسيطة معقولة. هذه هي القدرة الأساسية لفهم وبناء العالم المادي. الجزء الثالث هو "Cosmos Reason"، وهو نموذج مفتوح وقابل للتخصيص بالكامل مع قدرات إدراك مكاني زماني. يفهم بيانات الفيديو من خلال تحليل سلسلة الأفكار، ويتنبأ بنتائج التفاعل. وهي القدرة المحسنة على التخطيط للإجراءات والتنبؤ بنتائجها.
من خلال الإضافة التدريجية لهذه القدرات الثلاث، يمكن لبرنامج Cosmos تحقيق سلسلة سلوكية كاملة من رمز الصورة الحقيقية + رمز موجه الأوامر النصية المدخل إلى إخراج رمز إجراء الجهاز. يجب أن يعمل هذا النموذج الأساسي بشكل جيد حقًا. وبعد شهرين فقط من إطلاقه، بدأت ثلاث شركات رائدة، وهي 1X، وAgility Robotics، وFigure AI، في استخدامه. إن شركة NVIDIA لا تقود في مجال نماذج اللغة الكبيرة، ولكن من حيث الذكاء المجسد، فهي بالفعل في المستوى الأول. 2) Isaac GR00T N1، أول نموذج أساسي في العالم للروبوتات الشبيهة بالبشر
باستخدام Cosmos، استخدمت NVIDIA هذا الإطار بشكل طبيعي لضبط وتدريب Isaac GR00T N1، وهو نموذج أساسي مخصص للروبوتات الشبيهة بالبشر.
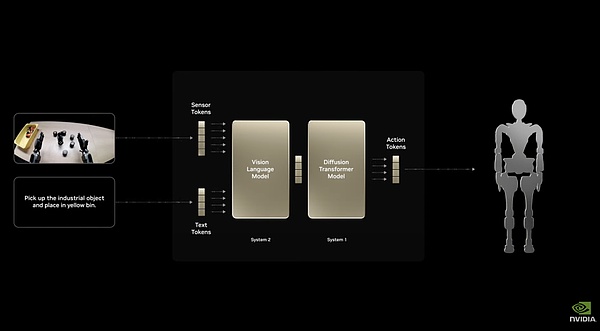
هندسة النظام المزدوج لجهاز Isaac GR00T N1
يعتمد على هندسة النظام المزدوج، مع استجابة سريعة "النظام 1" واستدلال عميق "النظام 2". يتيح لها الضبط الدقيق الشامل التعامل مع المهام الشائعة مثل الإمساك والتحريك والتلاعب بالذراعين المزدوجتين. ويمكن أيضًا تخصيصه بالكامل لروبوت محدد، ويمكن لمطوري الروبوت استخدام بيانات حقيقية أو اصطناعية للتدريب اللاحق. وهذا يسمح بنشر النموذج في جميع أنواع الروبوتات ذات الأشكال المختلفة تقريبًا. على سبيل المثال، قامت شركة Nvidia، بالتعاون مع Google DeepMind وDisney لتطوير محرك الفيزياء Newton، باستخدام Isaac GR00T N1 كقاعدة لتشغيل روبوت Disney BDX الصغير غير العادي للغاية. وهذا يظهر مدى تنوعها. نيوتن هو محرك فيزيائي مفصل للغاية، لذا يكفي بناء نظام مكافأة مادي لتدريب الذكاء المجسد في بيئة افتراضية.

تفاعل هوانغ رينكسون "بشغف" مع روبوت BDX على المسرح
4) توليد البيانات، نهج مزدوج
قامت NVIDIA بدمج NVIDIA Omniverse ونموذج القاعدة العالمية NVIDIA Cosmos Transfer المذكور أعلاه لإنشاء مخطط Isaac GR00T. يمكنه توليد كميات كبيرة من بيانات الحركة الاصطناعية من كمية صغيرة من المظاهرات البشرية لتدريب الروبوت على التعامل مع الروبوت. وباستخدام المكونات الأولى لـ Blueprint، تمكنت NVIDIA من إنشاء 780,000 مسار اصطناعي في 11 ساعة فقط، وهو ما يعادل 6,500 ساعة (حوالي تسعة أشهر) من بيانات العرض البشري. يأتي جزء كبير من البيانات الخاصة بـ Isaac GR00T N1 من هذا، مما يحسن أداء GR00T N1 بنسبة 40% مقارنة باستخدام البيانات الحقيقية فقط.

نظام محاكاة مزدوج
بالنسبة لكل نموذج، يمكن لشركة NVIDIA توفير كمية كبيرة من البيانات عالية الجودة من خلال نظام Omniverse الافتراضي الخالص ونظام توليد الصور في العالم الحقيقي Cosmos Transfer. وتغطي Nvidia أيضًا الجانب الثاني من هذا النموذج. 3) نظام حوسبة ثلاثة في واحد لبناء إمبراطورية حوسبة روبوتية من التدريب إلى النهاية منذ العام الماضي، أكد هوانج على مفهوم "ثلاثة أجهزة كمبيوتر" في GTC: الأول هو DGX، وهو خادم GPU كبير، والذي يستخدم لتدريب الذكاء الاصطناعي، بما في ذلك الذكاء المتجسد. أما AGX الأخرى فهي منصة حوسبة مدمجة صممتها NVIDIA للحوسبة الطرفية والأنظمة ذاتية التشغيل. تُستخدم لنشر الذكاء الاصطناعي على الحافة، مثل الشريحة الأساسية للقيادة الذاتية أو الروبوتات. والثالث هو الكمبيوتر المولد للبيانات Omniverse+Cosmos. ثلاثة أنظمة حوسبة رئيسية للذكاء المتجسد ذكر هذا النظام مرة أخرى من قبل هوانغ في هذه الدورة التدريبية العامة، وذكر على وجه التحديد أنه باستخدام نظام الحوسبة هذا، يمكن ولادة مليارات الروبوتات. من التدريب إلى النشر، يتم استخدام NVIDIA لقوة الحوسبة. هذا الجزء مغلق أيضاً
الخلاصة
إذا قارناه ببساطة بشريحة بلاك ويل من الجيل السابق، فإن مكونات بلاك ويل ألترا لا تتطابق مع الصفات السابقة مثل "القنبلة النووية" و"القنبلة الملكية"، بل إنها تشبه إلى حد ما عصر معجون الأسنان. ومع ذلك، من منظور تخطيط خارطة الطريق، فإن كل هذه الأمور تقع ضمن تصميم هوانغ رينكسون. في العامين المقبلين، والعام الذي يليه، ستشهد بنية روبين تحسينات كبيرة في تكنولوجيا الرقائق، والترانزستورات، وتكامل الرفوف، وربط وحدات معالجة الرسومات، وربط الخزائن. وكما يقول الصينيون، "الأفضل لم يأتِ بعد".
بالمقارنة مع الوعود الفارغة على مستوى الأجهزة، فقد حققت شركة Nvidia تقدماً سريعاً على مستوى البرامج في العامين الماضيين.
عند النظر إلى النظام البيئي الكامل للبرمجيات الخاص بشركة NVIDIA، فإن مستويات الخدمات الثلاثة، Meno وNim وBlueprint، تتضمن حلولاً متكاملة من تحسين النموذج وتغليف النموذج إلى إنشاء التطبيق. تتداخل المجالات البيئية لشركات الخدمات السحابية و NVIDIA AI. مع إضافة Agent، AI infra، ترغب NVIDIA في الاستحواذ على جميع الأجزاء باستثناء النموذج الأساسي.
عندما يتعلق الأمر بالبرمجيات، فإن شهية هوانغ كبيرة مثل سعر سهم شركة إنفيديا. وفي سوق الروبوتات، لدى شركة Nvidia طموحات أعظم. العناصر الثلاثة: النموذج، والبيانات، وقوة الحوسبة، كلها في أيدينا. لقد فشلت في اللحاق بالمركز الأول في نمذجة اللغة الأساسية، ولكن تم تعويضها بالذكاء المجسد الأساسي. وفي الظل، برز عملاق احتكار ذكي متجسد في الأفق.
هنا، كل رابط وكل منتج يتوافق مع سوق محتملة تبلغ قيمتها مئات المليارات من اليوان. هوانغ رينكسون، ملك القمار المحظوظ الذي قام بالمقامرة بكل شيء في سنواته الأولى، بدأ مقامرة أكبر بالأموال التي حصل عليها من احتكار وحدة معالجة الرسومات. إذا فازت شركة إنفيديا إما في سوق البرمجيات أو الروبوتات في هذه المقامرة، فإنها سوف تصبح بمثابة جوجل عصر الذكاء الاصطناعي، أي المحتكر الأكبر في سلسلة الغذاء. ومع ذلك، بالنظر إلى هوامش الربح الخاصة بوحدات معالجة الرسوميات الخاصة بشركة Nvidia، فإننا لا نزال نأمل ألا يأتي مثل هذا المستقبل. ولحسن الحظ، هذه هي أكبر مخاطرة لم يقدم عليها لاو هوانغ في حياته على الإطلاق، والنتيجة غير متوقعة.


 Joy
Joy



