المصدر: Machine Heart
بعد الإعلان المفاجئ عن نهاية تعاونها مع OpenAI في فبراير، كشفت شركة الروبوتات الناشئة الشهيرة Figure AI عن السبب وراء ذلك مساء الخميس: لقد قاموا بإنشاء نموذج الذكاء الاصطناعي العام الخاص بهم Helix.

Helix هو نموذج عام للرؤية واللغة والفعل (VLA) يوحد الإدراك وفهم اللغة والتحكم المكتسب للتغلب على العديد من التحديات طويلة الأمد في مجال الروبوتات.
لقد أنشأت Helix العديد من الأوليات:
-
التحكم الكامل في الجسم: إنه أول نموذج مستمر سريع السرعة في الجسد العلوي من الروبوت البشري في التاريخ ، مع تعاونه يسأل ؛ ؛
-
الترجمة: Helix هو أول نموذج روبوت VLA في التاريخ الذي يعمل على وحدة معالجة الرسومات المحلية ، ولديه القدرة على التجسيد.
في مجال القيادة الذكية، تعمل جميع شركات تصنيع السيارات على تعزيز التنفيذ واسع النطاق للتكنولوجيا الشاملة هذا العام. والآن دخلت الروبوتات التي تعمل بتقنية VLA أيضًا العد التنازلي للتسويق. وبهذه الطريقة، يمكن اعتبار Helix بمثابة اختراق كبير في مجال الذكاء المجسد.
تعمل مجموعة من أوزان الشبكة العصبية Helix في وقت واحد على روبوتين يعملان معًا لوضع عناصر البقالة التي لم يسبق لهما رؤيتها من قبل.
إضافات جديدة للروبوتات الشبيهة بالبشر
قال فيجر إن بيئة المنزل هي التحدي الأكبر الذي يواجه الروبوتات. على عكس البيئة الصناعية الخاضعة للرقابة، فإن المنزل مليء بعدد لا يحصى من الأشياء غير المنتظمة، مثل الأواني الزجاجية الهشة، والملابس المجعدة، والألعاب المتناثرة، ولكل منها أشكال وأحجام وألوان وملمس غير متوقعة. لكي تكون الروبوتات مفيدة في المنزل، يجب أن تكون قادرة على توليد سلوكيات ذكية جديدة عند الطلب.
إن تكنولوجيا الروبوتات الحالية غير قابلة للتوسع في البيئات المنزلية - في الوقت الحالي، يتطلب تعليم الروبوت حتى سلوكًا جديدًا واحدًا تدخلًا بشريًا كبيرًا. سيتطلب ذلك إما ساعات من البرمجة اليدوية من قبل خبراء على مستوى الدكتوراه أو آلاف العروض التوضيحية، وكلاهما باهظ التكلفة للغاية. الشكل 1: منحنيات التمديد للطرق المختلفة لاكتساب مهارات الروبوت الجديدة. في العمليات الاستدلالية التقليدية، يعتمد نمو المهارات على قيام الخبراء بكتابة البرامج النصية يدويًا. في التعلم التقليدي من خلال تقليد الروبوتات، يعتمد توسيع المهارات على البيانات التي يتم جمعها. مع Helix، يمكن تحديد مهارات جديدة أثناء التنقل من خلال اللغة.
حاليًا، أتقنت مجالات أخرى من الذكاء الاصطناعي بالفعل هذه القدرة على التعميم الفوري. إذا كان من الممكن تحويل المعرفة الدلالية الغنية الملتقطة في نموذج الرؤية واللغة (VLM) ببساطة إلى تصرفات الروبوت، فقد نتمكن من تحقيق تقدم تكنولوجي.
ستؤدي هذه القدرة الجديدة إلى تغيير مسار التوسع في مجال الروبوتات بشكل جذري (الشكل 1). السؤال الرئيسي هنا يصبح: كيف يمكننا استخراج كل هذه المعرفة السليمة من VLM وتحويلها إلى تحكم عام في الروبوت؟ تم بناء الشكل الحلزوني لسد هذه الفجوة.
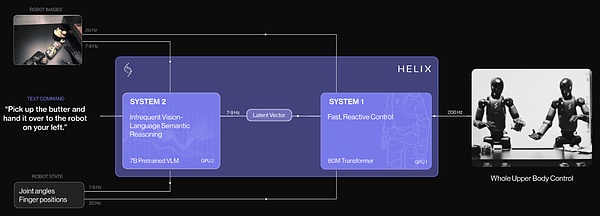
Helix: أول نموذج VLA لنظام 1 + نظام 2 الروبوتي
Helix هو أول نموذج VLA "نظام 1 + نظام 2" في مجال الروبوتات، ويُستخدم للتحكم في الجزء العلوي بالكامل من جسم الروبوت البشري بسرعة عالية وبراعة.
يوضح الشكل أن الأساليب السابقة تواجه مقايضة أساسية: فالهياكل الأساسية للمحرك البصري الحركي عامة ولكنها ليست سريعة، في حين أن السياسات البصرية الحركية الروبوتية سريعة ولكنها ليست عامة بما فيه الكفاية. يعالج Helix هذه المقايضة من خلال نظامين متكاملين تم تدريبهما من البداية إلى النهاية للتواصل:
النظام 1 (S1): سياسة حركية بصرية سريعة المفعول تحول التمثيلات الدلالية الكامنة التي ينتجها S2 إلى أفعال روبوتية مستمرة دقيقة عند 200 هرتز؛
النظام 2 (S2): VLM مدرب مسبقًا على الإنترنت يعمل على تردد 7-9 هرتز لفهم المشهد وفهم اللغة، وتحقيق تعميم واسع عبر الكائنات والسياقات.
تسمح هذه البنية المنفصلة لكل نظام بالعمل على الإطار الزمني الأمثل له. يمكن لـ S2 "التفكير ببطء" حول الأهداف عالية المستوى، بينما يمكن لـ S1 "التفكير بسرعة" حول الإجراءات التي ينفذها الروبوت ويعدلها في الوقت الفعلي. على سبيل المثال، في السلوك التعاوني (انظر الشكل أدناه)، يمكن لـ S1 التكيف بسرعة مع الحركات المتغيرة لروبوت الشريك مع الحفاظ على الأهداف الدلالية لـ S2. يتيح Helix للروبوت إجراء تعديلات حركية دقيقة بسرعة، وهي ضرورية للاستجابة للشركاء المتعاونين عند تنفيذ أهداف دلالية جديدة.
يتميز تصميم Helix بالعديد من المزايا الرئيسية مقارنة بالطرق الحالية:
السرعة والتعميم: يضاهي Helix في سرعته استراتيجيات الاستنساخ السلوكي المتخصصة لمهمة واحدة، مع القدرة على التعميم على آلاف الموضوعات الاختبارية الجديدة بتنبؤات بدون أخطاء؛
قابلية التوسع: ينتج Helix تحكمًا مستمرًا مباشرة في مساحة عمل عالية الأبعاد، متجنبًا مخططات رمزية العمل المعقدة المستخدمة في طرق VLA السابقة. أظهرت هذه المخططات بعض النجاح في إعدادات التحكم منخفضة الأبعاد (على سبيل المثال، المقابض الثنائية المتوازية)، ولكنها تواجه تحديات التوسع في التحكم البشري عالي الأبعاد؛
البساطة المعمارية: يستخدم Helix بنية قياسية - VLM مفتوح المصدر ومفتوح الوزن للنظام 2، وسياسة بصرية حركية بسيطة تعتمد على المحول للنظام 1؛
فصل الاهتمامات: يتيح لنا فصل S1 وS2 تكرار كل نظام على حدة دون تقييدنا بإيجاد مساحة ملاحظة موحدة أو تمثيل عمل.
يقدم الشكل بعض تفاصيل النموذج والتدريب، والذي يجمع مجموعة بيانات عالية الجودة ومتعددة الروبوتات ومتعددة المشغلين وسلوك التشغيل عن بعد المتنوع، والتي يبلغ مجموعها حوالي 500 ساعة. لتوليد أزواج تدريبية باللغة الطبيعية، استخدم المهندسون نموذج لغة بصرية مُشرح تلقائيًا (VLM) لتوليد تعليمات لاحقة.
يتم معالجة مقاطع فيديو مجزأة من الكاميرا الموجودة على متن الروبوت بواسطة VLM ويتم توجيه السؤال التالي: "ما هي التعليمات التي ستقدمها للروبوت لجعله يقوم بالإجراء الذي يراه في الفيديو؟" تم استبعاد جميع الكائنات التي تمت معالجتها أثناء التدريب من التقييم لمنع تلوث البيانات.
هندسة النموذج
يتكون نظام Helix من عنصرين رئيسيين: S2، شبكة العمود الفقري VLM؛ S1، محول الحركة البصرية الشرطية الكامنة. تم بناء S2 على VLM مفتوح المصدر ومفتوح الوزن يحتوي على 7 مليار معلمة تم تدريبها مسبقًا على بيانات على نطاق الإنترنت. يقوم بمعالجة صور الروبوت أحادية العين ومعلومات حالة الروبوت (بما في ذلك وضع المعصم ومواضع الأصابع) ويعرضها في مساحة تضمين اللغة والرؤية. بدمج تعليمات اللغة الطبيعية التي تحدد السلوك المطلوب، يقوم S2 بتقطير جميع المعلومات الدلالية المتعلقة بالمهمة إلى متجه كامن مستمر، والذي يتم تمريره إلى S1 لتنظيم أفعاله منخفضة المستوى.
S1 هو محول تشفير وفك تشفير ذو 80 مليون معلمة مسؤول عن التحكم على المستوى المنخفض. إنه يعتمد على شبكة أساسية للرؤية متعددة المقاييس ملتوية بالكامل للمعالجة البصرية، والتي يتم تهيئتها بالكامل من التدريب المسبق في المحاكاة. بينما يستقبل S1 نفس الصورة ومدخلات الحالة مثل S2، فإنه يعالج هذه المدخلات بتردد أعلى للتحكم في الحلقة المغلقة بشكل أكثر استجابة. يتم إسقاط المتجهات الكامنة من S2 في مساحة العلامة الخاصة بـ S1 وتسلسلها على طول البعد التسلسلي باستخدام الميزات المرئية المستخرجة بواسطة شبكة العمود الفقري المرئي S1، مما يوفر تكييف المهمة.
عند التشغيل، يصدر S1 تحكمًا بشريًا كاملاً في الجزء العلوي من الجسم بتردد 200 هرتز، بما في ذلك وضع الرسغ المطلوب، وثني الأصابع والتحكم في الاختطاف، وأهداف توجيه الجذع والرأس. يضيف الشكل إجراءً اصطناعيًا "لنسبة إكمال المهمة" إلى مساحة الإجراء، مما يسمح لـ Helix بالتنبؤ بحالة الإنهاء الخاصة به، مما يجعل من الأسهل تسلسل السلوكيات المتعددة المكتسبة.
التدريب
يتم تدريب Helix بالكامل من البداية إلى النهاية: من وحدات البكسل الخام وأوامر النص إلى الإجراءات المستمرة مع خسارة الانحدار القياسية.
يمتد مسار الانتشار الخلفي للتدرج من S1 إلى S2 عبر متجه الاتصال الضمني المستخدم لتنظيم سلوك S1، مما يسمح بتحسين المكونين بشكل مشترك. لا يحتاج Helix إلى الضبط لمهمة محددة؛ فهو يحافظ على مرحلة تدريب واحدة ومجموعة من أوزان الشبكة العصبية، دون الحاجة إلى رؤوس عمل منفصلة أو مراحل ضبط دقيقة لكل مهمة.
أثناء التدريب، يقومون أيضًا بإضافة إزاحة زمنية بين المدخلات S1 وS2. تم معايرة هذا الإزاحة لمطابقة الفجوة بين أوقات استدلال النشر S1 وS2، مما يضمن أن متطلبات التحكم في الوقت الفعلي أثناء النشر تنعكس بدقة في التدريب.
استدلال البث المحسن
يتيح تصميم تدريب Helix النشر المتوازي الفعال للنماذج على روبوتات Figure، حيث تم تجهيز كل منها بوحدتي معالجة رسوميات مدمجتين منخفضتي الطاقة. يتم تقسيم خط أنابيب الاستدلال إلى نموذجي S2 (التخطيط الضمني عالي المستوى) وS1 (التحكم منخفض المستوى)، حيث يعمل كل منهما على وحدة معالجة رسومية مخصصة.
يتم تشغيل S2 كعملية خلفية غير متزامنة لمعالجة أحدث الملاحظات (الكاميرا الموجودة على متن الطائرة وحالة الروبوت) وأوامر اللغة الطبيعية. يقوم بشكل مستمر بتحديث متجه كامن للذاكرة المشتركة والذي يقوم بتشفير النوايا السلوكية عالية المستوى.
يتم تنفيذ S1 كعملية منفصلة في الوقت الفعلي بهدف الحفاظ على حلقة التحكم البالغة 200 هرتز المطلوبة للتنفيذ السلس لحركة الجزء العلوي من الجسم بالكامل. مدخلاتها هي أحدث ملاحظة وأحدث متجه كامن S2. وبسبب الاختلاف الجوهري في السرعة بين المنطق S2 والمنطق S1، يعمل S1 بشكل طبيعي بدقة زمنية أعلى في ملاحظات الروبوت، مما يخلق حلقة تغذية مرتدة أكثر إحكامًا للتحكم التفاعلي.
تعكس استراتيجية النشر هذه عمدًا الإزاحة الزمنية المقدمة في التدريب، وبالتالي تقليل فجوة توزيع التدريب والاستدلال. يتيح نموذج التنفيذ غير المتزامن هذا لكلا العمليتين العمل بتردداتهما المثلى الخاصة بهما، مما يسمح لـ Helix بالعمل بنفس سرعة سياسة التعلم التقليدى الأسرع لمهمة واحدة.
ومن المثير للاهتمام أنه بعد إصدار Figure لـ Helix، قال يانجيانج جو، وهو طالب دكتوراه في جامعة تسينغهوا، إن أفكاره التقنية تشبه إلى حد كبير إحدى أوراقهم البحثية في مؤتمر CoRL 2024، والتي يمكن للقراء المهتمين أيضًا الرجوع إليها للقراءة.

عنوان الورقة: https://arxiv.org/abs/2410.05273
النتائج
التحكم الدقيق في الجزء العلوي من الجسم باستخدام VLA
يمكن لـ Helix تنسيق مساحة عمل تبلغ 35 درجة من الحرية بتردد 200 هرتز، والتحكم في كل شيء بدءًا من حركات الأصابع الفردية إلى مسار الطرف المؤثر، ونظرة الرأس، ووضعية الجذع.
يمثل التحكم في الرأس والجذع تحديات فريدة من نوعها - عندما يتحرك الرأس والجذع، فإنه يغير ما يمكن للروبوت الوصول إليه ورؤيته، مما يخلق حلقات تغذية مرتدة تسببت في عدم الاستقرار في الماضي.
يوضح الفيديو 3 هذا التنسيق أثناء العمل: حيث يتتبع الروبوت يديه بسلاسة باستخدام رأسه أثناء ضبط جذعه للوصول الأمثل مع الحفاظ على التحكم الدقيق في الأصابع للإمساك. في السابق، كان من الصعب تحقيق هذا المستوى من الدقة في مثل هذه المساحة العملية عالية الأبعاد، حتى بالنسبة لمهمة واحدة معروفة. يشير الشكل إلى أنه لم يتمكن أي نظام VLA سابق من إظهار هذا المستوى من التنسيق في الوقت الفعلي مع الحفاظ على القدرة على التعميم عبر المهام والأشياء.

يمكن لـ VLA من Helix التحكم في الجزء العلوي بالكامل من جسم الروبوت الشبيه بالإنسان. وهذا هو النموذج الأول في مجال تعلم الروبوتات الذي يحقق ذلك.
التعاون بين الروبوتات المتعددة بدون إطلاق
قالت شركة Figure إنهم دفعوا Helix إلى أقصى حدوده في سيناريو تشغيلي صعب متعدد الوكلاء: تعاون روبوتان من Figure لتحقيق تخزين البقالة بدون إطلاق.
يظهر الفيديو 1 تقدمين أساسيين: حيث يتعامل كلا الروبوتين بنجاح مع حمولة جديدة (عناصر لم يتم مواجهتها مطلقًا أثناء التدريب)، مما يوضح التعميم القوي لمجموعة واسعة من الأشكال والأحجام والمواد.
بالإضافة إلى ذلك، يعمل كلا الروبوتين باستخدام نفس أوزان نموذج Helix، ولا يتطلبان تدريبًا محددًا لالروبوت أو تعيينات أدوار صريحة. ويتم تحقيق تعاونهم من خلال مطالبات اللغة الطبيعية، مثل "مرر كيس البسكويت إلى الروبوت على يمينك" أو "خذ كيس البسكويت من الروبوت على يسارك وضعه في الدرج المفتوح" (انظر الفيديو 4). هذه هي المرة الأولى التي يتم فيها استخدام VLA لإظهار العمليات التعاونية المرنة والقابلة للتطوير بين الروبوتات المتعددة. ويعد هذا الإنجاز ملحوظًا بشكل خاص نظرًا لأنهم تمكنوا بنجاح من معالجة أشياء جديدة تمامًا.

يتيح Helix التعاون الدقيق بين الروبوتات المتعددة
تظهر القدرة على "التقاط أي شيء"


بمجرد أمر "التقاط [X]"، يمكن لروبوت Figure المجهز بـ Helix التقاط أي شيء منزلي صغير. وفي اختبار منهجي، دون أي عرض توضيحي مسبق أو برمجة مخصصة، تمكن الروبوت من التعامل بنجاح مع آلاف الأشياء الجديدة في بيئة مزدحمة - من الأواني الزجاجية والألعاب إلى الأدوات والملابس. ومن الجدير بالذكر أن Helix يمكنه بناء اتصال بين فهم اللغة على نطاق الإنترنت والتحكم الدقيق في الروبوتات. على سبيل المثال، عندما طُلب من Helix "التقاط شيء صحراوي"، لم يحدد فقط أن صبار لعبة يطابق هذا المفهوم المجرد، بل حدد أيضًا اليد الأقرب وكان قادرًا على الإمساك بها بأمان باستخدام أوامر حركية دقيقة.
قال الشكل: "إن هذه القدرة العالمية على استيعاب "اللغة إلى الفعل" تفتح إمكانيات جديدة ومثيرة لنشر الروبوتات الشبيهة بالبشر في بيئات غير منظمة."

يمكن لـ Helix ترجمة التعليمات عالية المستوى مثل "التقط [X]" إلى إجراءات منخفضة المستوى.
المناقشة
Helix فعال للتدريب
يحقق Helix تعميمًا قويًا للأشياء باستخدام عدد قليل جدًا من الموارد. يقول الشكل: "نحن نستخدم ما مجموعه حوالي 500 ساعة من البيانات الخاضعة للإشراف عالية الجودة لتدريب Helix، وهو جزء صغير فقط (<5%) من مجموعة بيانات VLA التي تم جمعها مسبقًا ولا تعتمد على مجموعة مجسدة من الروبوتات المتعددة أو مراحل تدريب متعددة." ويشيرون إلى أن حجم المجموعة هذا أقرب إلى مجموعات بيانات التعلم التقليدي الحديثة ذات المهمة الواحدة. وعلى الرغم من متطلبات البيانات الصغيرة نسبيًا، يمكن توسيع نطاق Helix ليشمل مساحة عمل أكثر تحديًا، أي التحكم الكامل في الجزء العلوي من الجسم البشري، مع مخرجات عالية السرعة وعالية الأبعاد.
مجموعة واحدة من الأوزان
تتطلب أنظمة VLA الحالية عادةً ضبطًا دقيقًا متخصصًا أو رؤوس عمل مخصصة لتحسين أداء تنفيذ سلوكيات عالية المستوى مختلفة. ومن المثير للدهشة أن Helix يمكنه تنفيذ إجراءات مثل التقاط العناصر ووضعها في حاويات مختلفة، وتشغيل الأدراج والثلاجات، وتنسيق عمليات التسليم البارعة بين الروبوتات المتعددة، والتلاعب بآلاف الكائنات الجديدة باستخدام مجموعة واحدة فقط من أوزان الشبكة العصبية (7B للنظام 2 و80M للنظام 1).

"التقط Helix" (Helix تعني الحلزون)
الملخص
Helix هو أول نموذج "رؤية ولغة وفعل" يتحكم بشكل مباشر في الجزء العلوي بالكامل من جسم الروبوت البشري من خلال اللغة الطبيعية. على عكس الأنظمة الروبوتية السابقة، فإن Helix قادر على إنشاء معالجة طويلة المدى وتعاونية وبارعة على الفور دون الحاجة إلى أي عرض توضيحي محدد للمهمة أو برمجة يدوية مكثفة. أظهر Helix قدرة قوية على تعميم الأشياء، حيث كان قادرًا على التقاط آلاف العناصر المنزلية الجديدة ذات الأشكال والأحجام والألوان وخصائص المواد المختلفة التي لم يسبق له مواجهتها أثناء التدريب، وذلك ببساطة باستخدام أوامر اللغة الطبيعية. وقالت الشركة: "يمثل هذا خطوة تحويلية لشركة Figure في توسيع سلوكيات الروبوتات الشبيهة بالبشر - وهي خطوة نعتقد أنها ستكون حاسمة مع مساعدة روبوتاتنا بشكل متزايد في البيئات المنزلية اليومية". وفي حين أن هذه النتائج المبكرة مثيرة بالتأكيد، إلا أن ما رأيناه أعلاه لا يزال بشكل عام بمثابة دليل على المفهوم الذي يظهر فقط ما هو ممكن. إن الثورة الحقيقية سوف تأتي عندما يتم نشر Helix فعليًا على نطاق واسع. نتطلع إلى أن يأتي ذلك اليوم عاجلا!
وأخيرًا، قد يكون إصدار Figure مجرد خطوة صغيرة في سلسلة الإنجازات العديدة في مجال الذكاء المجسد هذا العام. وفي وقت مبكر من هذا الصباح، أعلنت شركة 1X Robotics رسميًا أيضًا أنها ستطلق منتجًا جديدًا قريبًا.


 Weatherly
Weatherly